










解密组合监控:优化系统性能的关键策略

前言
在当今数字化时代,随着企业和组织对于高效、稳定的系统运行的需求不断增加,监控系统已经成为维持业务流畅运转的关键环节之一。然而传统的单一指标监控已逐渐无法满足日益复杂的系统需求,分散的监控平台没法组合已经成为一个最大的痛点,再加上现代系统的运行涉及多个方面、多个层面的数据交互与协同。所以在这种情况下,组合监控应运而生,成为优化系统性能、确保系统稳定运行的重要策略之一。
本文将深入探讨观测云组合监控的概念、实现原理及其在实际应用场景中的价值,解析何为组合监控,以及如何构建一个高效的组合监控系统来应对日益复杂的系统运行环境。通过本文的阅读,您将更好地了解组合监控的核心概念,并掌握实施组合监控的关键步骤与技巧。
什么是组合监控
组合监控是指通过对多个监控指标进行综合分析和比较,来评估系统或者业务的整体运行状态的一种监控方式。它可以将多个单独的监控指标结合起来,形成一个更全面、更准确的系统状态评估。通过组合监控,我们可以更好地了解系统的健康状况,并及时发现潜在的问题或异常情况。这样可以帮助我们快速采取相应的措施,保障系统或业务的正常运行。
为什么需要组合监控
- 综合性评估:单一的监控指标可能无法全面反映系统或业务的整体状态。通过组合多个监控指标,可以综合评估系统的健康状况,更准确地了解系统运行情况。
- 异常检测:通过对多个指标进行比较和分析,可以更容易地发现异常情况。如果某个指标出现异常,但其他指标正常,可能是一个误报;而当多个指标同时出现异常时,很可能表示真实存在问题。
- 故障预警:组合监控可以帮助我们提前预警潜在故障。通过设定阈值和规则,当多个指标超过设定的范围时,可以及时发出警报并采取相应的措施来避免故障的发生。
- 效率提升:通过组合监控,我们可以将相关联的指标放在一起进行分析和比较,从而更快速地识别问题所在,并采取相应的解决方案。这样可以节省时间和资源,并提高故障排查和处理效率。
怎么设置组合监控
步骤一:登录到观测云的管理控制台
登录注册链接:https://auth.guance.com/
步骤二:新建监控器
在控制台中点击监控器 > 新建监控器 > 组合检测,进入区间检测规则配置页面。
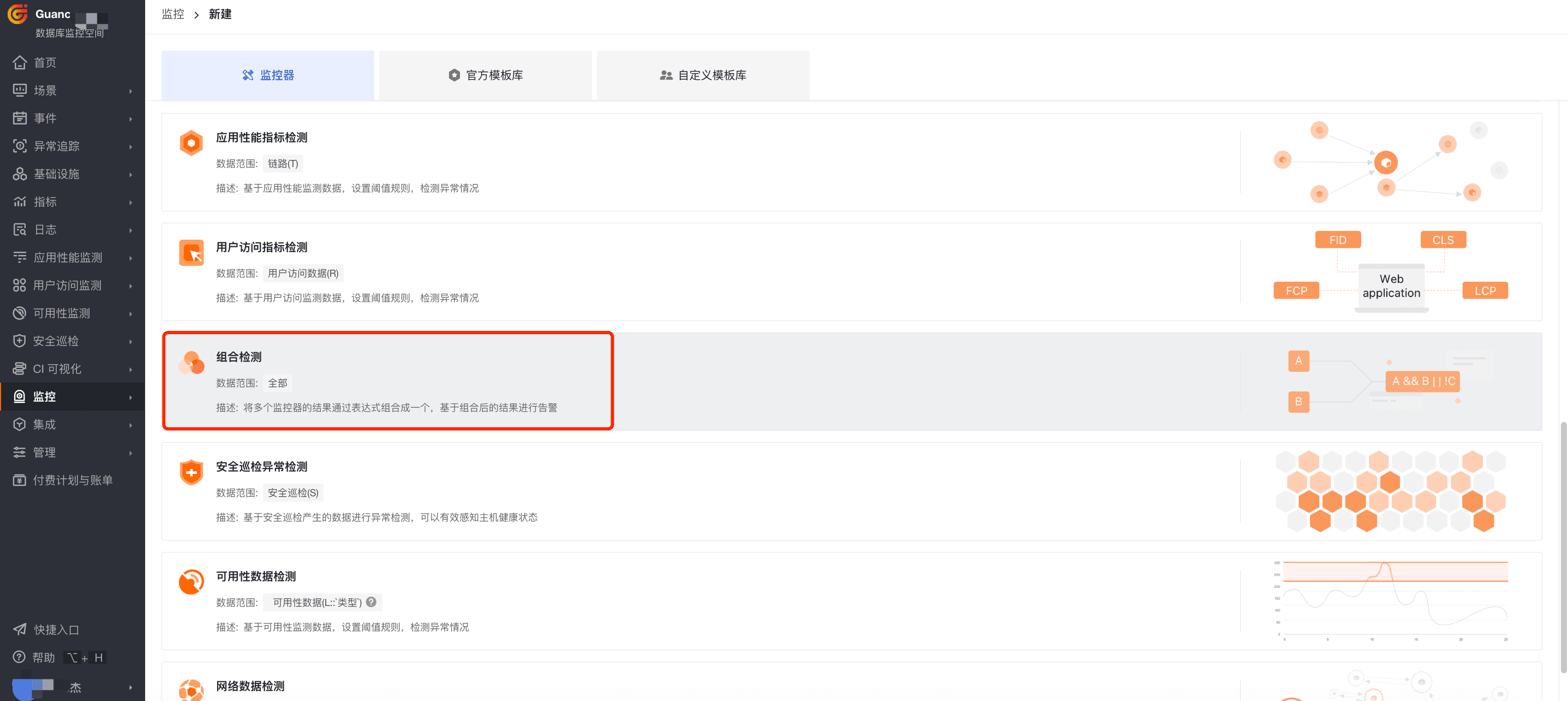
步骤三:检测配置
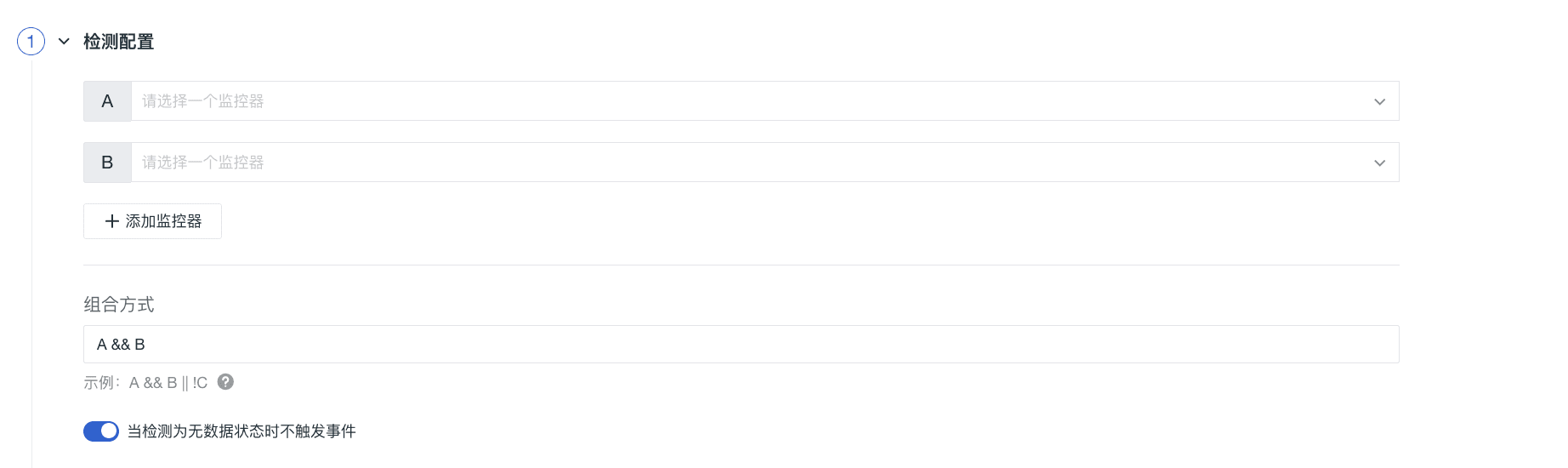
1)选择至少两个监控器,右侧会显示其 by 条件分组。
注意:最多添加 10 个监控器。
2)组合方式:遵循与或非的运算逻辑表达式来定义组合监控器是否触发事件。当所选监控器都触发异常状态时,解析为真,反之解析为假。
逻辑运算:当所选监控器处于异常状态时,解析为 True,具体如下:
| 事件状态 | 解析后 | 严重等级 |
|---|---|---|
| critical | TRUE | 4 |
| error | TRUE | 3 |
| warning | TRUE | 2 |
| nodata | TRUE | 1 |
| ok | FALSE | 0 |
| info | FALSE | 0 |
| 不触发事件视为正常,同样解析为 False |
运算符详解:
| 逻辑运算 | 说明 |
|---|---|
| && 与 | A&&B:若运算结果为 true,则返回 A、B 中更不严重的状态等级。例如:A=critical,B=warning,那么返回 warning。 |
