










Kubernetes Pod 的可观测性与智能告警

引言
Kubernetes 帮助用户自动调度和扩展容器化应用程序,但现代 Kubernetes 环境正变得越来越复杂,当平台和应用工程师需要调查动态、容器化环境中的事件时,寻找最有意义的信号可能涉及许多试错步骤。而Kubernetes Pod 作为Kubernetes 核心资源对象,不仅 Service、Controller、Workload 都是围绕它展开工作。作为最小调度单元的它,还担任着传统 IT 环境主机的职责,包含了调度,网络,存储,安全等能力。正是因为 Pod 具有复杂的生命周期和依赖,绝大多数 Kubernetes 问题最终都会在 Pod 上表现出来。通过 Kubernetes Pod 的智能巡检可以根据事件报告加快事件调查、减轻工程师的压力、减少平均修复时间并改善最终用户体验。
异常情况定位原因困难
- 因为资源不足、无法调度、镜像拉取失败、磁盘挂载失败、运行时程序崩溃等原因就绪失败,即 Pod 一直无法到达 Ready 状态,无法接收请求进行业务处理。
- 虽然 Kubernetes 提供了很多自愈的能力,但是 Pod 频繁重启依旧是不能忽视的问题,当程序异常退出、非法地址访问等原因引起程序重启等。
- 由于请求量突增,程序自身可能触发流控或者其他异常处理导致重启,或者由于资源不足(磁盘,内存),请求处理包含磁盘的写操作,资源不足出现失败;外部依赖服务报错,请求处理需要调用下游服务报错引发请求处理失败导致错误率变高。
- Pod 内存 Limit 值偏低,容器内存使用量超过 Limit 值会被 OOMKilled 掉,导致Pod 容器出现内存 OOM 使 Pod 频繁重启。
- 由于Pod CPU Limit 值设置太低,CPU 使用量超过该值,对应容器的 CPU 会被 ThrottledPod CPU Throttled。
Kubernetes Pod 智能巡检方案
巡检定义
检测对象:Kubernets 集群下异常重启的 Pod 数据占比
触发逻辑:当异常重启Pod 数据占比持续升高时
根因查询: Kubernets 集群 + namespace + pod + 状态 + 事件 + 日志
数据点频率: 10 s
检测数据范围: 30 分钟
巡检周期: 30 分钟
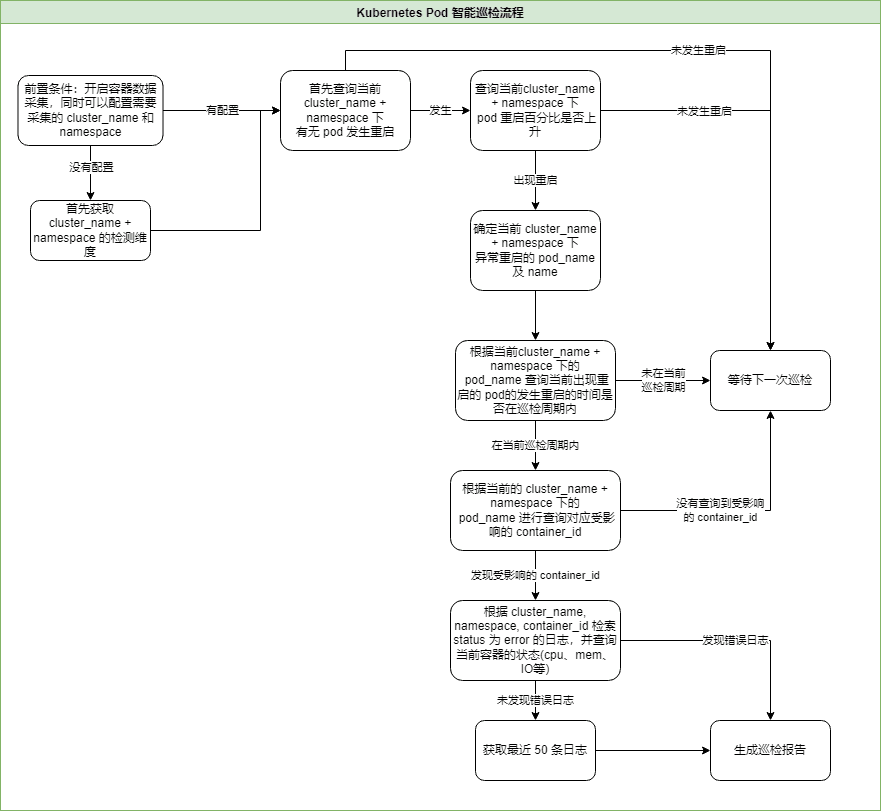
巡检流程设计
以 cluster_name + namespace 下重启 pod 数占比数作为入口,当该指标出现升高时触发生成事件逻辑并进行根因查询
巡检事件报告

- 事件概览:描述异常巡检事件的对象、内容等
- 异常Pod:可查看当前 namespace 下异常 pod 的状态
- container 状态:可查看详细的错误时间、容器 ID 状态、当前资源情况、容器类型;点击容器 ID 会进入具体容器详情页
- 错误日志:展示异常 Pod 最近的错误日志信息,点击对应的 message 可以跳转到日志详情
Kubernetes Pod 智能巡检使用实践
前置条件
- 在观测云中开启「容器数据采集」
- 自建 DataFlux Func 的离线部署
- 开启自建 DataFlux Func 的脚本市场
- 在观测云「管理 / API Key 管理」中创建用于进行操作的 API Key
- 在自建的 DataFlux Func 中,通过「脚本市场」安装「观测云自建巡检 Core 核心包」「观测云算法库」「 观测云自建巡检(K8S-Pod重启检测)」
