













热线电话:400-882-3320

GuanceDB 主要解决什么问题?
GuanceDB 解决大规模可观测数据的存储、查询、聚合加速和长期留存问题,适合日志、指标、链路、RUM、事件和业务数据持续增长的场景。
监控场景在变,但底层系统还停留在过去
随着业务发展,可观测平台接入的数据不再局限于基础监控指标,还包括应用日志、链路、用户体验和业务数据。数据规模、查询并发和保留周期持续增长时,传统计算与存储紧耦合的架构容易在扩容效率和资源利用率上遇到瓶颈。
仪表盘、监控器和日常排障中存在大量重复查询。GuanceDB 3.0 通过识别适合预聚合的查询模式,在数据写入阶段构建聚合结果,减少高频查询重复扫描原始数据的开销,并根据实际负载调度查询资源。
传统 MPP 架构 vs GuanceDB 3.0
这是传统 MPP 架构与 GuanceDB 3.0 架构的对比示意,重点说明存储与计算解耦后,查询资源如何根据业务负载独立调度,在性能、成本和资源隔离之间提供更灵活的选择。
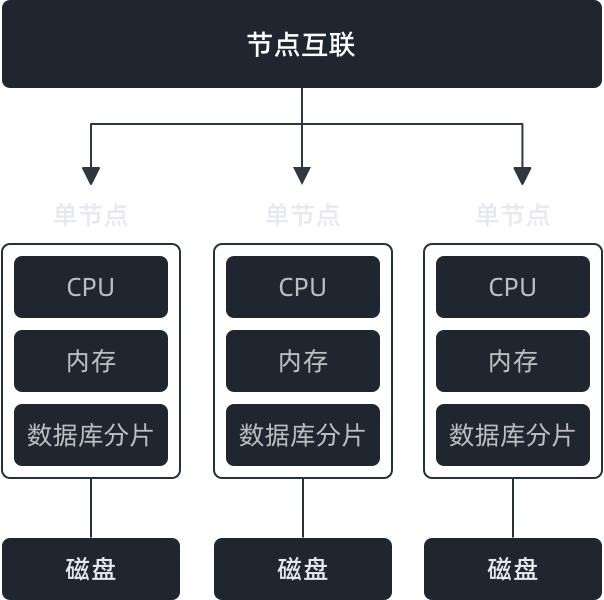
传统 MPP 架构
计算与存储紧耦合,扩展能力有限。计算资源难以动态调整,整体利用率偏低,扩容成本高。
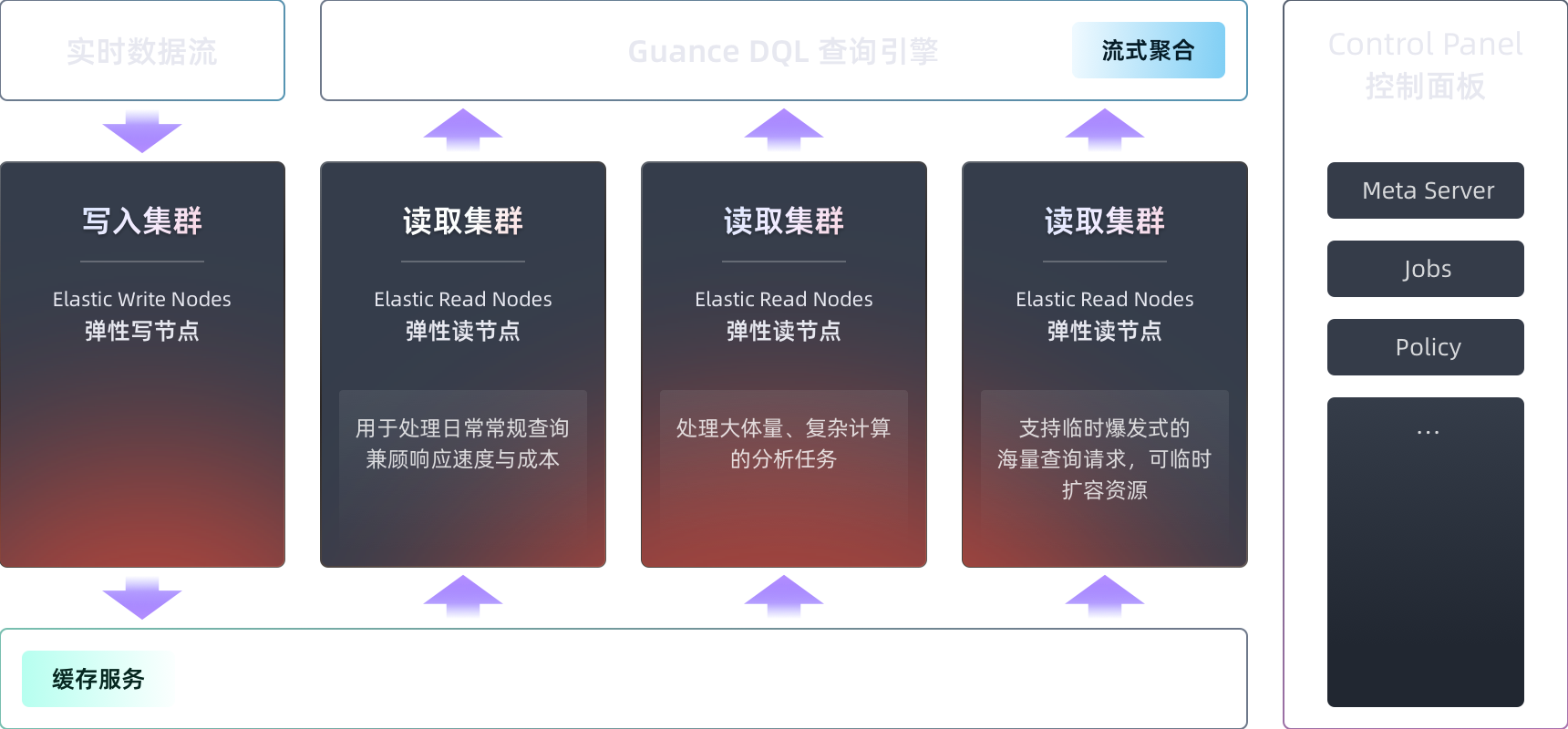
完全存算分离的 AI 时代存储引擎
采用数据湖仓一体化与存算分离设计,让数据存储和查询计算可以独立扩展。系统利用云基础设施的弹性能力,按业务负载调整查询资源,并可结合不同算力类型优化资源成本。例如在工作日查询高峰扩展计算资源,在夜间与周末降低空闲算力。实际容量、查询并发和弹性范围以部署规格与服务配额为准。
针对不同企业的需求
通过智能调度、多租户优化、弹性算力供给等设计,GuanceDB 3.0 实现了可观测数据处理架构在性能、成本、灵活性上的全面进化,助力企业高效构建更具性价比的数据基础设施。