| || 或 | A||B:若运算结果为 true,则返回 A、B 中更严重的状态等级。例如:A=critical,B=warning,那么返回 critical。 |
| ! 非 | “异常状态” 对应的非都是 ok;“正常状态”对应的非都是 critical。例如:若 A=error,那么 !A=ok;若 A=ok,那么 !A=critical。 |
如何定义【真】?
基于所选的监控,若监控器中存在分组,那么当所有监控器共同的分组都处于异常状态时才会解析为“真”。
例如:当选择了监控器 A(主机 1、2、3、4 产生告警)与监控器 B(主机 2、3、5、6 产生告警),那么组合监控器 (A&&B) 只有主机 2 和 3 会返回为“真”,产生告警。
注意:当组合方式中的监控器分组不一致,这种没有共同分组的情况将不会产生告警。
| 分组情况 | 是否一致 | 示例 |
|---|---|---|
| 监控器 A 无分组,监控器 B 有分组 | 否(此时不会产生告警) | B: by host |
| 监控器 A 和 B 分组部分一致 | 否(此时不会产生告警) | A: by host, service, B: by host, device |
| 监控器A 和 B 分组完全不一致 | 否(此时不会产生告警) | A: by host, B: by service |
| 监控器 A 和 B 分组为包含关系 | 是(此时可以正常检测和告警) | A: by host, B: by host, device (dimension_tags=host) |
| 监控器 A 包含于监控器 B 分组,监控器 B 包含于监控器 C 分组 | 是(此时可以正常检测和告警) | A: by host,B: by host, device,C: by host, device, os (dimension_tags=host) |
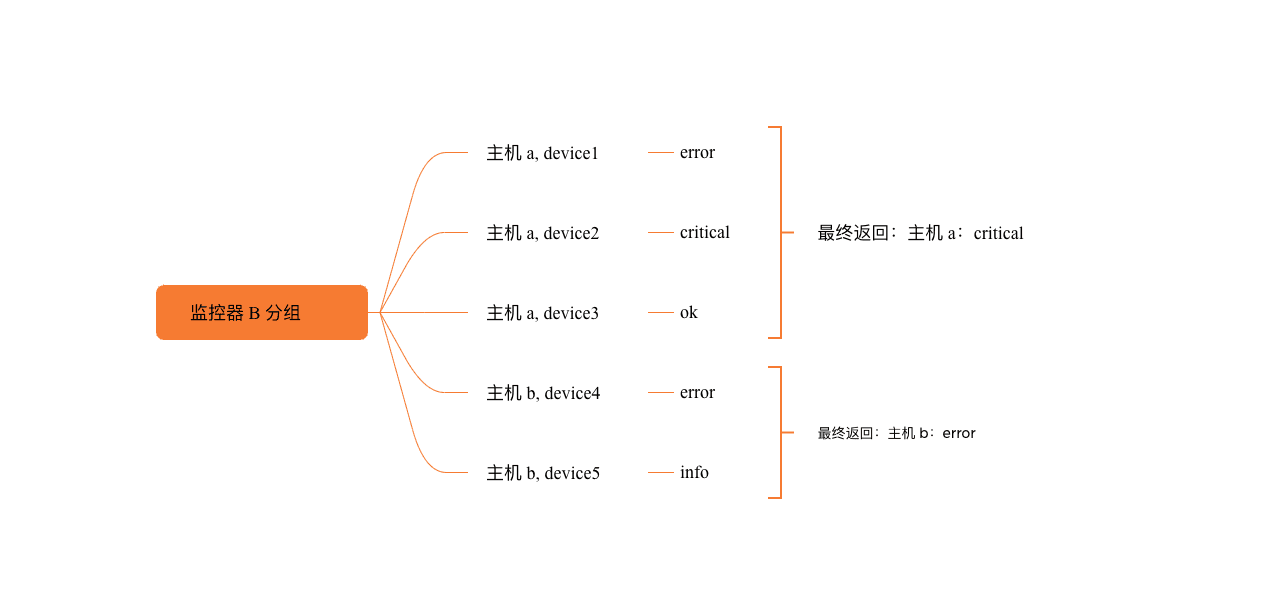
示例:
选择监控器 A:by host;监控器 B:by host, device,此时取交集 host 作为最终的 dimension_tags,监控器 A 正常判断即可,监控器 B 中取主机的所有 device 的最严重等级作为其状态,例如:
步骤四:事件通知
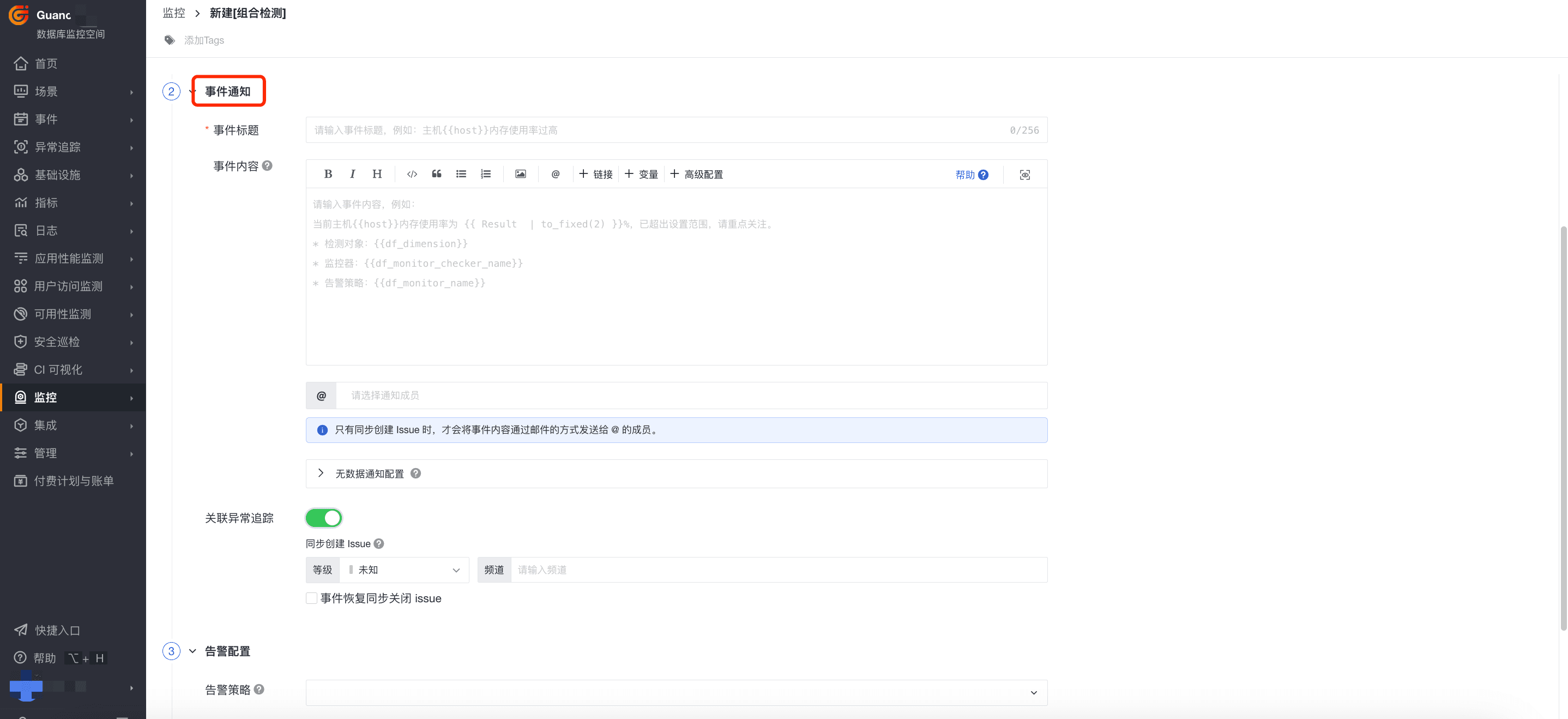
1)事件标题:设置告警触发条件的事件名称,支持使用预置的模板变量。
注意:最新版本中监控器名称将由事件标题输入后同步生成。旧的监控器中可能存在监控器名称和事件标题不一致的情况,为了给您更好的使用体验,请尽快同步至最新。
2)事件内容:满足触发条件时发送的事件通知内容。支持输入 Markdown 格式文本信息并预览效果,支持使用预置的关联链接,支持使用预置的模板变量。
注意:不同告警通知对象支持的 Markdown 语法不同,例如:企业微信不支持无序列表。
无数据通知配置:支持自定义无数据通知内容,若没有配置,则自动使用官方默认的通知模版。
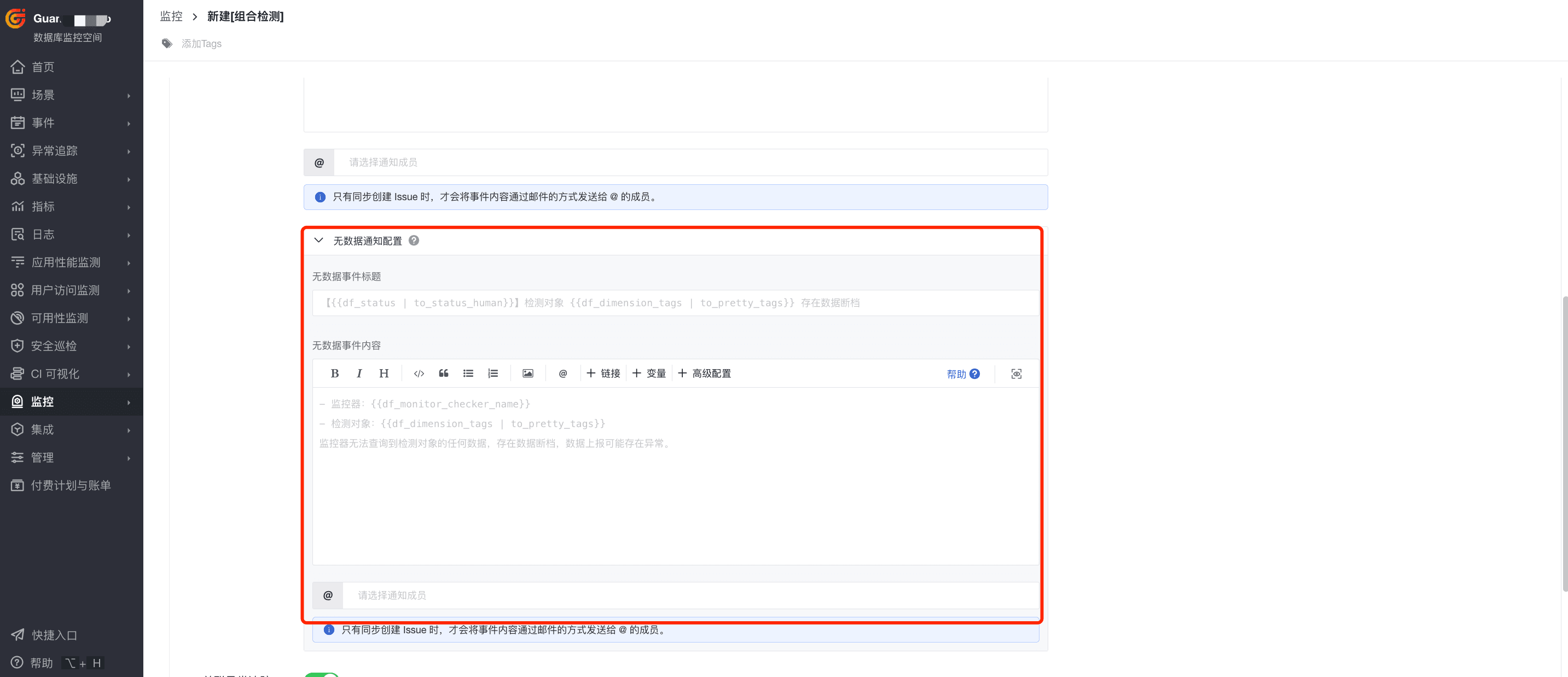
3)关联异常追踪:开启关联后,若该监控器下产生了异常事件,将同步创建 Issue。选择 Issue 的等级以及需要投递的目标频道,产生的 Issue 可以前往异常追踪 您选定的频道进行查看。
在事件恢复后,可以同步关闭 Issue。