配置巡检
在自建 DataFlux Func 创建新的脚本集开启 Kubernetes Pod 异常重启巡检配置
from guance_monitor__runner import Runner
from guance_monitor__register import self_hosted_monitor
import guance_monitor_k8s_pod_restart__main as k8s_pod_restart
# 观测云空间 API_KEY 配置(用户自行配置)
API_KEY_ID = 'wsak_xxx'
API_KEY = '5Kxxx'
# 函数 filters 参数过滤器和观测云 studio 监控\智能巡检配置中存在调用优先级,配置了函数 filters 参数过滤器后则不需要在观测云 studio 监控\智能巡检中更改检测配置了,如果两边都配置的话则优先生效脚本中 filters 参数
def filter_namespace(cluster_namespaces):
'''
过滤 namespace 自定义符合要求 namespace 的条件,匹配的返回 True,不匹配的返回 False
return True|False
'''
cluster_name = cluster_namespaces.get('cluster_name','')
namespace = cluster_namespaces.get('namespace','')
if cluster_name in ['k8s-prod']:
return True
'''
任务配置参数请使用:
@DFF.API('K8S-Pod异常重启巡检', fixed_crontab='*/30 * * * *', timeout=900)
fixed_crontab:固定执行频率「每 30 分钟一次」
timeout:任务执行超时时长,控制在 15 分钟
'''
# Kubernetes Pod 异常重启巡检配置 用户无需修改
@self_hosted_monitor(API_KEY_ID, API_KEY)
@DFF.API('K8S-Pod异常重启巡检', fixed_crontab='*/30 * * * *', timeout=900)
def run(configs=[]):
"""
参数:
configs:
配置需要检测的 cluster_name (集群名称,可选,不配置根据 namespace 检测)
配置需要检测的 namespace (命名空间,必选)
配置示例: namespace 可以配置多个也可以配置单个
configs = [
{
"cluster_name": "xxx",
"namespace": ["xxx1", "xxx2"]
},
{
"cluster_name": "yyy",
"namespace": "yyy1"
}
]
"""
checkers = [
# 配置 Kubernetes Pod 异常重启巡检
k8s_pod_restart.K8SPodRestartCheck(configs=configs, filters=[filter_namespace]),
]
Runner(checkers, debug=False).run()
开启巡检
