观测云日志最佳实践

日志是开发人员记录系统运行状态的最佳手段,是一个系统的重要组成部分。日志通常不属于系统的核心功能,但却是我们了解系统运行用的最多的功能。对于开发和运维人员来说,好的日志可以帮助我们了解系统运行的状态、快速定位解决问题、发现系统瓶颈、预知潜在风险,基于日志我们还能挖掘出业务数据,从而反馈产品改进产生更大的价值。那么什么样的日志算是一个好的日志?基于观测云对日志的处理体系,我们怎么样最大化发挥日志的作用?这是本文将要探讨的范围。
日志收集
在探讨如何对系统产生的日志进行收集之前,非常有必要对日志记录的内容做一些规范引导,我们对日志进行处理、检索和分析时,都是要基于日志记录的内容来进行,所以日志该记录什么?不该记录什么?这个点非常重要。当然如果我们的系统已经产生了大量的日志,并且我们无法对其进行改变,那么我们该做的事是最大化的发挥日志的作用。
日志记录规范
理想中的日志应该记录不多不少的信息,一条好的日志应该记录以下信息:
2023-02-17 00:00:00.000 |pid|level|[service,trace-id,span-id,user-id,biz-id]|thread-name|class-name|method-name : message
参数说明:
- time:日志产生的时间
- pid:进程ID
- level:日志级别,常见的有debug、info、warn、error、fatal
- service:应用名称
- trace-id:调用链标识
- span-id:调用链层级标识
- user-id:用户标识(可选)
- biz-id:业务标识(可选)
- thread-name:线程名称(可选)
- class-name:类名称(可选)
- method-name:方法名称
- message:日志内容
除了合理的记录日志信息以外,我们也要对日志级别、日志格式等进行规范。日志级别优先级从低到高可以分为:TRACE、DEBUG、INFO、WARN、ERROR、FATAL。日志格式也应该做好统一规范,使用格式化的日志结构能够方便扩展添加更多字段,要有日志主要内容字段,额外的信息也要记录在日志上下文中。
有关日志记录规范更多内容可参考这两篇文章: 《最佳日志实践v2.0》、《惊讶!我定的日志规范被CTO在全公司推广了》
日志采集方案