事件内容自定义高级配置
观测云支持在事件内容中通过高级配置添加关联日志或错误堆栈,以便查看异常情况发生时的上下文数据情况:
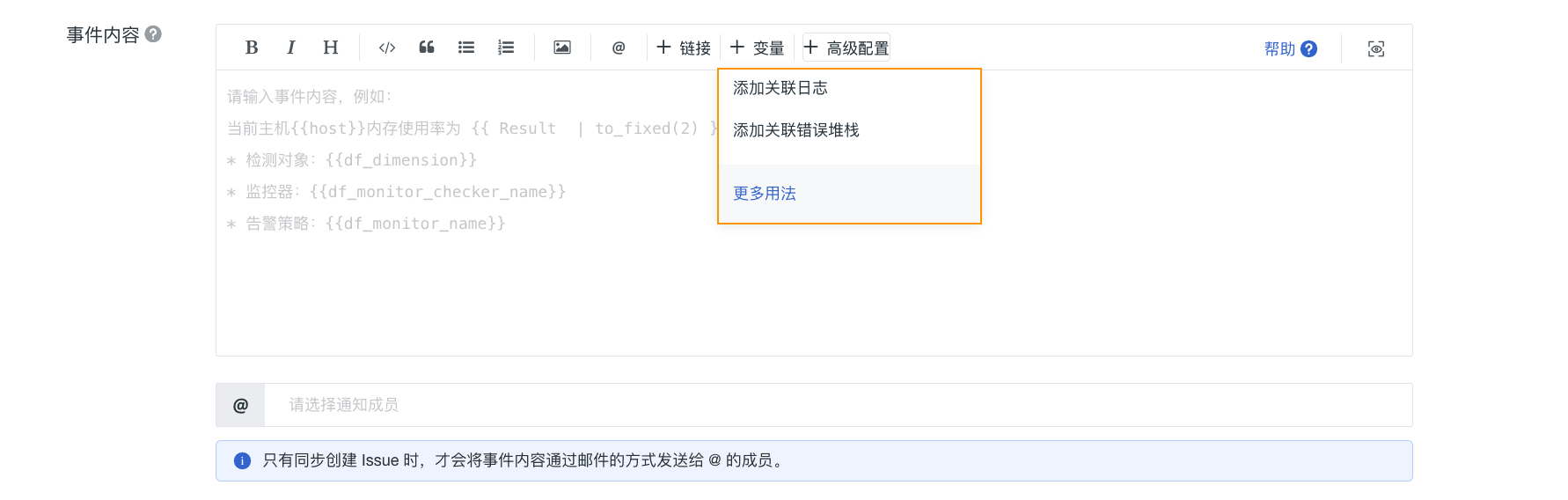
- 添加关联日志:
查询,如获取一条索引为 default 的日志 message:
{% set dql_data = DQL("L::RE(.*):(message) { index = 'default' } LIMIT 1") %}
关联日志:
{{ dql_data.message | limit_lines(10) }}
- 添加关联错误堆栈
查询:
{% set dql_data = DQL("T::re(.*):(error_message,error_stack){ (source NOT IN ['service_map', 'tracing_stat', 'service_list_1m', 'service_list_1d', 'service_list_1h', 'profile']) AND (error_stack = exists()) } LIMIT 1") %}
关联错误堆栈:
{{ dql_data.error_message | limit_lines(10) }}
{{ dql_data.error_stack | limit_lines(10) }}
步骤五:告警配置
告警策略:监控满足触发条件后,立即发送告警消息给指定的通知对象。告警策略中包含需要通知的事件等级、通知对象、以及告警沉默周期。
告警策略支持单选或多选,点击策略名可展开详情页。若需修改策略点击编辑告警策略即可。

