热线电话:400-882-3320
微信扫码
加入官方交流群
Infrastructure Monitoring
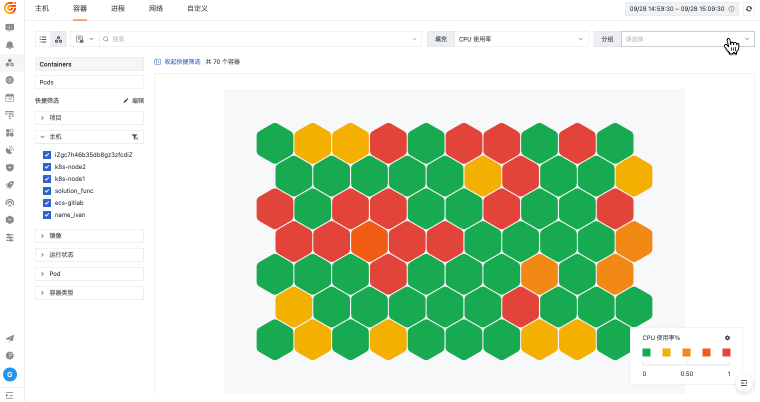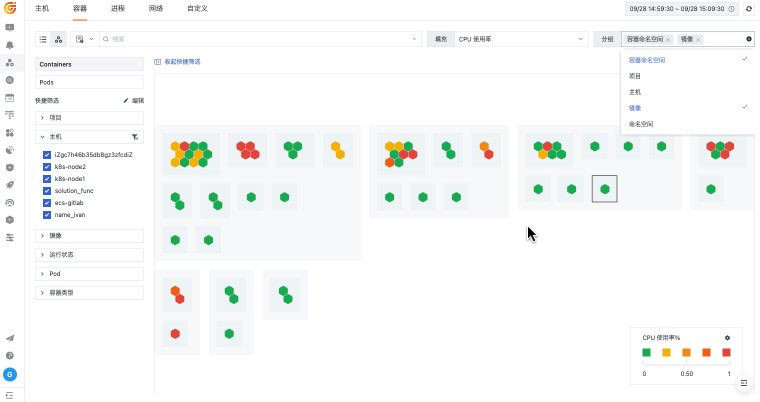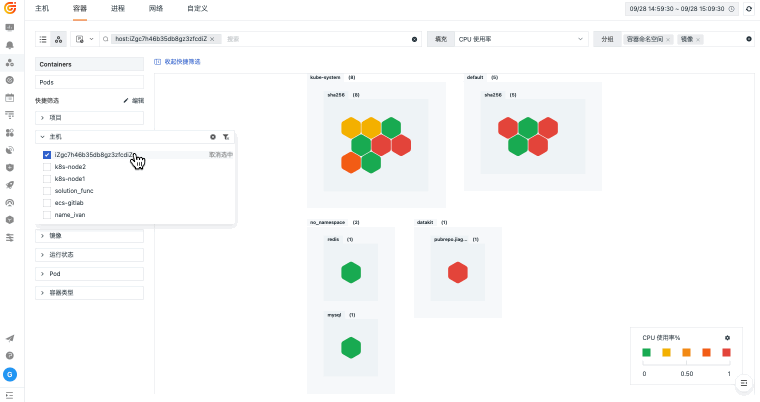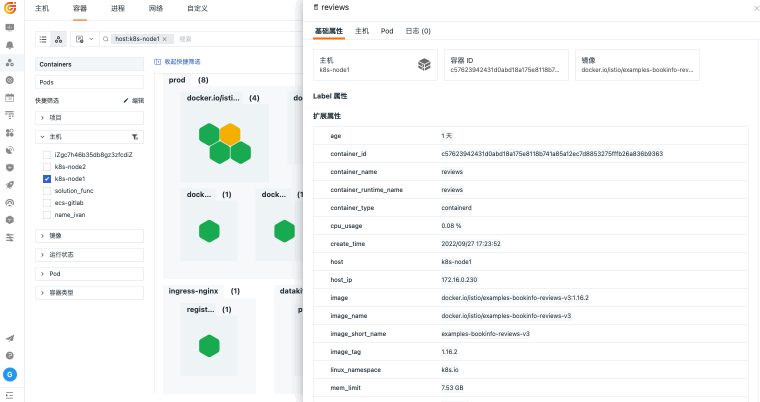