对于日志记录进行规范后,利用观测云 DataKit 对系统产生的日志进行采集,目前能够支持的采集方式可以分为:
采集日志文件
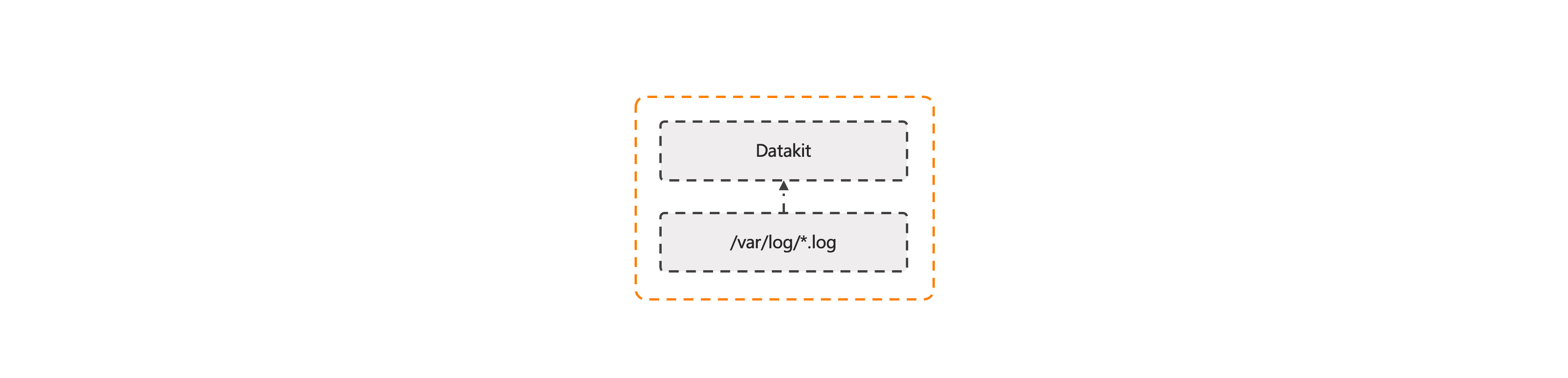
对于传统的日志处理方式,日志都是直接写到日志文件中的,DataKit 支持日志文件的采集方式,具体配置可参考:《文件采集》
采集容器 stdout 日志
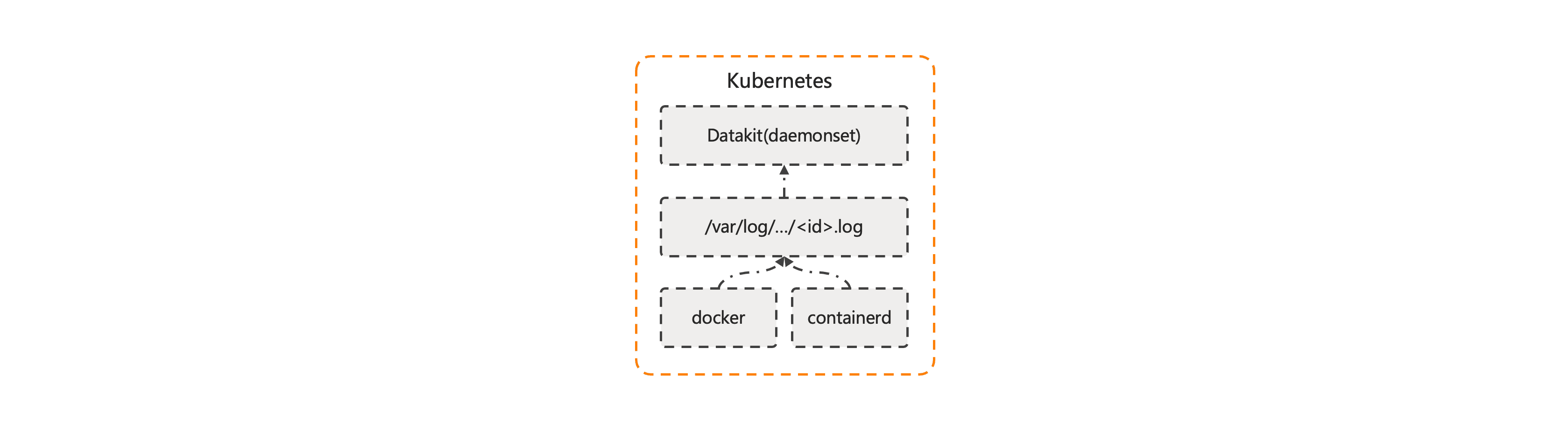
对于 Kubernetes 集群中容器产生的 stdout 日志,通过 daemonset 的方式安装 DataKit 到 Kubernetes 集群中后,DataKit 会默认采集容器的 stdout 和 stderr 日志,具体配置可参考:《容器日志采集》
远程推送日志
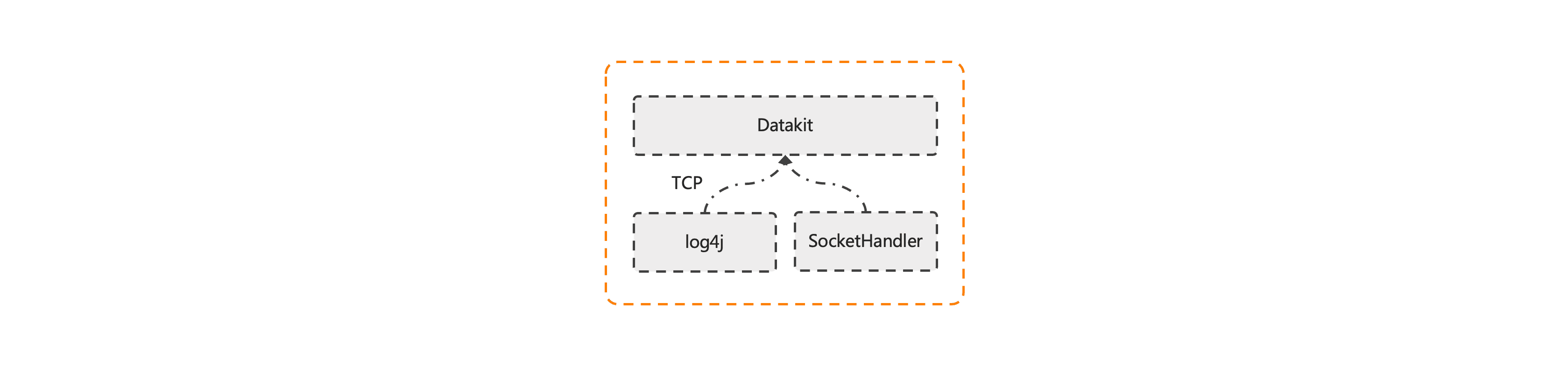
支持直接把应用产生的日志直接推送到 DataKit,例如 Java log4j 和 Python 原生的 SocketHandler 均支持直接把日志推送给远端服务,具体配置可参考:《Socket 日志接入》
Sidercar方式采集