步骤六:关联
关联仪表板:每一个监控器都支持关联一个仪表板,可快速跳转查看。
最佳实践
场景一:Infra 基础设施层指标组合监测
Infra 基础设施层指标组合监测中,SRE 工程师需要设置一些优先级最高的告警,比如当 CPU、MEM 同时满足 90% ,紧急通知一线人员,设置主要分以下几步骤:
步骤一:新建 CPU 监控器
- 监控器 > 新建监控器 > 阈值检测
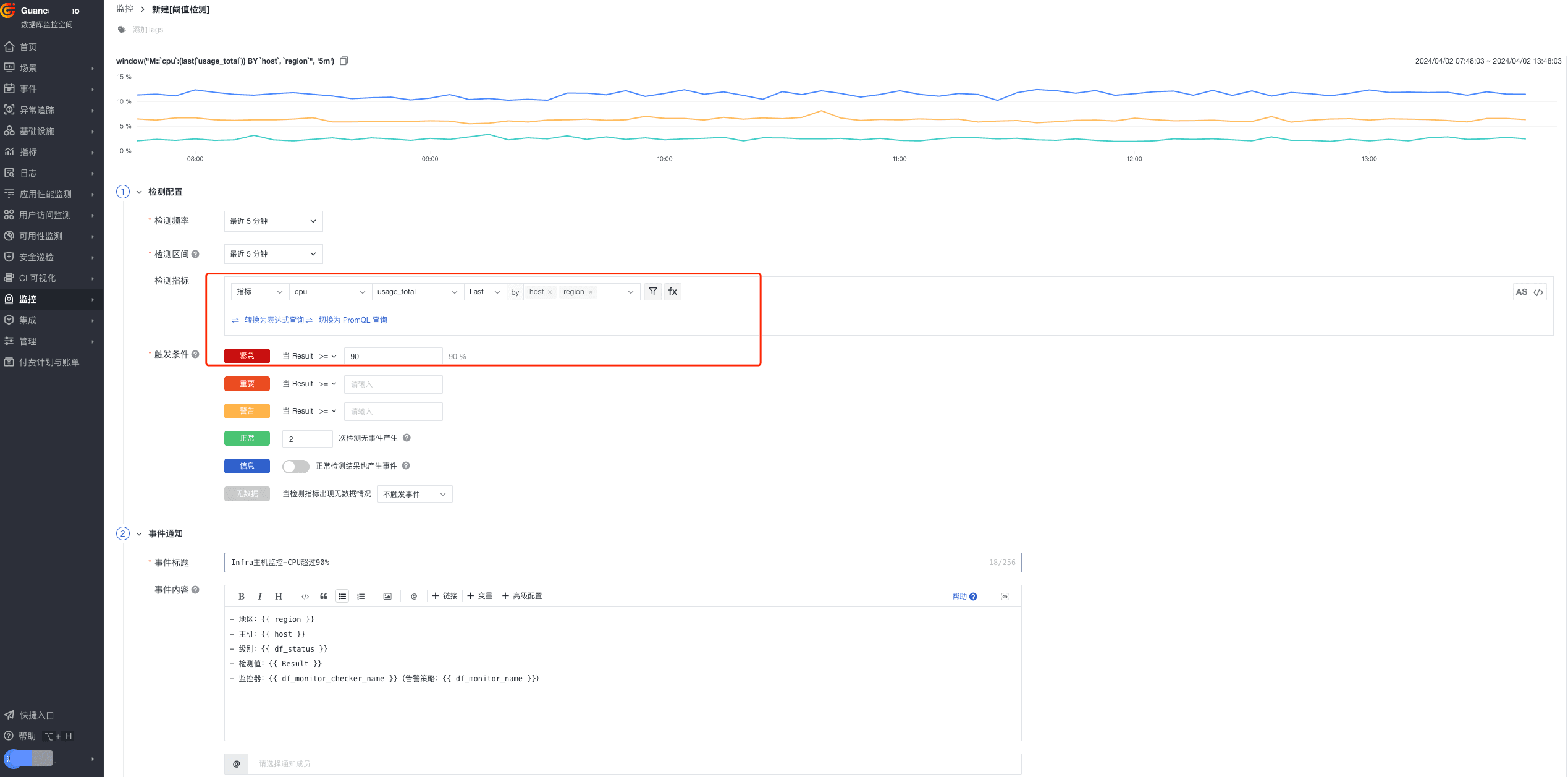
- 配置通知对象和告警规则,并保存
步骤二:新建 MEM 监控器
- 监控器 > 新建监控器 > 阈值检测
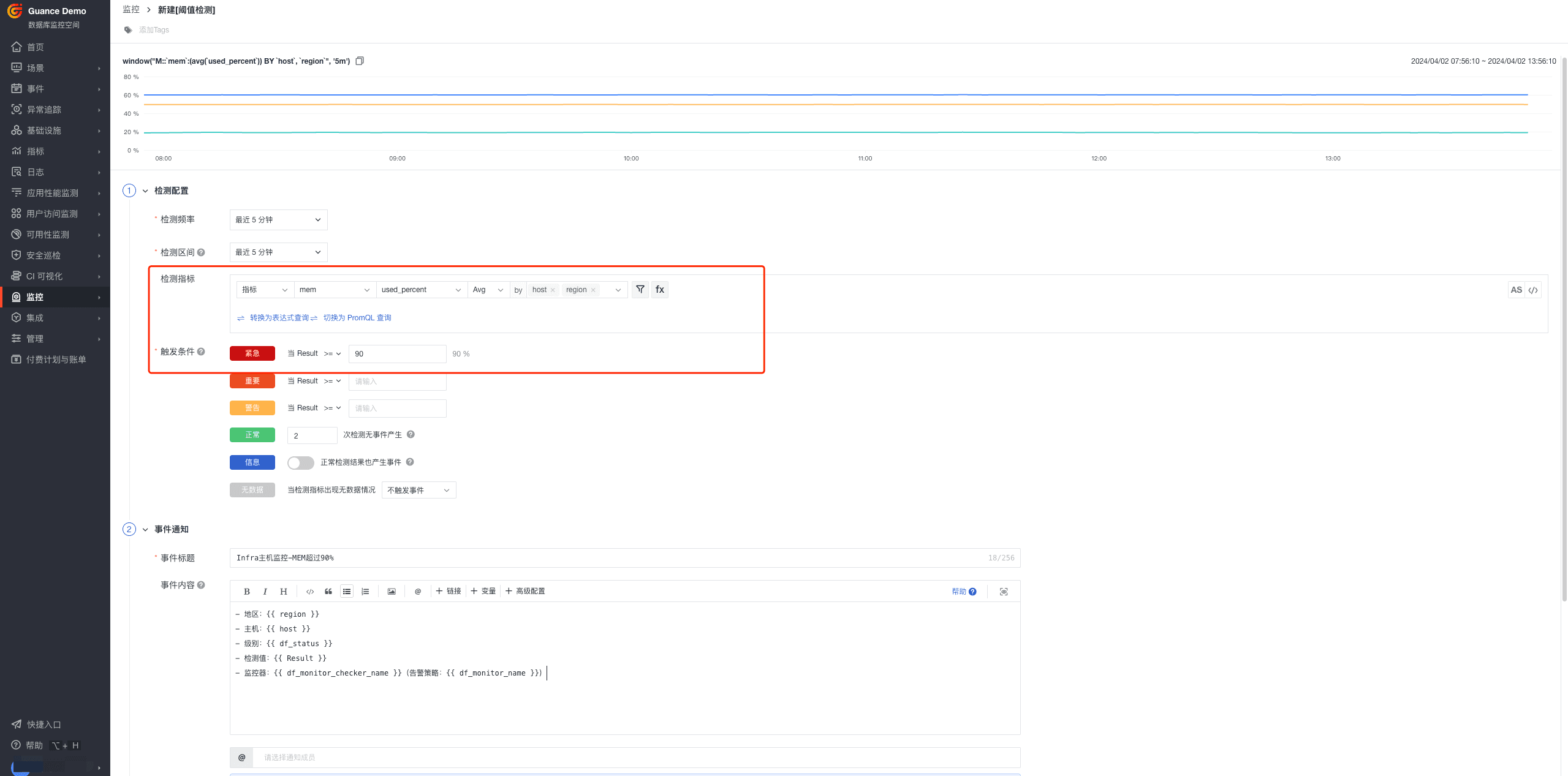
- 配置通知对象和告警规则,并保存
步骤三:新建组合监测
上两个步骤操作完之后,有两个监控器已经创建。

- 监控器 > 新建监控器 > 组合检测
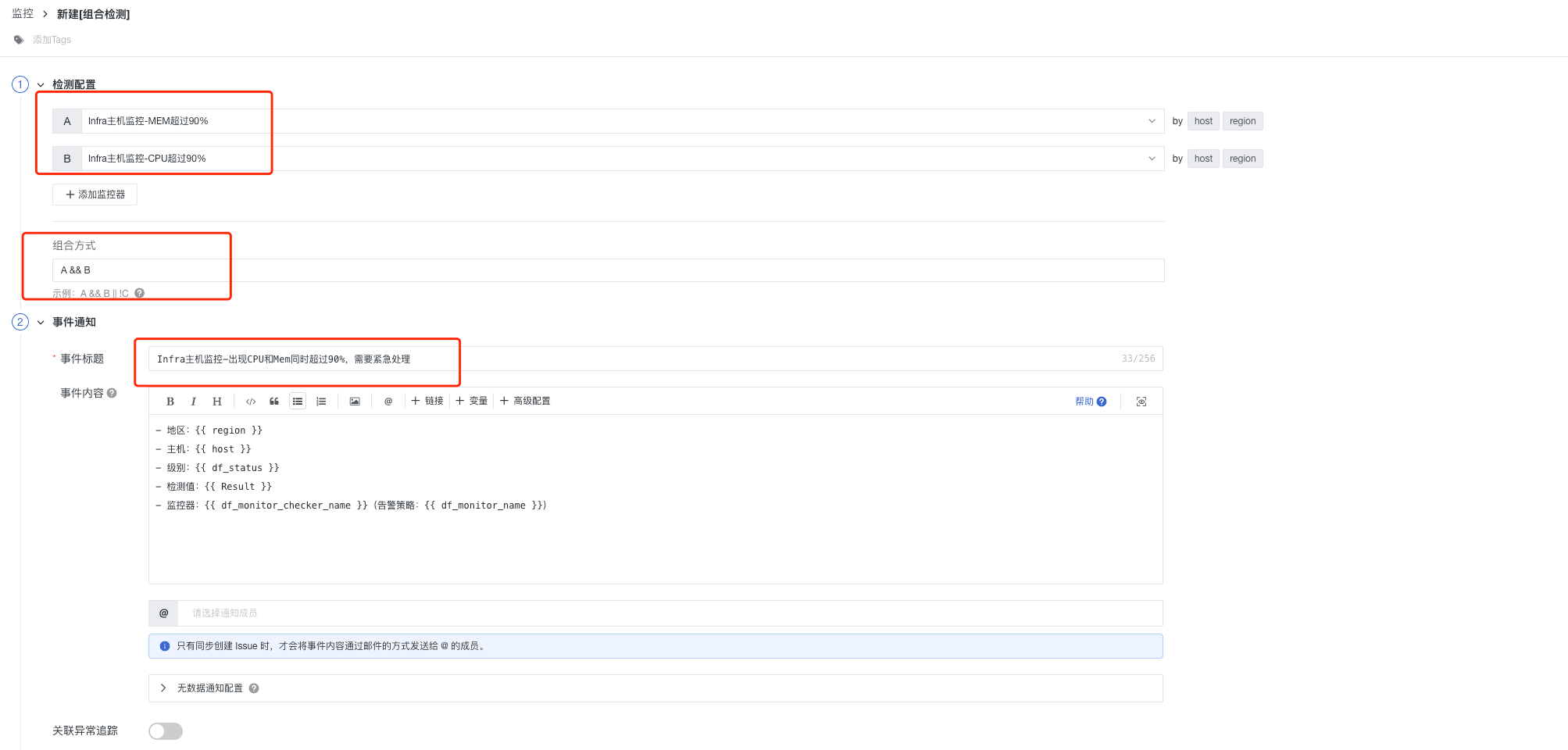
- 配置接收人为钉钉一线运维团队,并保存