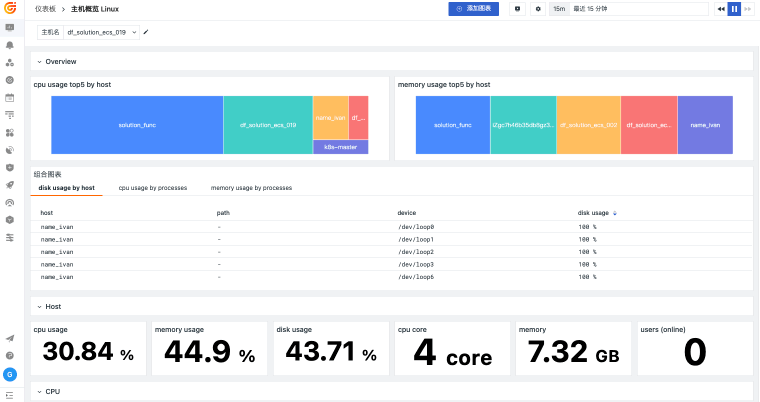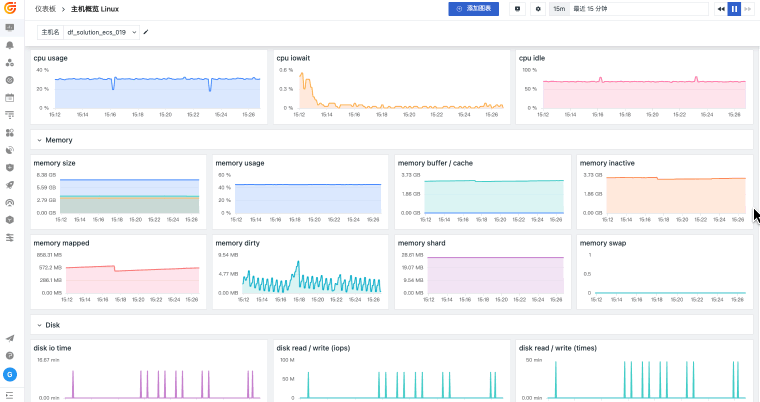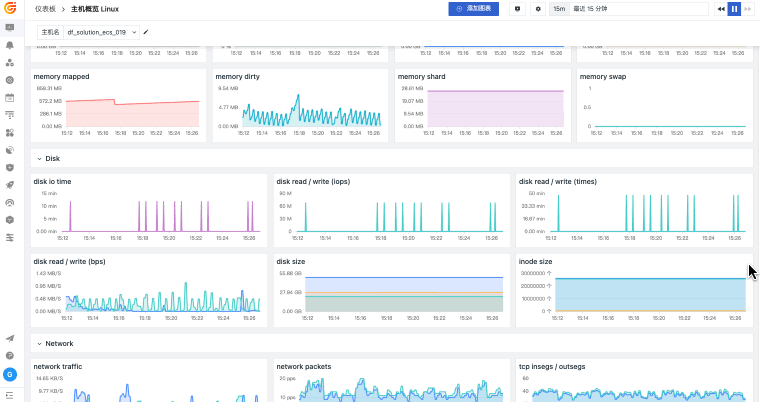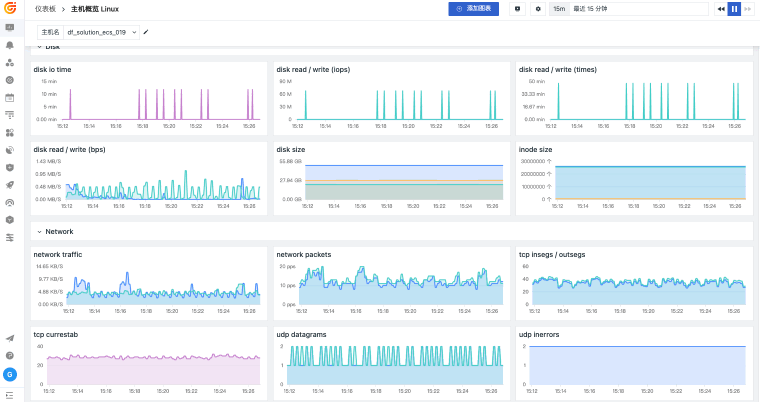
观测云基础设施监控统一观测主机、容器、进程、网络和云资源,关联指标监控、日志、链路、事件和告警,并通过仪表板呈现资源状态、容量风险和故障影响范围。