系统根据不同企业使用场景,构建了多层次资源调度策略:
01. 高性价比用户
优先使用共享计算池,并可在高峰时段灵活调用系统中闲置算力,实现资源最大化复用
02. 对性能敏感用户
配置独立的查询计算集群,确保在任何场景下都具备稳定、快速的响应能力
03. 中小型团队
统一接入共享池,系统通过并发控制机制,在成本可控的同时保障查询体验
04. 以存储为主的用户
采用独立处理路径,剥离计算资源,进一步降低系统负载和成本
全新流式聚合加速引擎
数据写入的时候,根据用户的历史查询自动构建需要加速的查询,并按最小的时间分片将数据预聚合,当查询发现相关数据已经在当前时间范围内有预聚合结果,直接从流式聚合中获取数据,而不从原始数据获取数据了。

透明加速
对适合预聚合的指标与日志查询,业务侧无需改写现有仪表盘和监控器,系统自动复用聚合结果
任意数据时间
按数据本身标记的时间进行聚合,并结合写入与更新机制处理延迟上报数据
资源占用更低
将适合预聚合的高频查询转由流式聚合结果响应,减少原始数据重复扫描和数据库查询压力
GuanceDB 3.0 的优势
支持丰富的业务场景
可以为不同的业务提供不同的读集群,用于不同的业务场景,使用不同的配置方案(高并发、离线任务等)并且各自隔离
实时查询
批量报表
业务分析
数据挖掘

GuanceDB 2.0 将为私有化版本继续提供服务
FAQ
GuanceDB 解决大规模可观测数据的存储、查询、聚合加速和长期留存问题,适合日志、指标、链路、RUM、事件和业务数据持续增长的场景。
存算分离让存储和查询资源可以独立扩展。团队可以根据查询高峰、长期留存和成本要求调整计算资源,而不必把所有数据和计算绑定在同一套集群里。
流式聚合加速适合高频仪表板、监控器和固定分析范式。系统可根据历史查询构建预聚合结果,减少每次从原始数据重新扫描的成本。