步骤四:完成组合监测告警

步骤五:结果展示
提示:为及时展示出效果,这里将阈值将 90% 调整为 1% 。
1)在观测云控制台效果展示
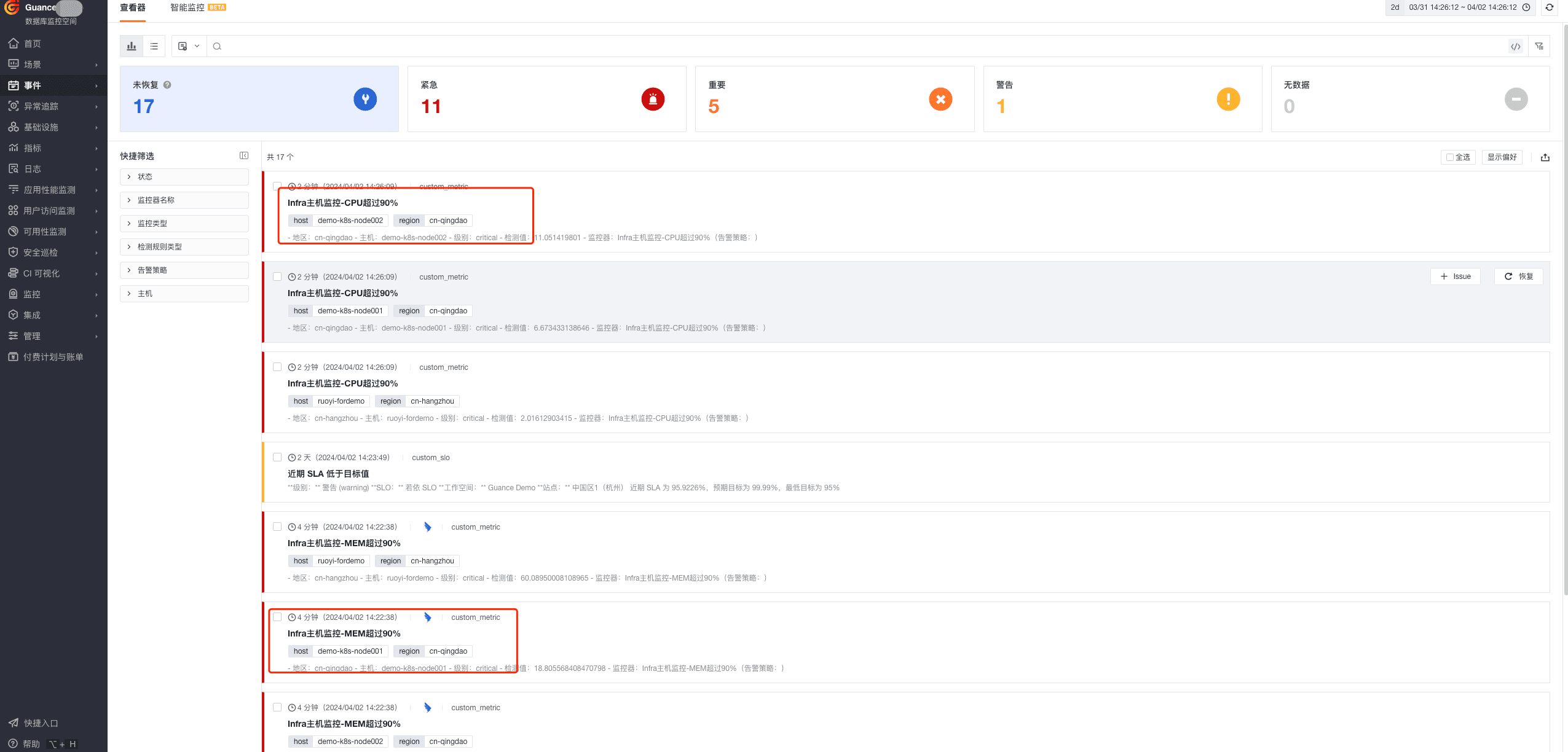
- Infra 主机监控-CPU 超过 90%
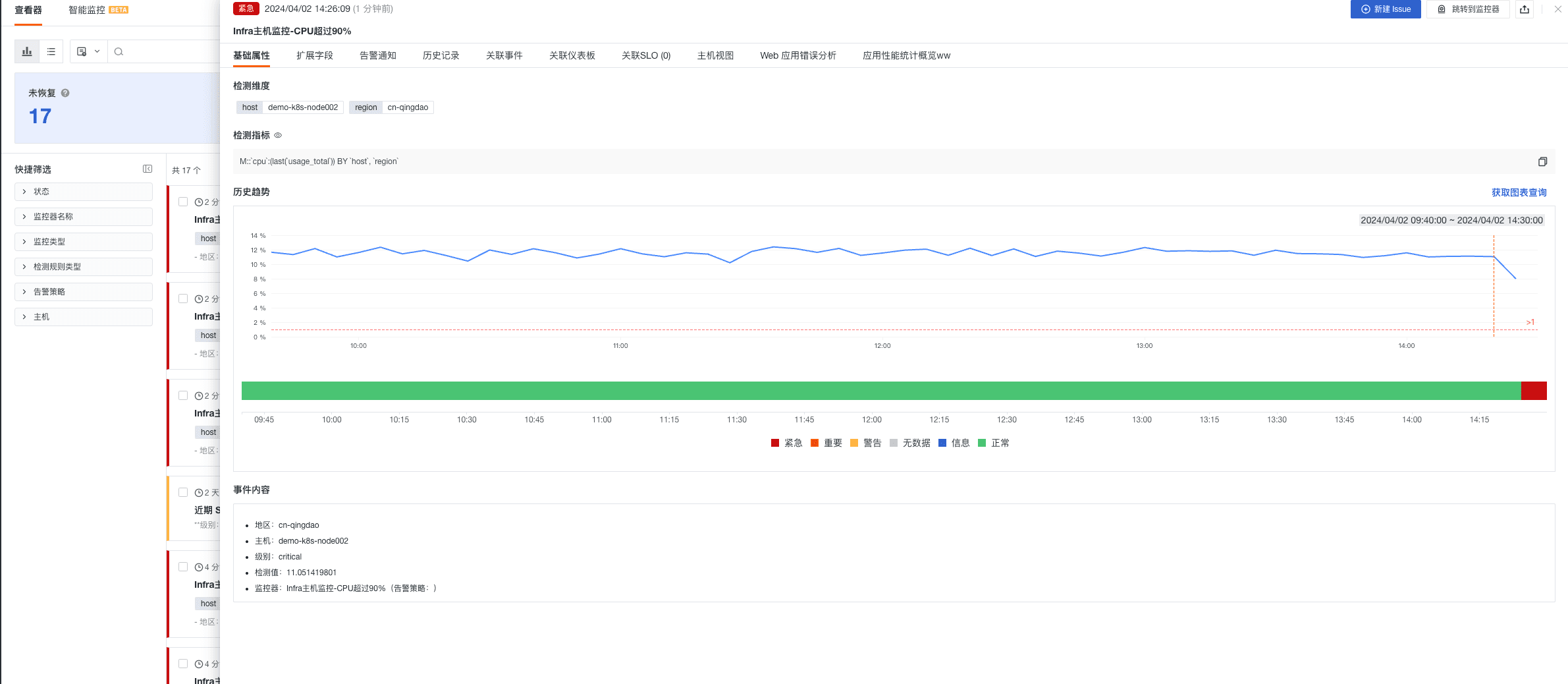
- Infra 主机监控-MEM 超过 90%
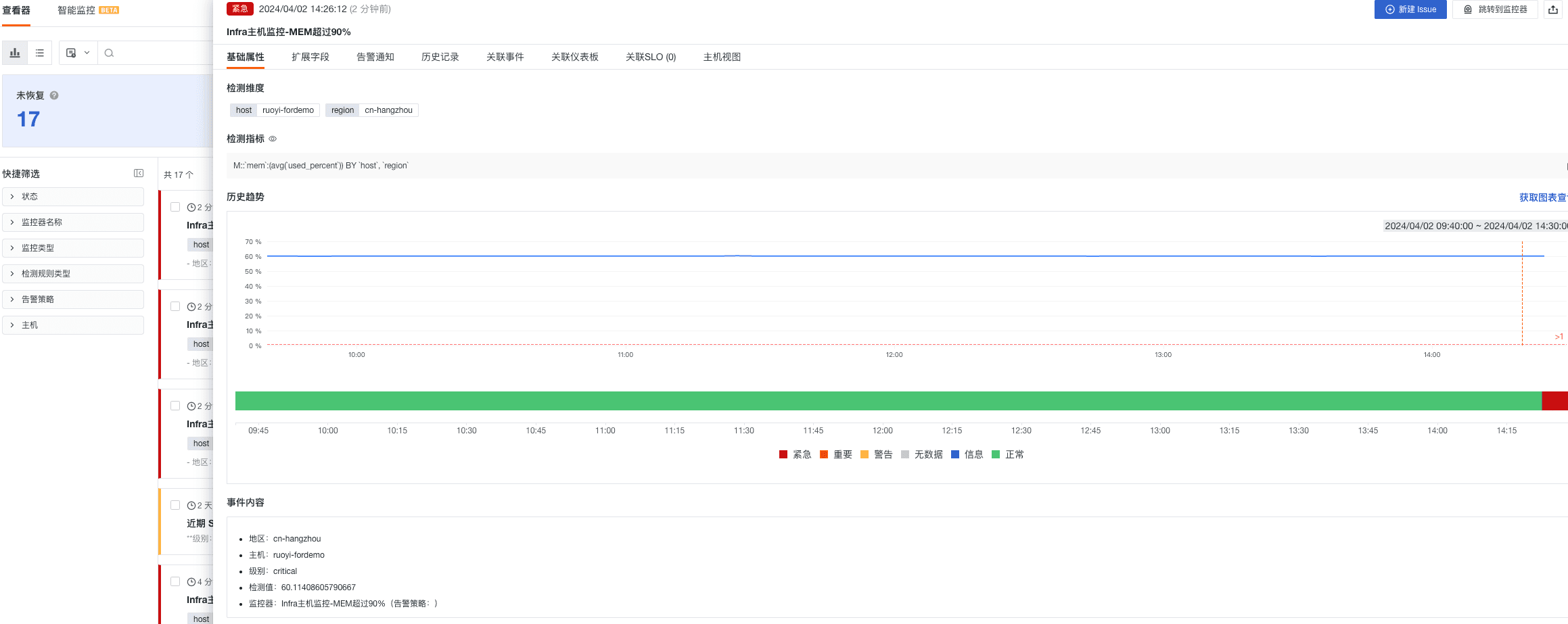
- 组合监控 Infra 主机监控-出现 CPU 和 Mem 同时超过 90%
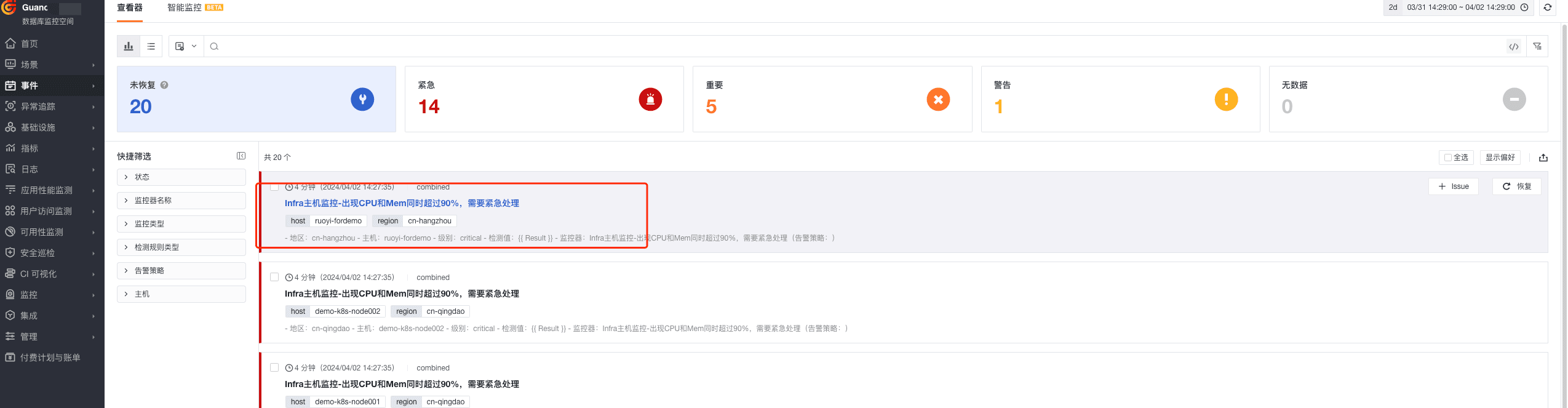