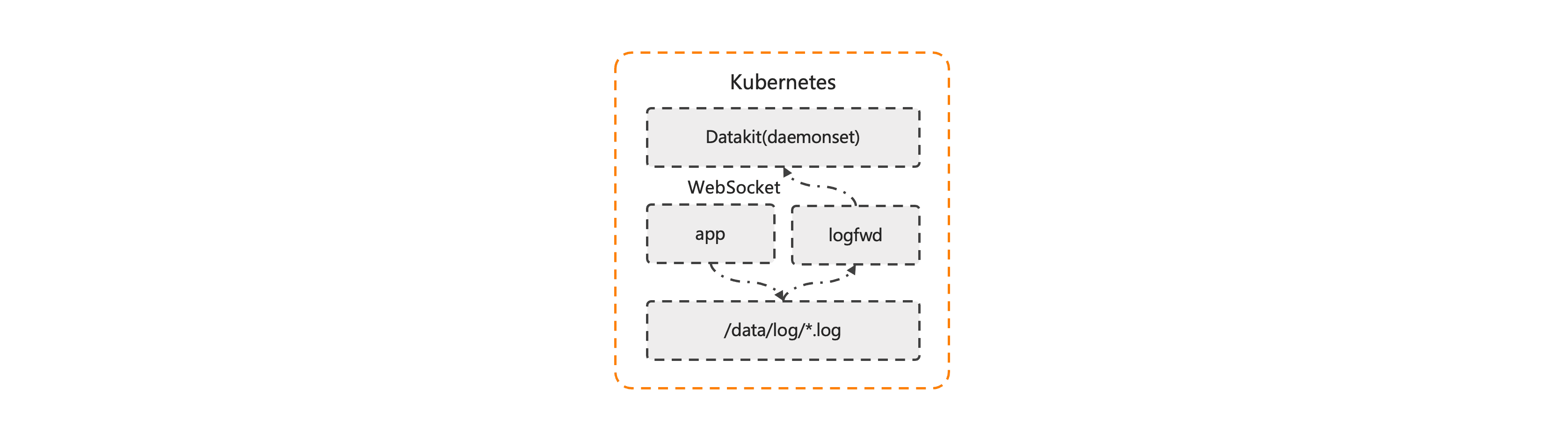
对于日志直接输出到容器日志文件中的方式,可通过 Sidercar 外接 DataKit 的 logfwd 容器的方式对日志进行采集,logfwd 容器将日志推送至 DataKit,具体配置可参考:《Sidercar 日志采集》
Kafka 方式采集

对于部分业务将日志数据输入到 Kafka 中,或者对接公有云日志服务产生的日志服务(一般都支持 Kafka 协议消费),DataKit 支持直接从 Kafka 中订阅消费日志,具体配置可参考:《订阅 Kafka 中的数据》
第三方开源系统对接
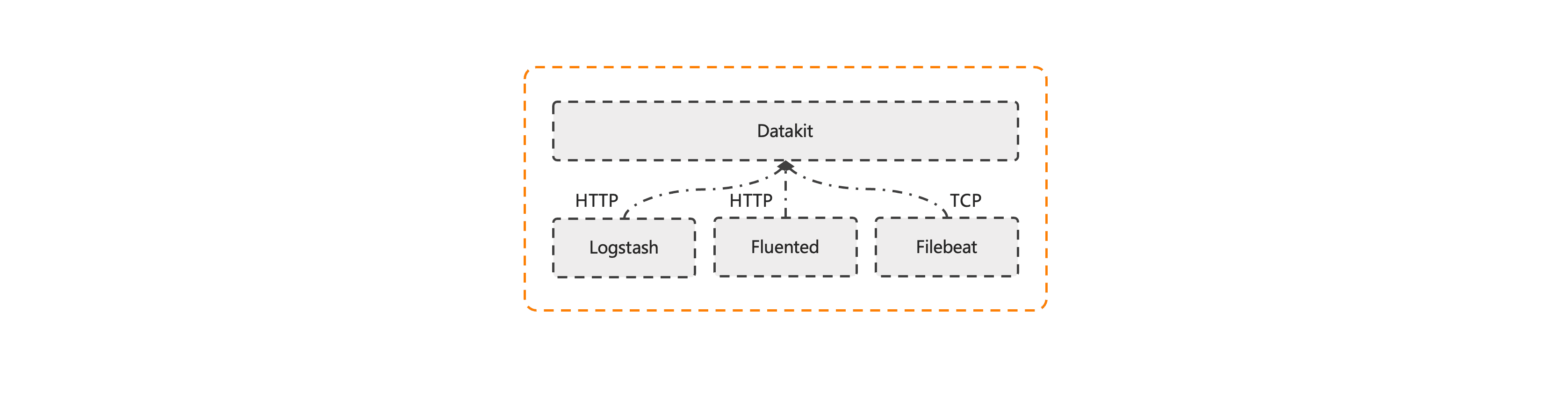
已经建设了开源日志采集组件,支持将 Logstash / Filebeat / Fluented 中的数据直接推送至 DataKit,具体配置可参考:《Logstash 日志数据接入》、《Filebeat日志数据接入》、《Fluented日志数据接入》
日志处理
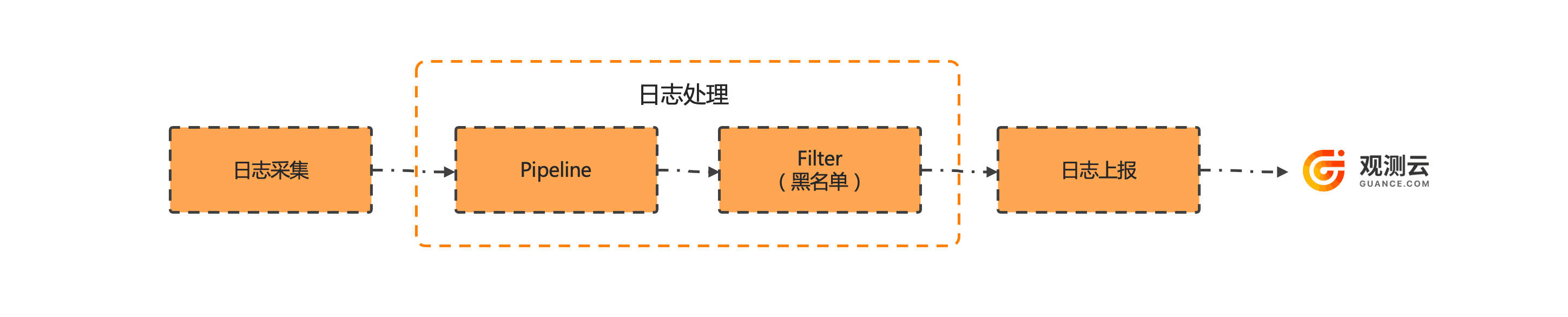