在 DataFlux Func 中在配置好巡检之后可以通过直接再页面中选择 run() 方法点击运行进行注册,在点击发布之后就可以在观测云「监控 / 智能巡检」中查看并进行配置,配置好后在自建的 DataFlux Func 中,通过「管理 / 自动触发配置」,为所编写的巡检函数创建自动触发配置。
触发事件
当巡检过程中发现 Pod 异常重启的现象,就会生成事件报告,报告内容如下:
- 事件概览:描述异常巡检事件的对象、内容等
- 异常Pod:可查看当前 namespace 下异常 pod 的状态
- container 状态:可查看详细的错误时间、容器 ID 状态、当前资源情况、容器类型;点击容器 ID 会进入具体容器详情页
- 错误日志:展示异常 Pod 最近的错误日志信息,点击对应的 message 可以跳转到日志详情
通过报告也没还可以跳转到 Kubernetes 监控视图来查看对应的集群及节点的健康状态帮助我们来进行分析异常。
Kubernetes Pod 异常排查思路
当出现巡检事件告警后可以根据事件内容结合以下场景问题场景来进行问题定位及排查:
Pod 状态异常
就绪失败,即 Pod 一直无法到达 Ready 状态,无法接收请求进行业务处理,常见的根因如下:
- 资源不足,无法调度(Pending),即集群的 Node 没有预留资源能够满足 Pod 的 Request 资源。
- 镜像拉取失败( ImagePullBackoff ),镜像的仓库地址,tag 出现问题。
- 磁盘挂载失败(Pending),容器挂载的 PVC 没有 bound。
- Liveless probe 探针失败,频繁重启。
- Readiness probe 探针失败,无法达到 Ready 状态。
- postStart 执行失败,一直无法进入运行状态。
- 运行时程序崩溃( CrashLoopBackOff ),频繁重启。
- 配置错误,比如挂载的 Volume 不存在(RunContainerError)。
容器频繁重启
报告期内出现 Pod 频繁重启现象,常见的根因如下:
- 程序异常退出,比如非法地址访问,比如进入了程序需要退出的条件等。
- 容器内存使用量超过内存 Limit 量,被 OOMKilled。
Pod 相关服务状态异常
具体体现在 Pod 服务的请求错误率变高或者请求处理 P95 响应时间高等,常见的根因如下:
- 请求量突增,程序自身可能触发流控或者其他异常处理,导致请求处理失败率提升;
- 自身代码处理错误,请求量没有变化,可能是上线新的功能有 bug;
- 不可压缩资源不足(磁盘,内存),请求处理包含磁盘的写操作,资源不足出现失败;外部依赖服务报错,请求处理需要调用下游服务,他们报错引发请求处理失败。
- 外部依赖服务响应时间高,请求处理需要调用下游服务,他们的响应时间高会导致请求处理慢。
Pod 内存使用率过高
Pod 容器出现内存 OOM,Pod 频繁重启,常见的根因如下:
- 自身代码内存泄露;
- Pod 内存 Request 值偏低,如果该值偏低的情况下配置 HPA,会频繁触发扩容,同时具有被驱逐的风险。
- Pod 内存 Limit 值偏低,容器内存使用量超过 Limit 值会被 OOMKilled 掉。
Pod CPU使用率过高
Pod 的整体 CPU 使用率一直维持在超过 80% 的状态,常见的根因如下:
- 自身代码效率不足,业务处理的时间复杂度太高,需要找到热点方法进行优化;
- Pod CPU Request 值偏低,如果该值偏低的情况下配置 HPA,会频发触发扩容,同时具有被驱逐的风险。