- 关联仪表板
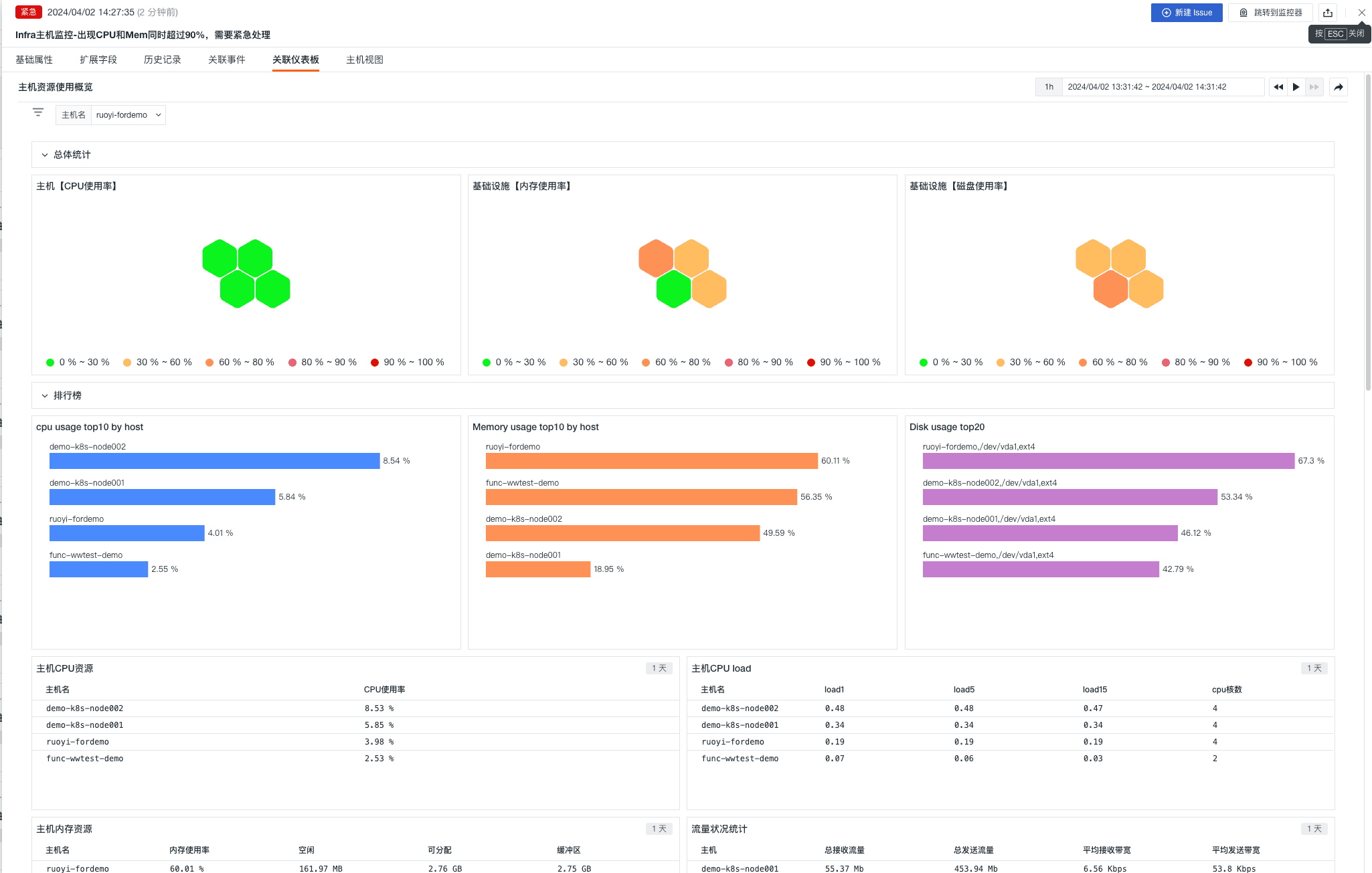
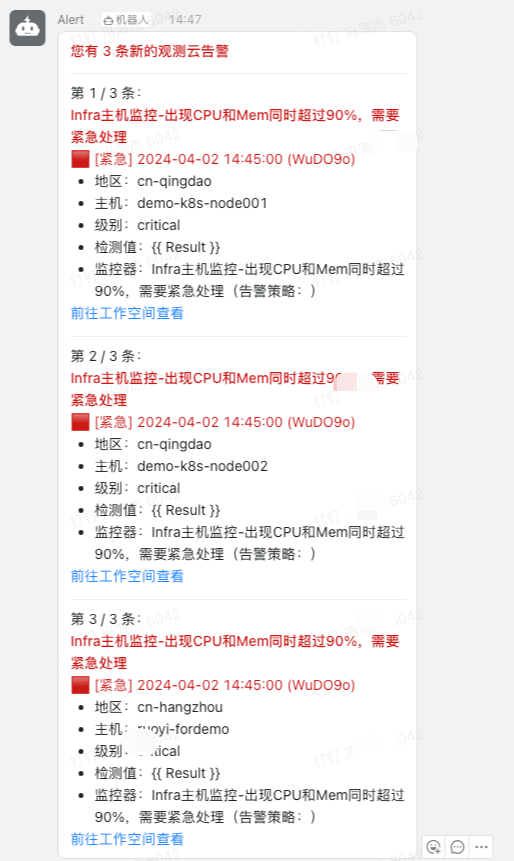
2)在钉钉 webhook 效果展示
- Infra 主机监控-CPU 超过 90%

- Infra 主机监控-MEM 超过 90%

- 组合监控 Infra 主机监控-出现 CPU 和 Mem 同时超过 90%
场景二:精准监控 APM 应用链路性能
监控 APM 应用链路性能组合监测中,开发工程师也是需要设置一些优先级最高的告警,比如当监测链路请求的 P99 延迟,那么如果请求数比较少,直接配置告警,会出现误报现象,那么这个单个监控是没有价值的,所以组合监控方案中:将请求数和 P99 延迟进行组合,当请求量满足阈值(大于 100),而且 P99 延迟大于设定阈值,立刻告警,通知一线开发,告警升级,紧急修复,达到精准监控的效果,设置主要分以下几步骤:
步骤一:新建 APM-请求数监控器
- 监控器 > 新建监控器 > 应用性能检测
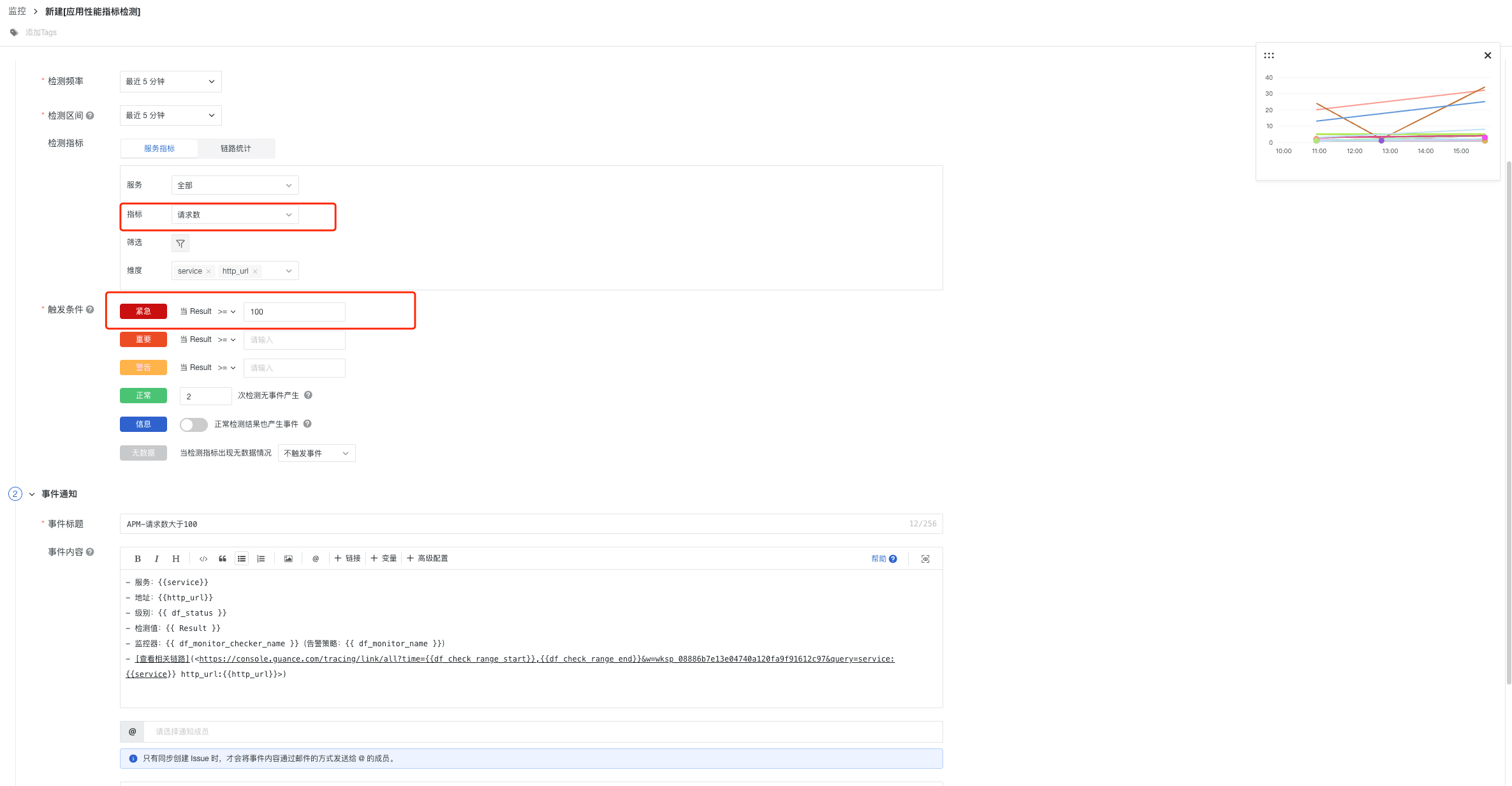
- 配置通知对象和告警规则,并保存