DataKit 对日志数据的处理整体上可以总结为:日志采集、日志处理和日志上报。在日志处理阶段,DataKit 会将采集到的单条日志通过 Pipeline 进行切割处理,再经过 Filter 黑名单规则进行过滤,最终上报到观测云。也就是说观测云对日志的切割处理是在采集器 DataKit 上来执行的,利用边缘计算的能力对日志进行切割处理能够有效缩减日志传输成本,并降低日志延迟。
观测云日志数据格式可以分为两个部分:
- 日志正文内容:message字段里面承载日志的主要内容,观测云会基于 message 字段创建全文索引,建议控制此字段的长度,可有效加快全文检索的速度。
- 日志扩展字段:日志产生的上下文信息,比如日志产生的主机
host、容器名称container_name、方法名method_name等,通过这些上下文信息可快速定位日志产生的环境信息。建议 Pipeline 切割处理时将这些字段从日志正文内容切割出来,观测云会对扩展字段添加索引,加速基于扩展字段查询日志的速度。

在进行日志处理之前,先来理解一个概念,DataKit 所有日志采集配置都会配置 source 字段,用来区分日志来源,日志处理阶段的设计也都是基于此字段展开的。DataKit 采集的日志会先经过 Pipeline 进行切割处理,Pipeline 是基于日志来源 source 来区分的,不同的日志来源可以配置不同的 Pipeline 脚本进行处理。Pipeline 可以对日志内容进行提取,设置扩展字段和正文内容,通过 Pipeline 切割出关键的字段也可以基于这些字段生成指标,并对这些字段进行监控检测告警等,以一个实际例子说明:
{
"ip":"172.27.173.221",
"type":"coslogs",
"instanceId":"mcos-4549029279",
"appName":"mcos",
"methodName":"doElect",
"level":"INFO",
"clusterName":"k8s-1",
"@timestamp":"2023-02-16T13:26:54.263Z",
"@version":"1",
"className":"kd.bos.elect.impl.redis.RedisCompeteElectorImpl",
"time":"2023-02-16T13:26:54.269Z",