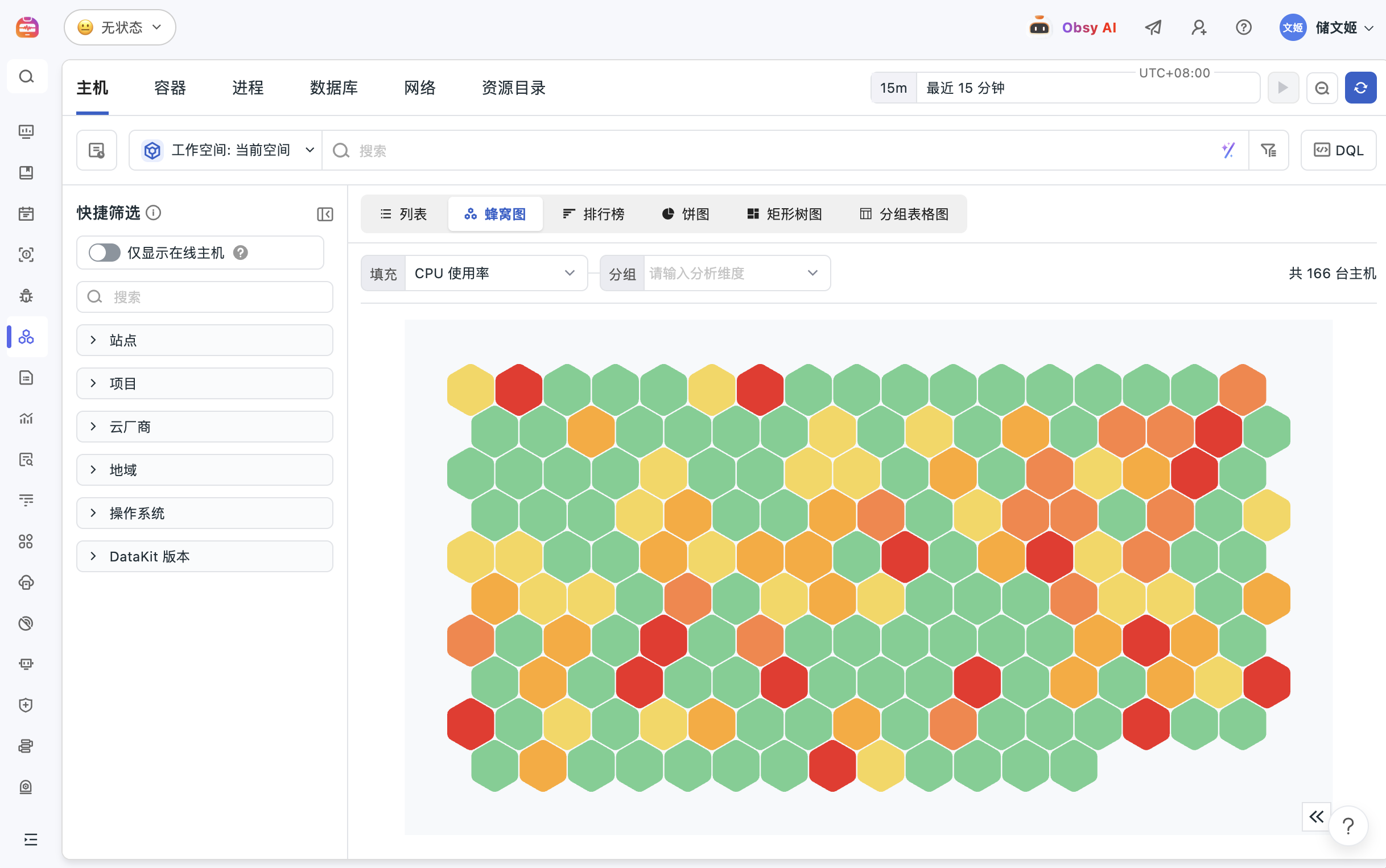
基础设施监控解决什么问题
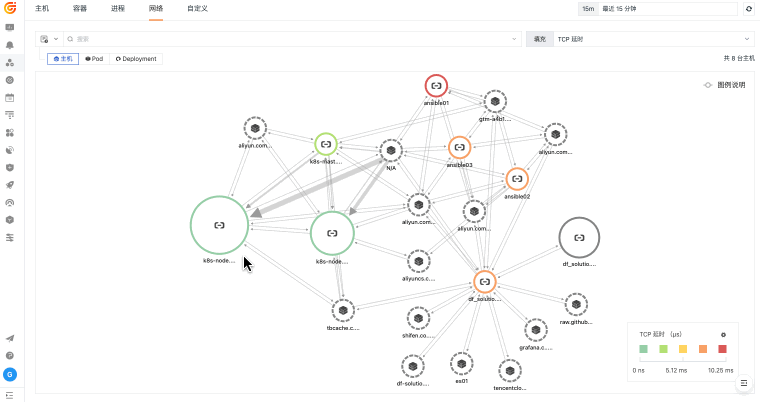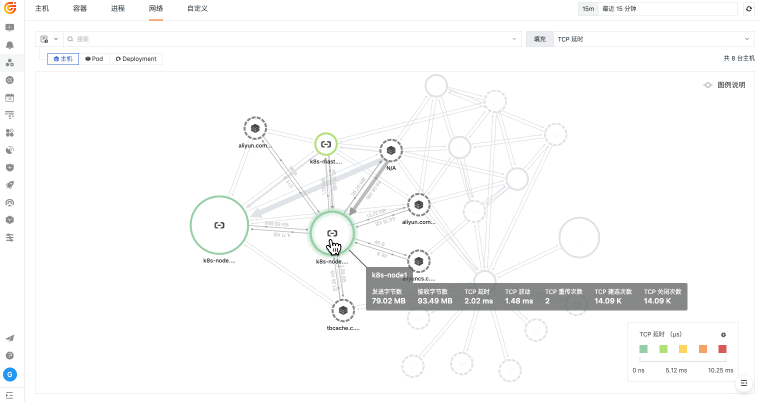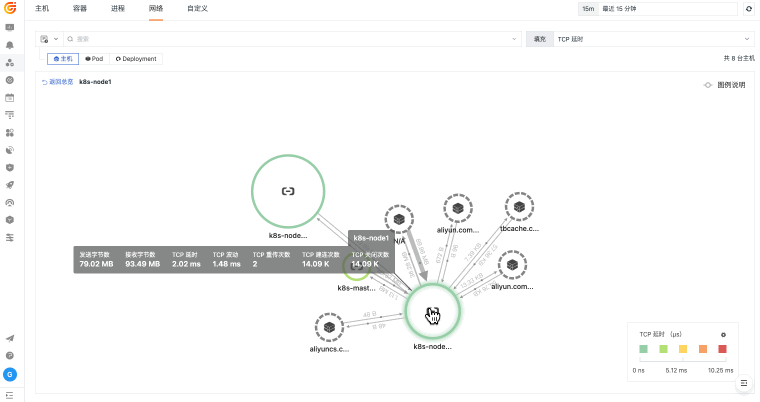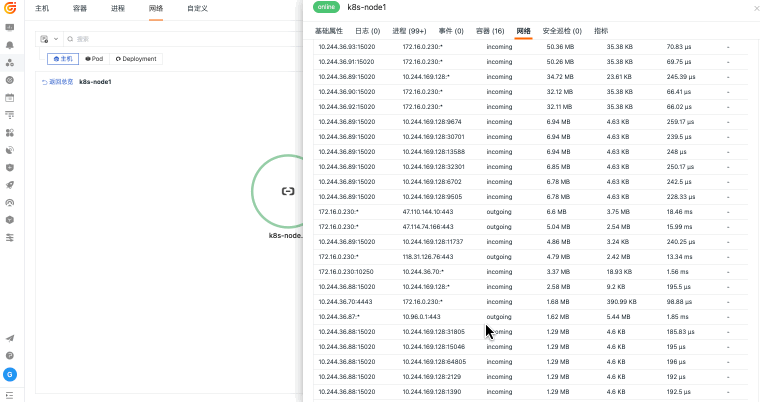
当主机、容器、网络和云资源分散在不同平台时,排障往往先卡在“资源在哪里、谁受影响、该看哪个指标”。观测云基础设施监控通过 DataKit 采集、统一标签、指标监控和资源关系视图,把资源运行状态与日志、链路、告警和事件关联起来,帮助团队更快判断问题边界。
常见问题
继续探索
从产品文档、相关方案到技术实践,按当前问题选择下一步。
来自产品实践、故障排查与技术方案的精选内容