步骤二:新建 APM-P99 监控器
- 监控器 > 新建监控器 > 应用性能检测

- 配置通知对象和告警规则,并保存

步骤三:新建组合监测
上两个步骤操作完之后,有两个监控器已经创建。

- 监控器 > 新建监控器 > 组合检测
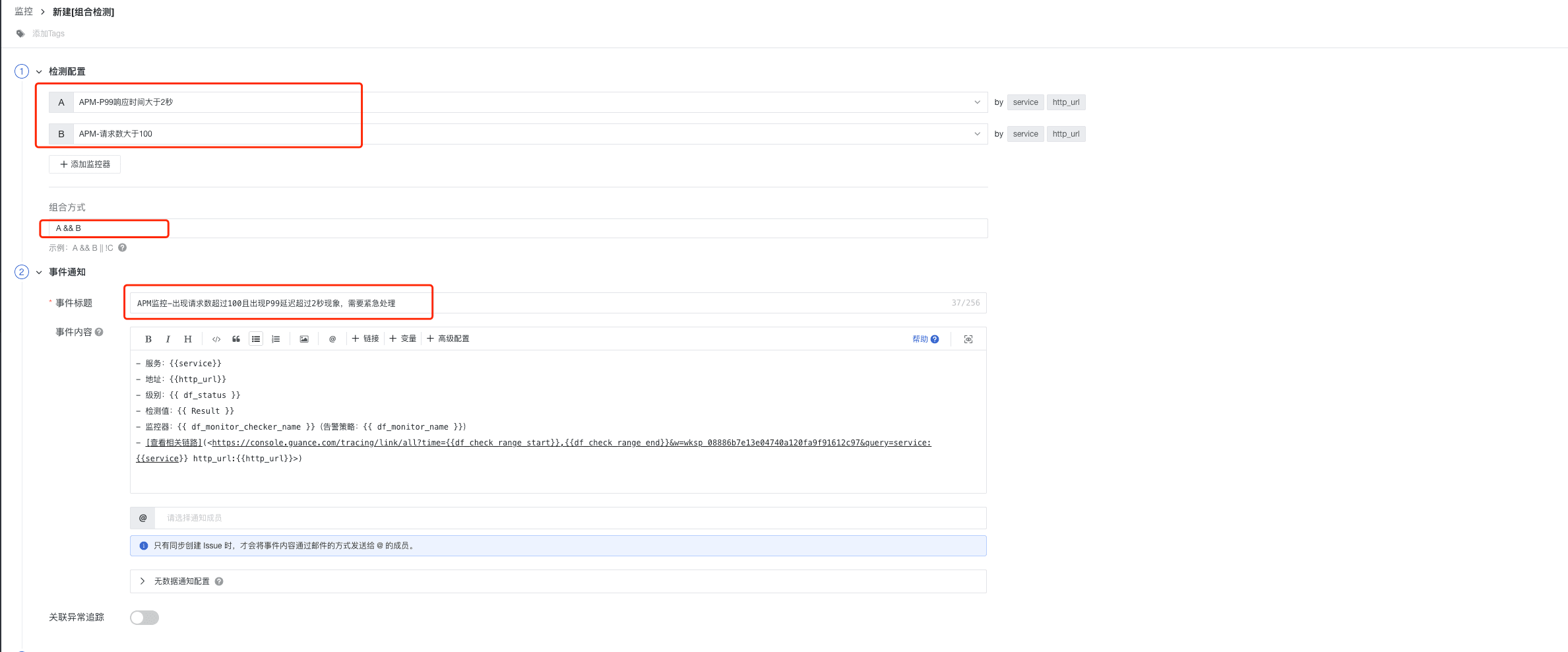
- 配置接收人为钉钉一线运维团队,并保存

步骤四:完成组合监测告警

步骤五:结果展示
提示:为及时展示出效果,这里将阈值将请求数字 100 调整为 10,P99 响应耗时阈值改为 200ms 。
1)在观测云控制台效果展示
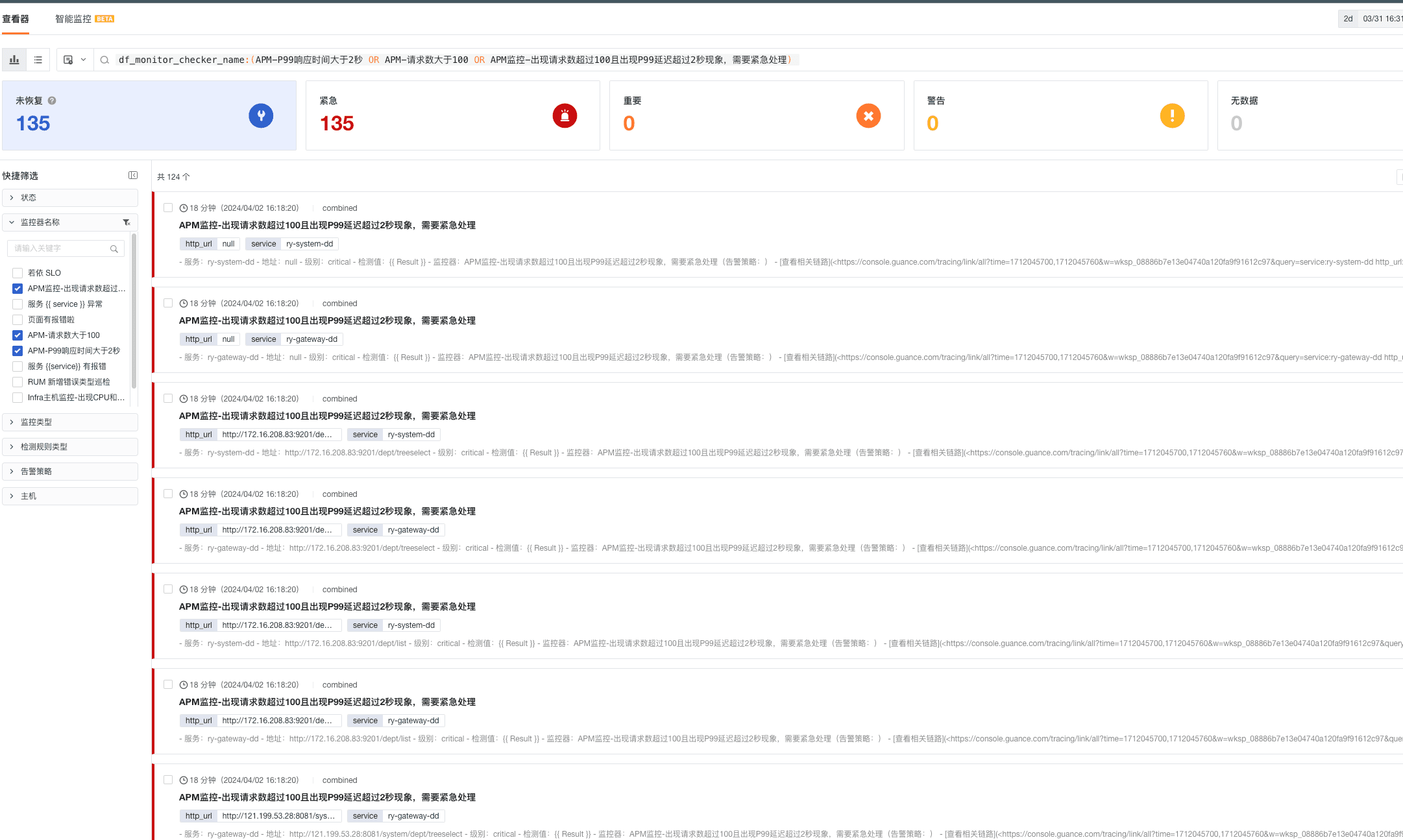
- APM-请求数大于 100
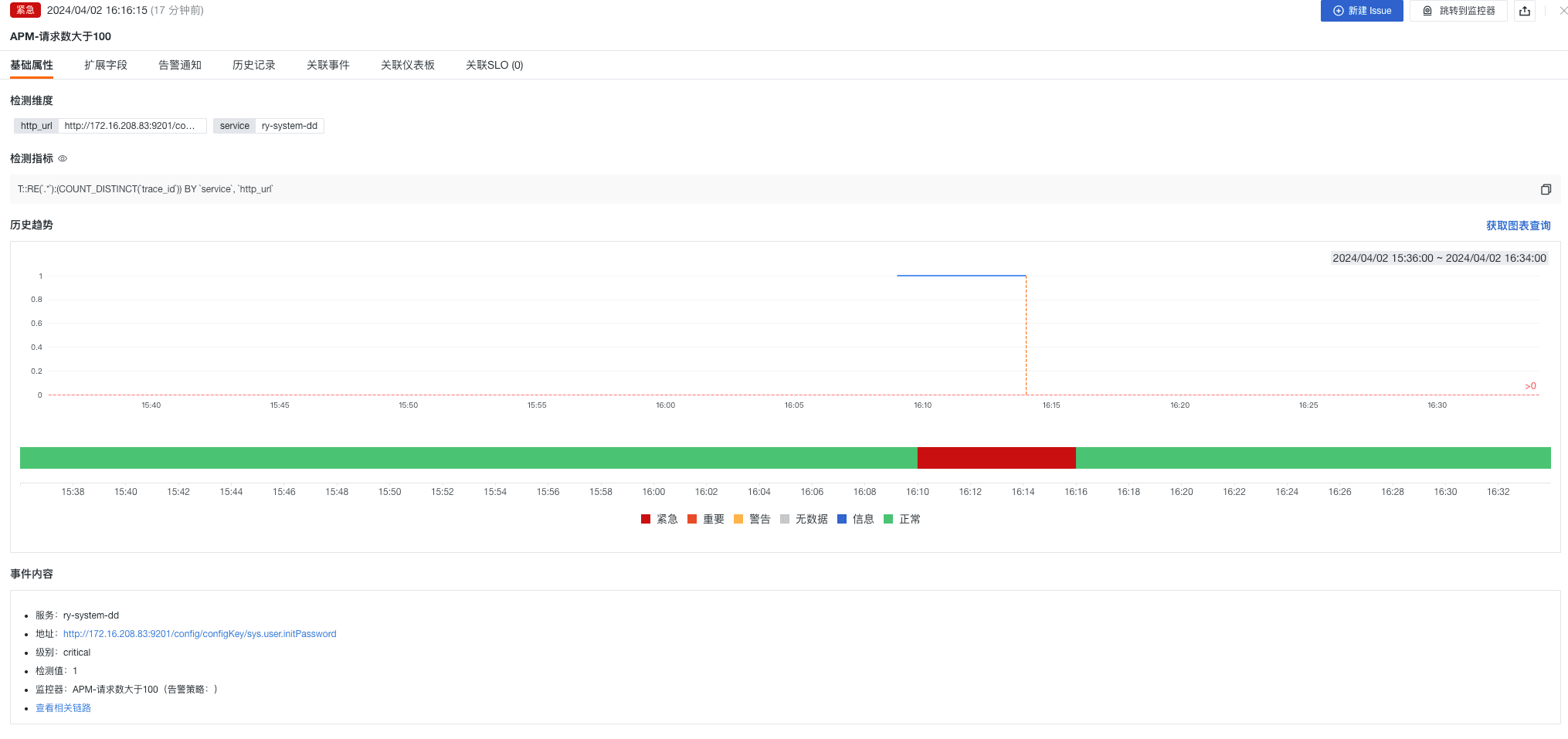
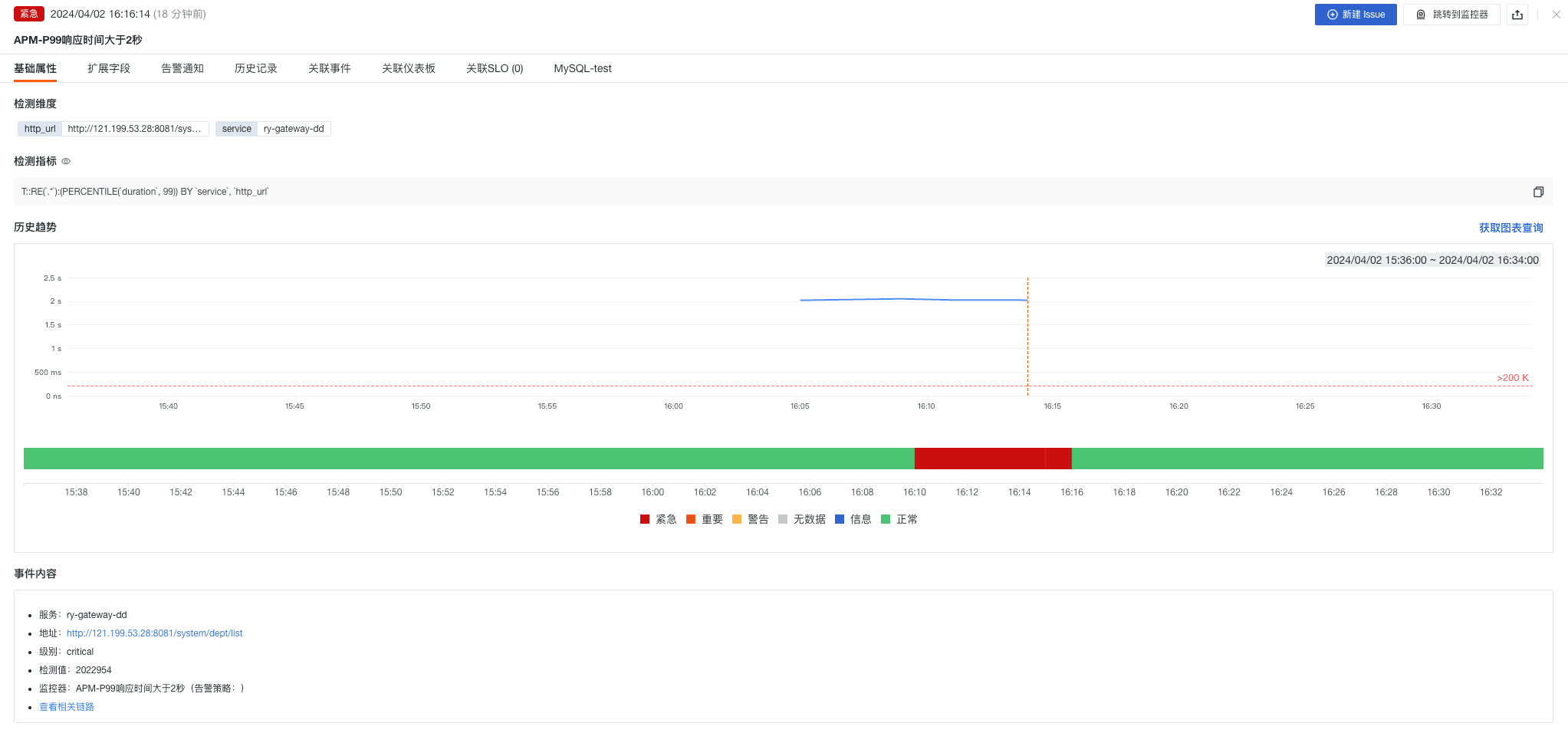
- APM-P99 响应时间大于 2 秒
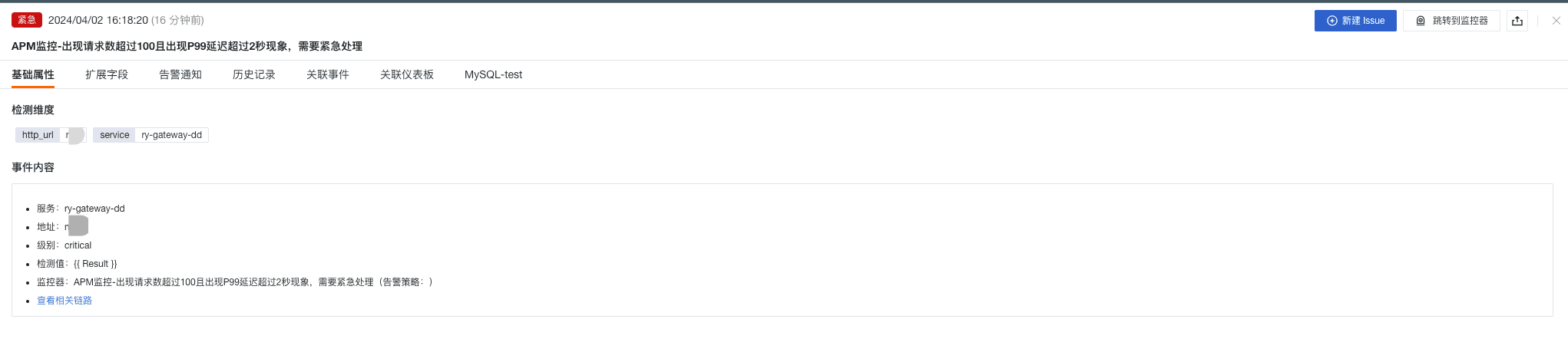
- APM 监控-出现请求数超过 100 且出现 P99 延迟超过 2 秒现象,需要紧急处理
2)在钉钉 webhook 效果展示
- APM-请求数大于 100