"message":"this query for the table cvp_tda_task_history has not return pkcolumn",
"line":107
}
对于这条 JSON 格式的日志,如果不进行 Pipeline 切割处理,最终在观测云呈现的日志主要内容就是这段 JSON,不管从日志展示来看,还是日志检索来看,这种效果都非常差。
经过下面的 Pipeline 脚本进行切割处理,对关键字段进行提取,并覆盖了 message 日志正文内容,日志的展示效果和检索效率都会提高很多,更多有关 Pipeline 的使用可参考:《DataKit Pipeline使用手册》、《Pipeline 详细手册》


日志处理中的过滤器 Filter 黑名单功能,也是基于 Pipeline 切割处理后的关键字段,配置相应的过滤规则,字段命中某些规则就对日志进行过滤,不再上报此条日志。
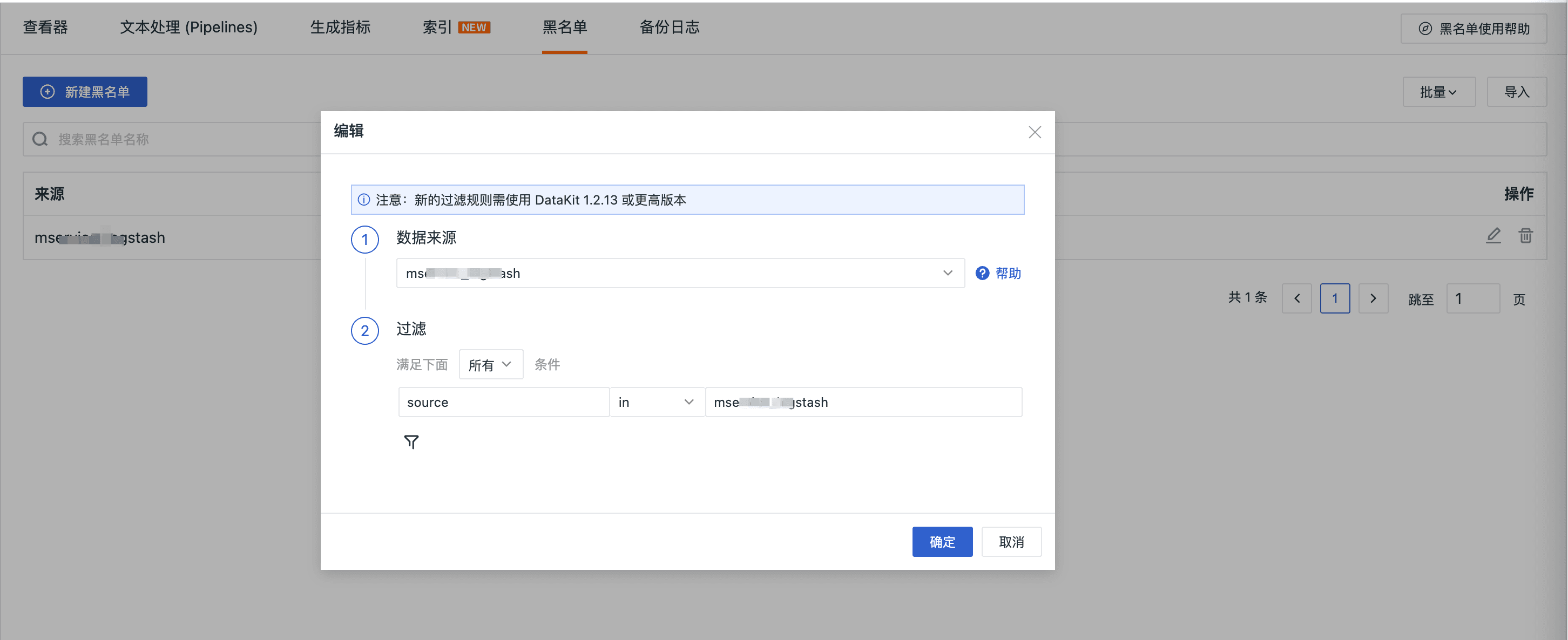
日志检索分析
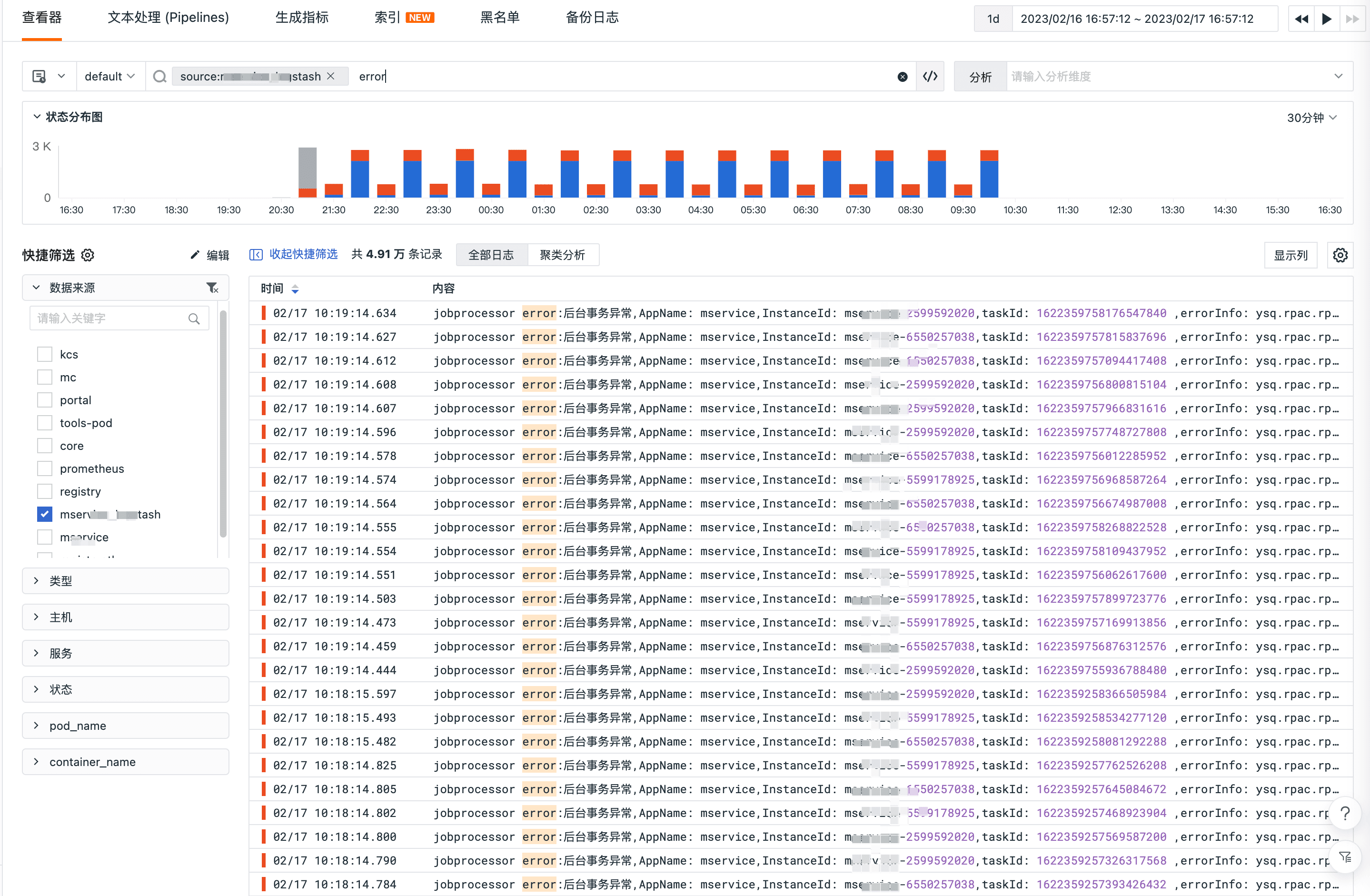