- APM-P99 响应时间大于 2 秒

- APM 监控-出现请求数超过 100 且出现 P99 延迟超过 2 秒现象,需要紧急处理

步骤六:可交互
- 关联仪表板
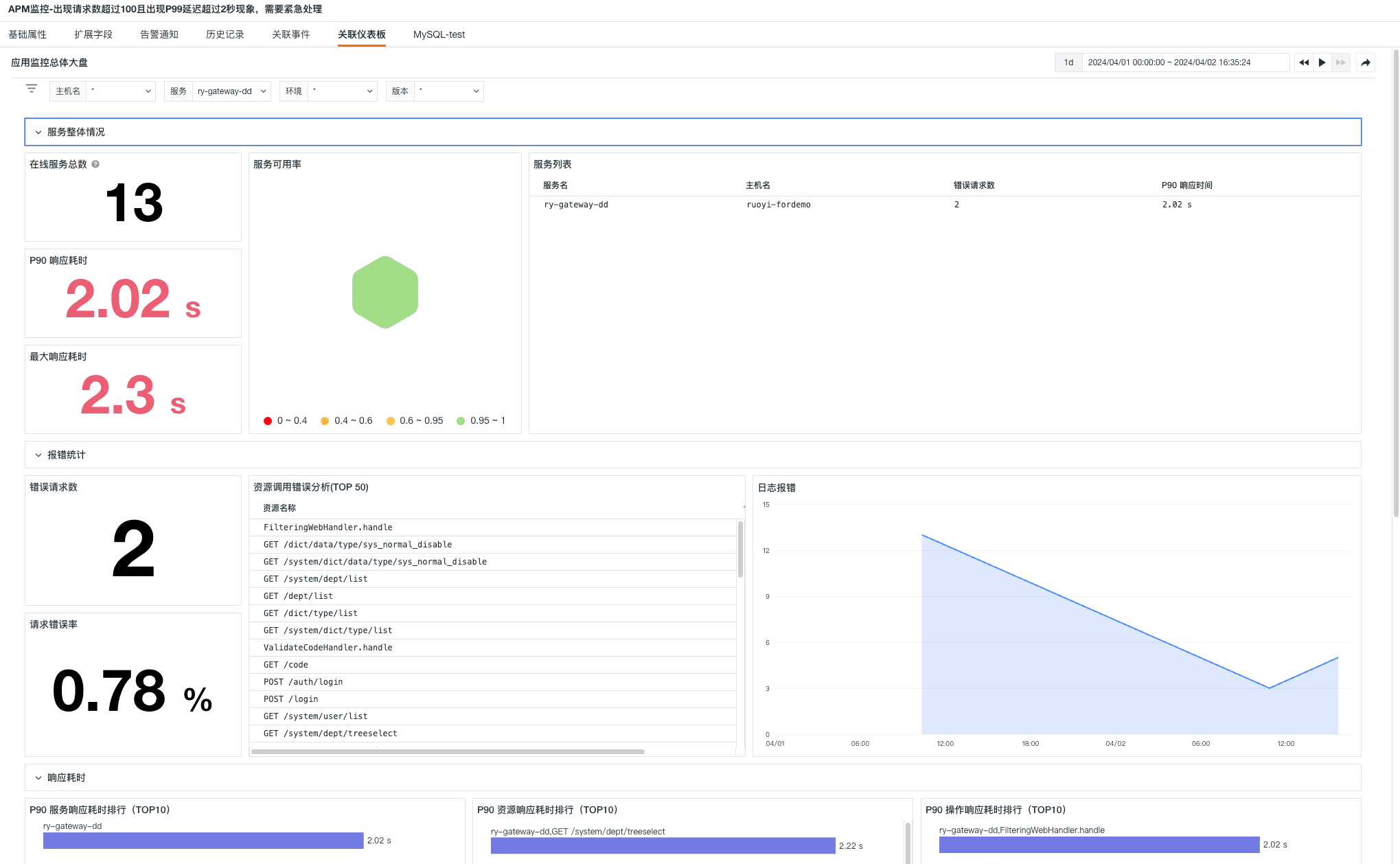
- 查看对应链路
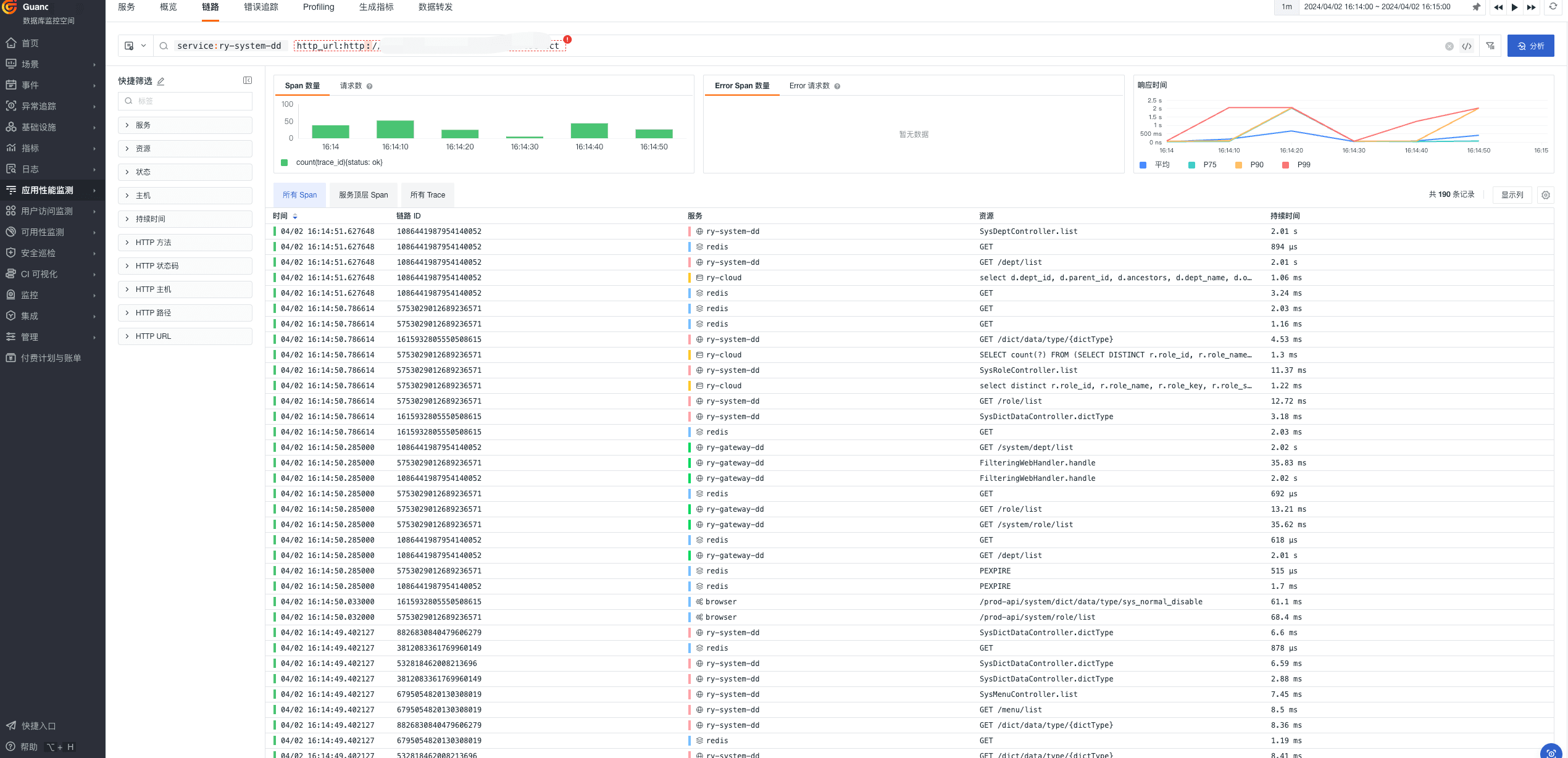
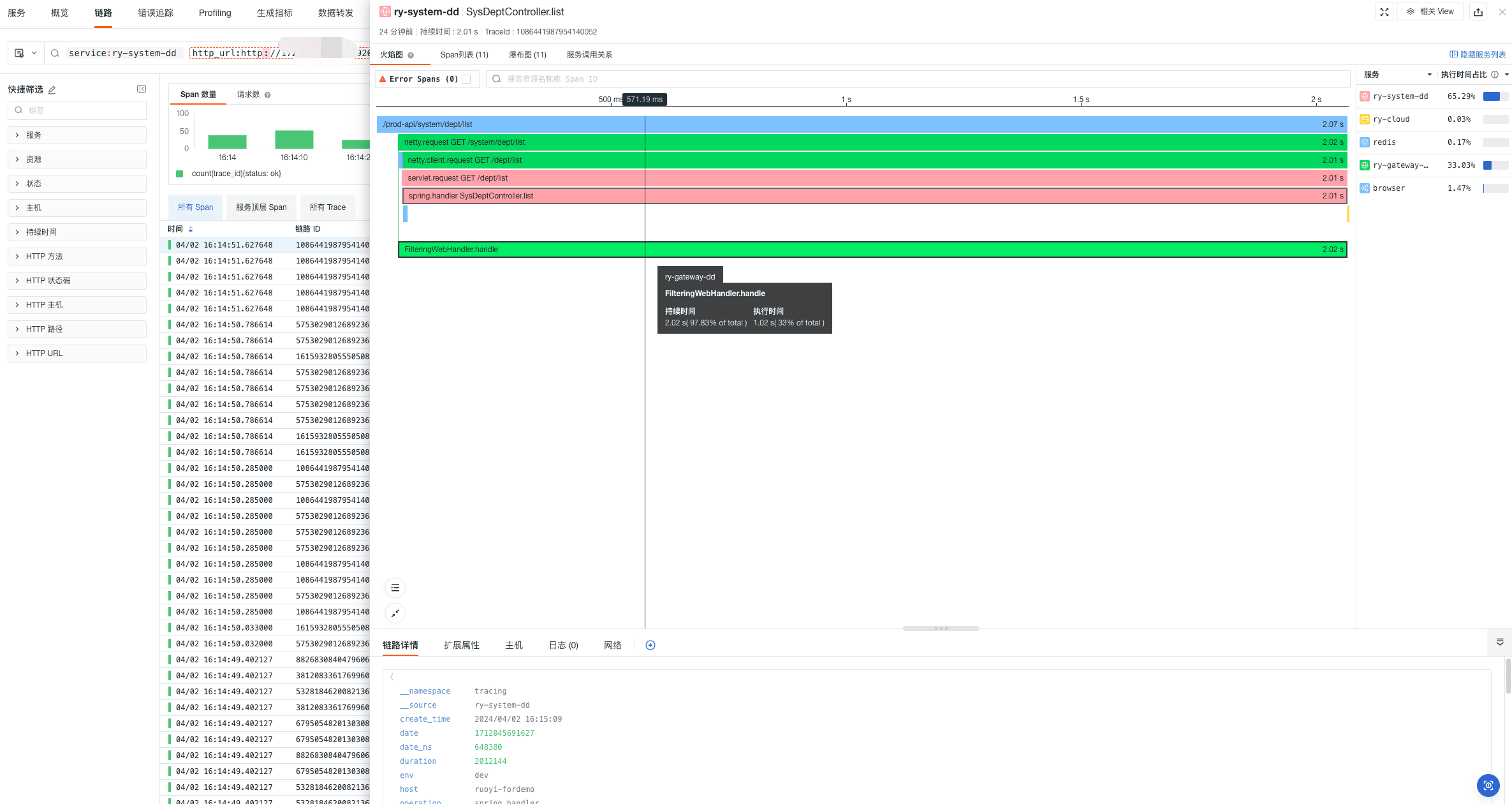
- 查看链路火焰图
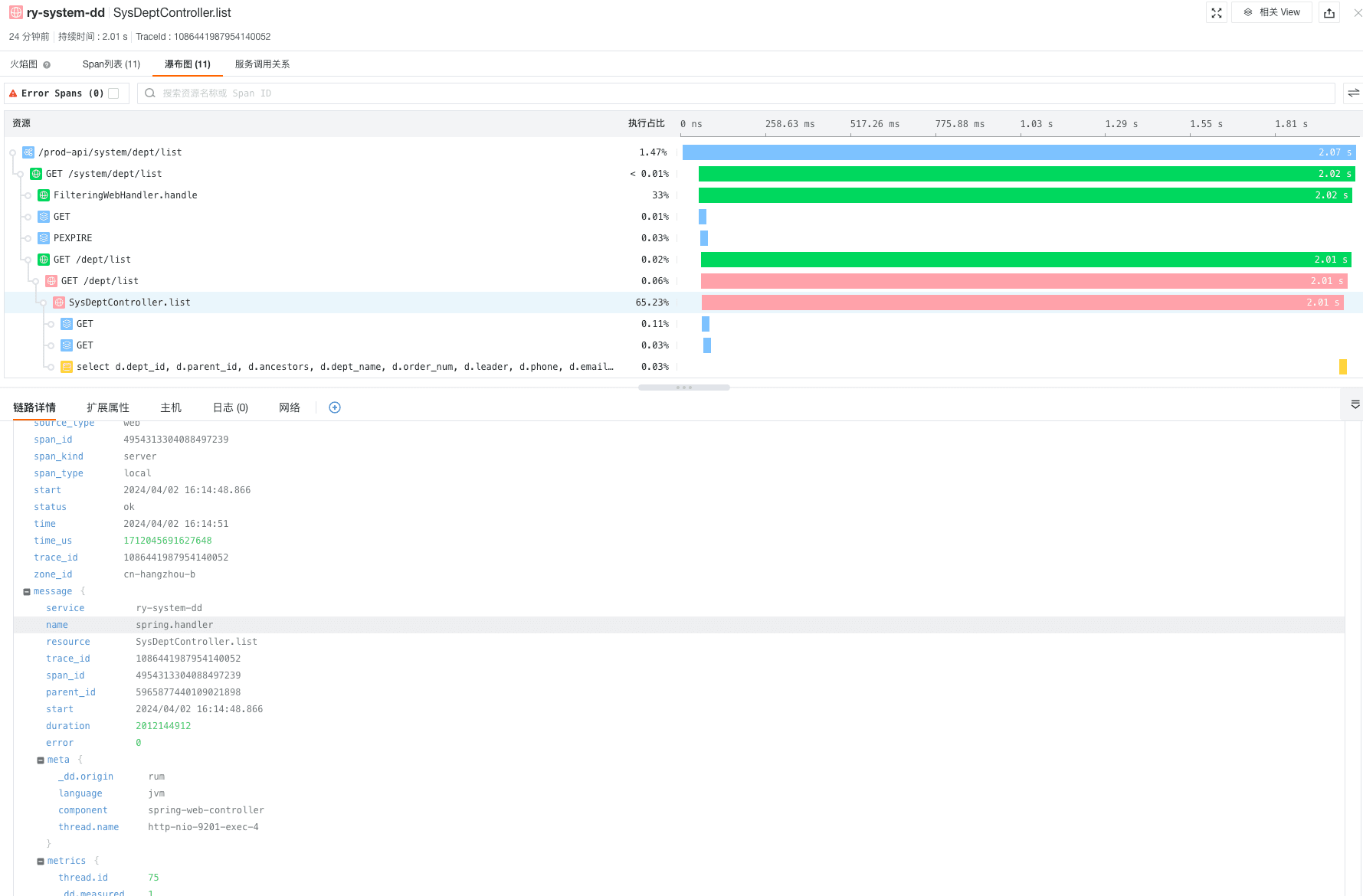
- 查看瀑布图
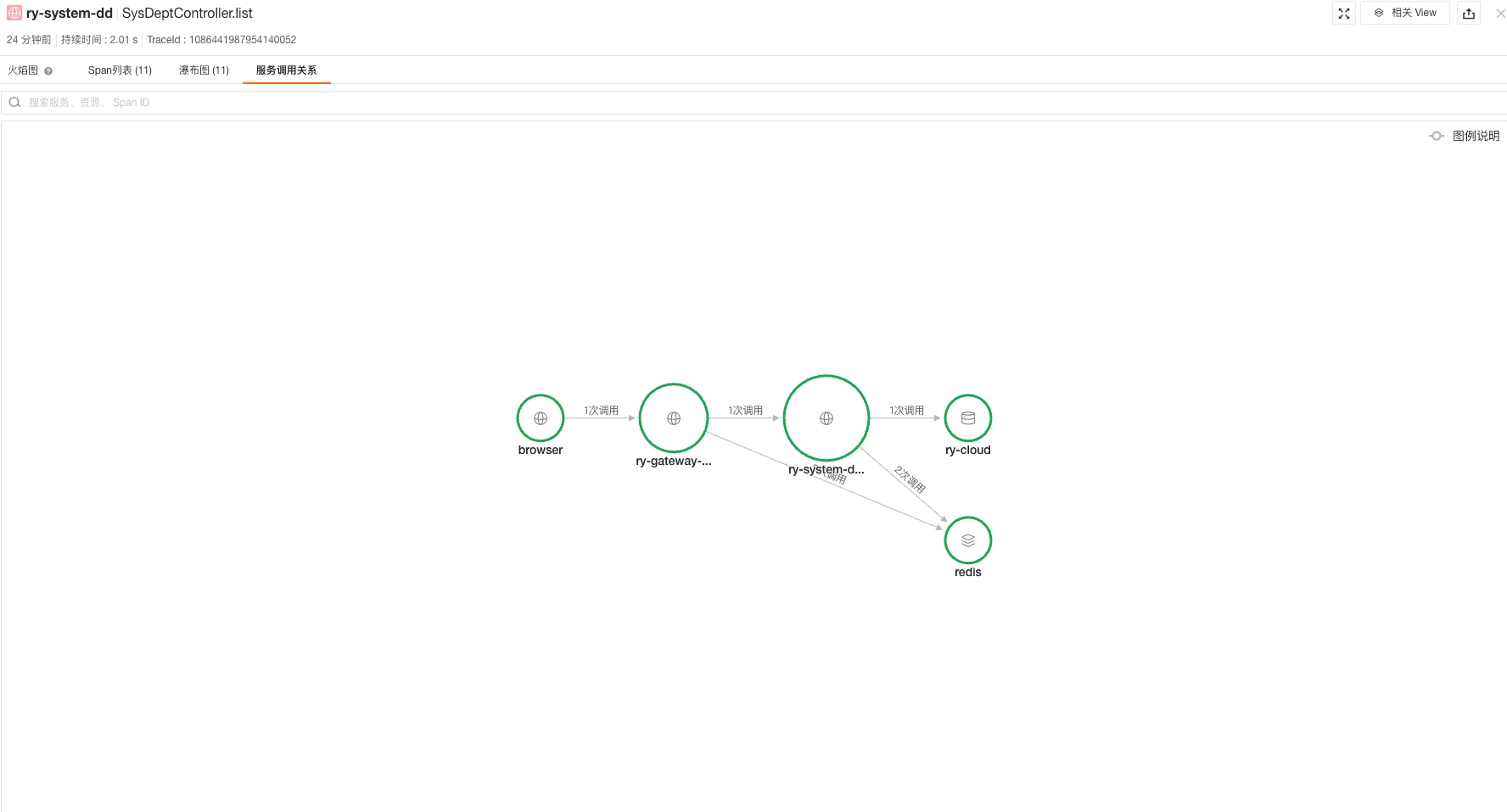
- 查看单次请求拓扑图
总结
组合监控只是可观测的一个功能,可观测性能够帮助我们更好地理解系统的运行情况,诊断和解决问题,提高软件工程质量;同时,使企业能够⽤真实数据更加了解业务,帮助企业在数字化转型中得到更多的数据助⼒,让技术为真正能为业务服务。