日志查看检索是通过查看器进行的,利用观测云查看器的功能可以对日志进行快速检索、关键字段的检索、全文检索等,也可以对日志某些字段进行维度分析等操作。日志检索的效率极大程度上是依赖 Pipeline 对日志进行正确的切割处理,理解了 Pipeline 日志处理可以说是理解了观测云日志的最佳实践。
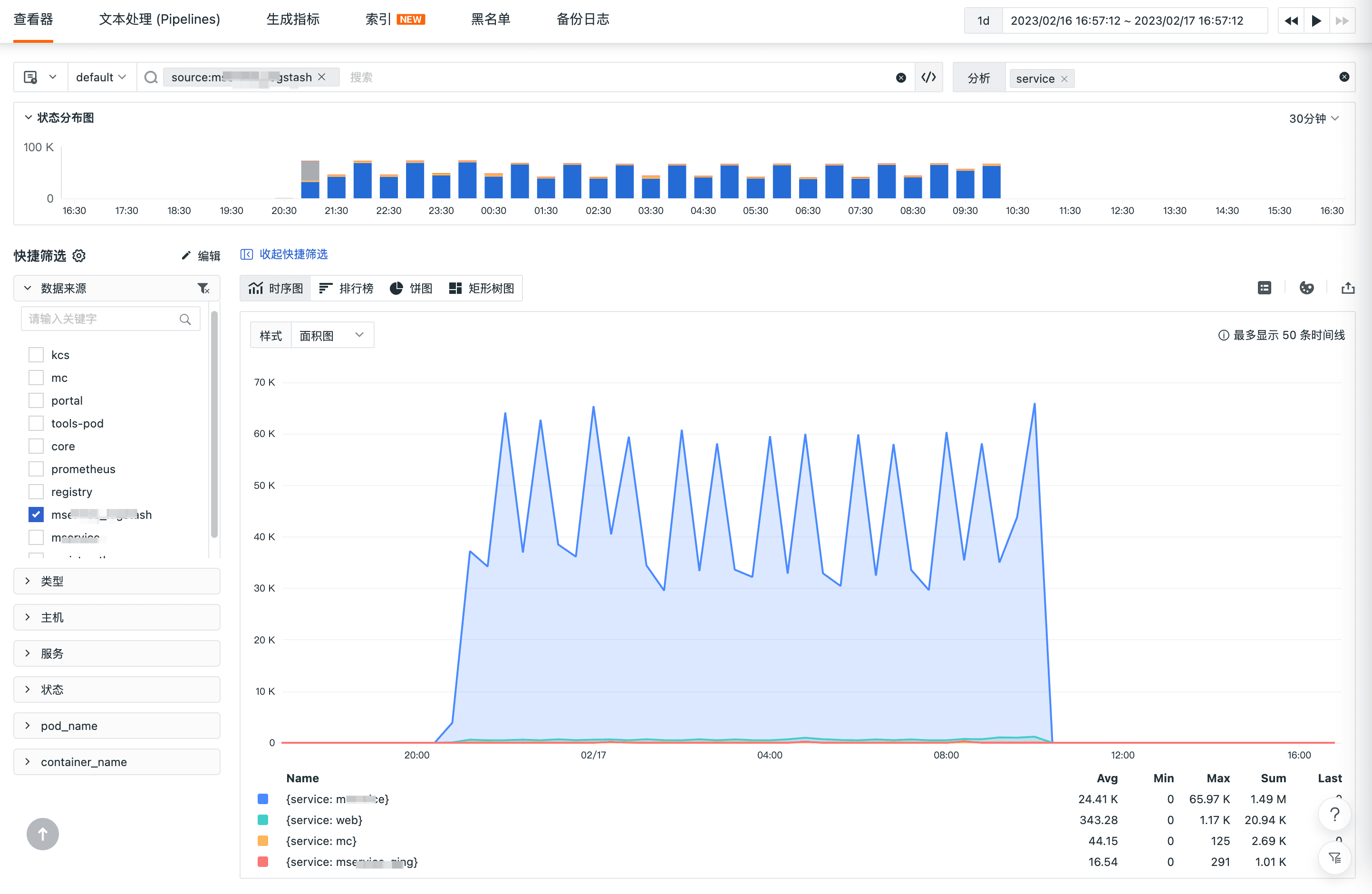
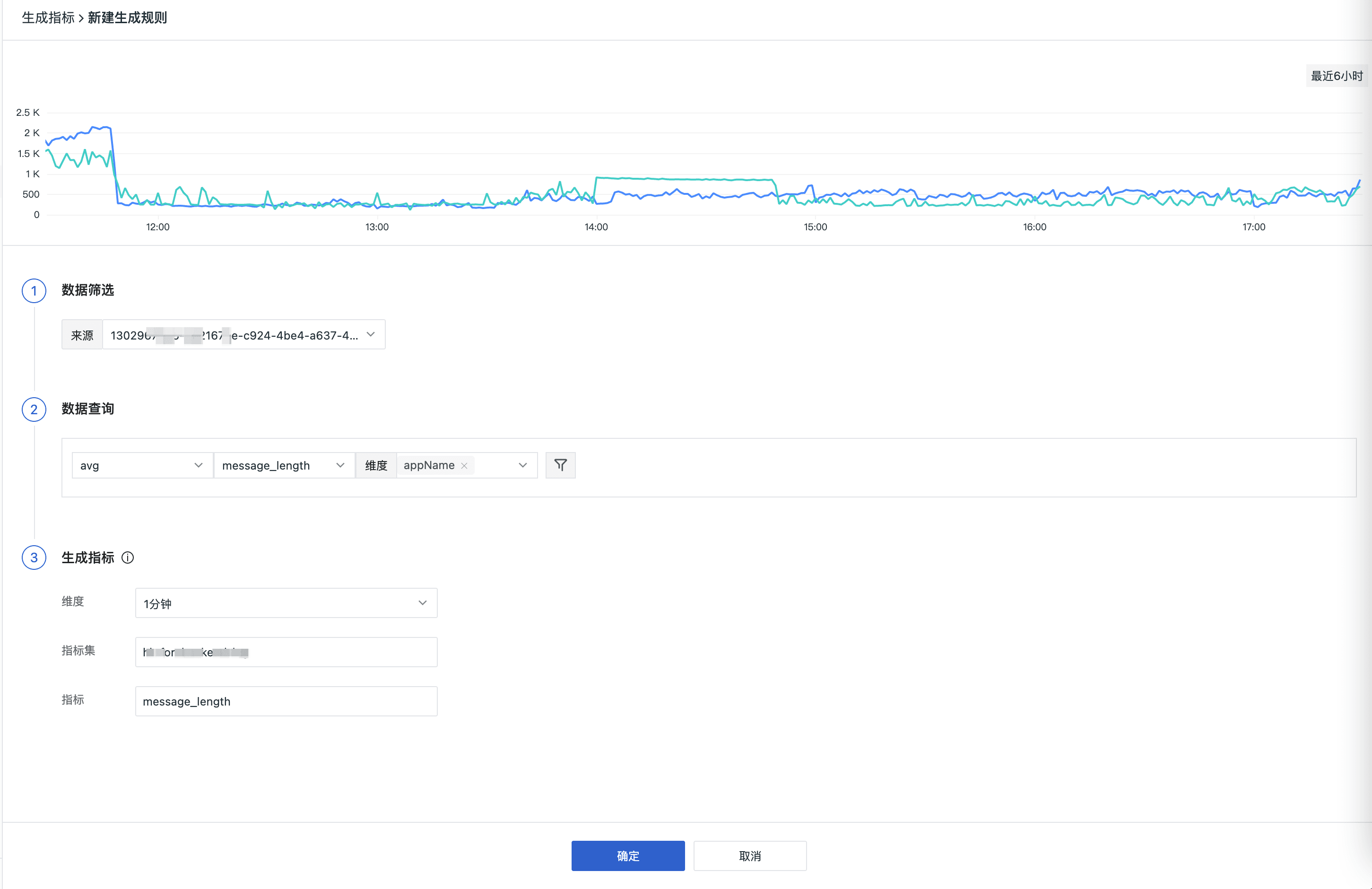
基于 Pipeline 切割的关键字段,可以生成指标数据,例如统计所有服务日志的内容长度:
日志检测
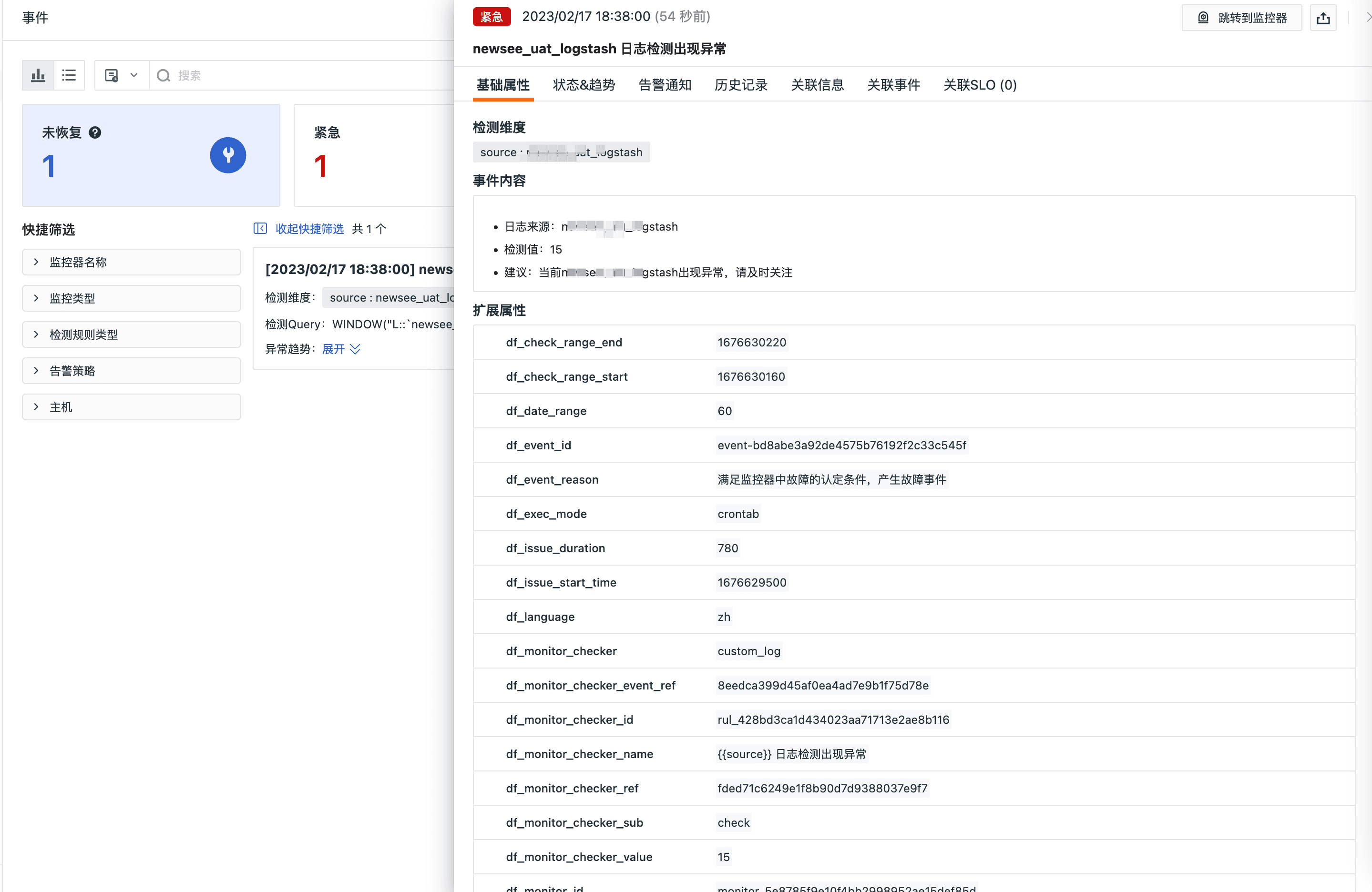
基于观测云提供的监控器-日志检测,支持对日志的关键字设置告警,对潜在的风险及时预警。日志检测器基于日志来源,可设置筛选关键词,支持基于标签过滤日志,支持维度聚合操作。监控器会产生事件消息,事件消息会按照绑定的告警策略发出告警通知,配置日志 error 关键词检测为例:
- 日志检测配置
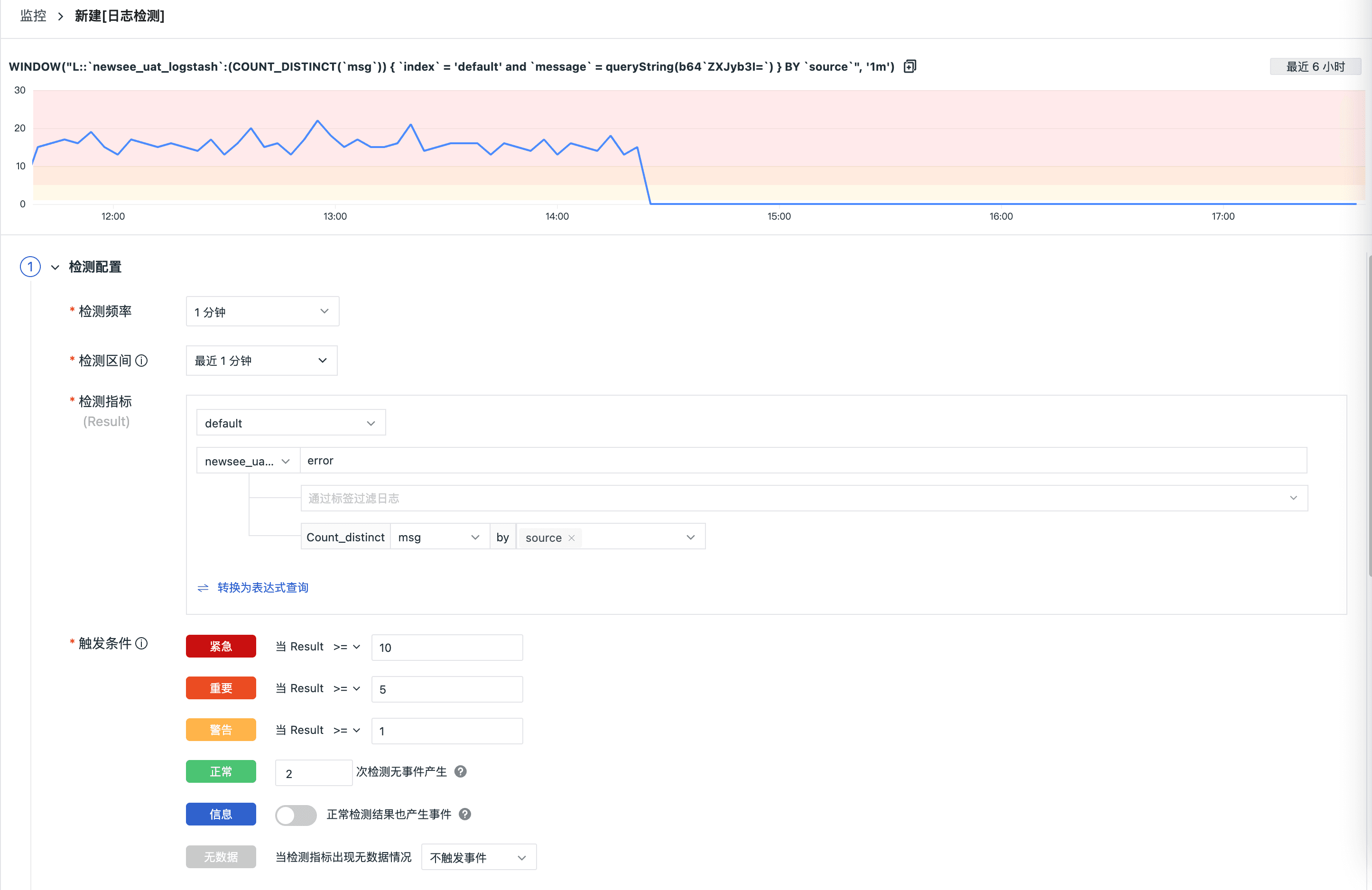
- 事件通知配置

- 告警效果