










轻松实现自定义资源上报至观测云

概述
观测云的「资源目录」是基础设施监控和管理的核心功能之一,它允许用户通过创建自定义资源,结合属性、关联视图、JSON 文本等配置,向观测云上报任意数据。这些数据不仅包括传统的主机、容器、进程信息,还涵盖了云厂商的云资源数据、企业的各种业务数据以及其他任何需要观测的数据类型。「资源目录」的核心价值在于其灵活性和扩展性,使得用户能够将各种异构数据统一到一个平台进行可视化管理和关联分析。

「资源目录」解决的问题包括:
- 数据整合难题:在多云和混合IT环境中,资源目录能够整合来自不同源的数据,提供一个统一的视图来管理和监控这些资源。
- 自定义监控需求:不同的业务和应用可能需要监控特定的数据点。资源目录允许用户定义自己的资源和属性,满足个性化的监控需求。
- 资源管理和分析:用户可以通过资源目录查看器模板对数据进行查看和分析,提高资源管理的效率和效果。
本文将以阿里云 ECS 为例,向大家介绍如何使用「资源目录」这一功能。「资源目录」数据上报需要先安装并连通 DataKit(观测云的统一数据采集器)和 DataFlux Func(观测云的数据处理开发平台),再通过 DataFlux Func 上报数据到 DataKit,最终 DataKit 上报数据到观测云工作空间。
准备工作
- 您需要拥有一个观测云账号,登录 https://www.guance.com/ 即可进行免费注册;
- 准备两台 ECS 或虚拟机,分别用于安装观测云 DataKit 和 Dataflux Func。本文所使用的资源如下:
| 资源类型 | 主机别名 | 硬件资源 | 操作系统 | 用途 |
|---|---|---|---|---|
| 阿里云ECS | node1 | 2C 4G | Ubuntu 22.04_x64 | 部署DataKit,用于接收自定义资源并上报到观测云工作空间 |
| 阿里云ECS | node2 | 2C 8G | Ubuntu 22.04_x64 | 部署DataFlux Func,用于上报自定义资源 |
- 在您的云账号下有云资源实例,并需要具备相应权限的 AK/SK 。
操作步骤
1. DataKit 安装
登录到观测云工作空间,点击「集成」-「DataKit」,复制第二步中的安装命令,并在 node1 机器上执行。
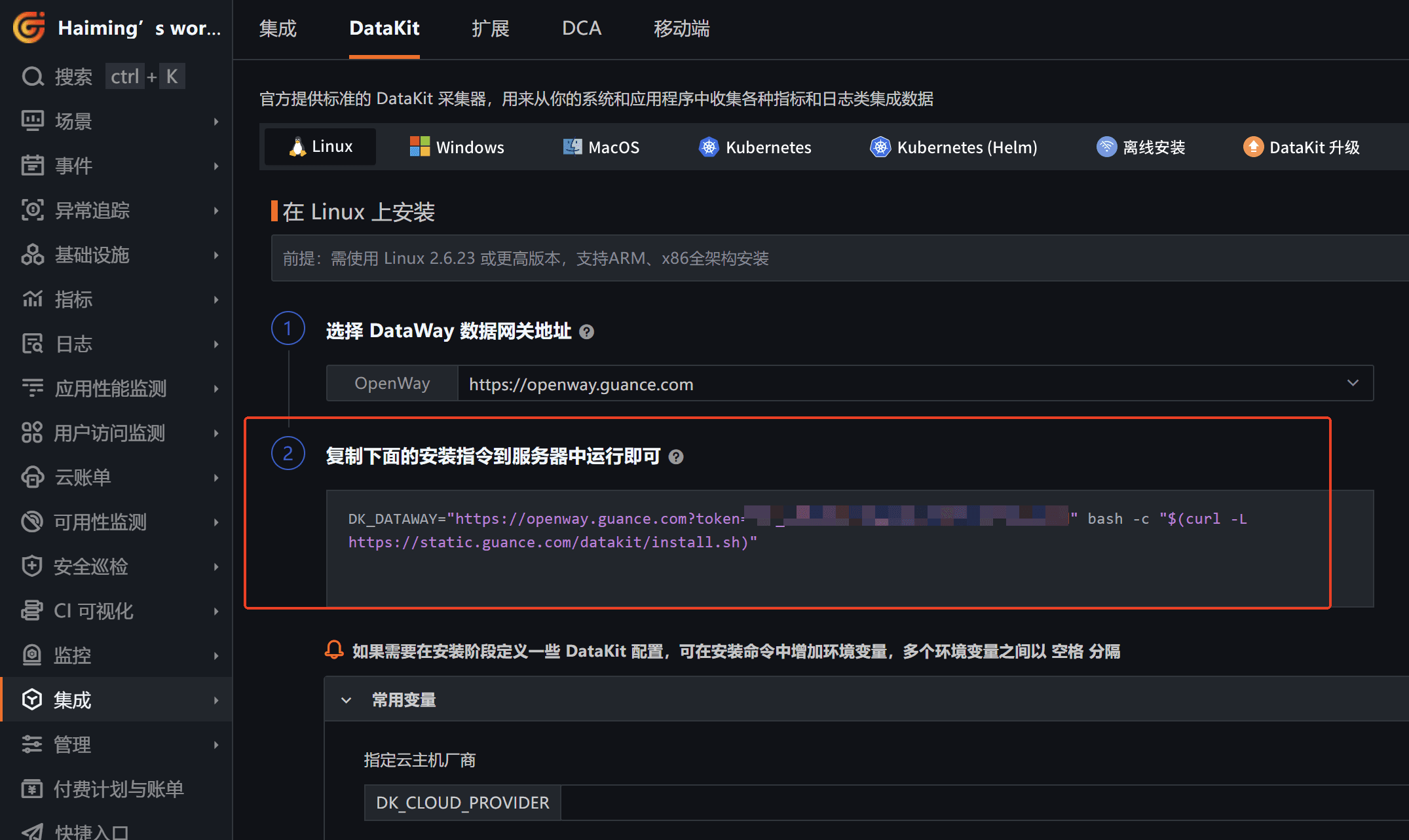
如下图,该命令可一键完成 DataKit 安装。
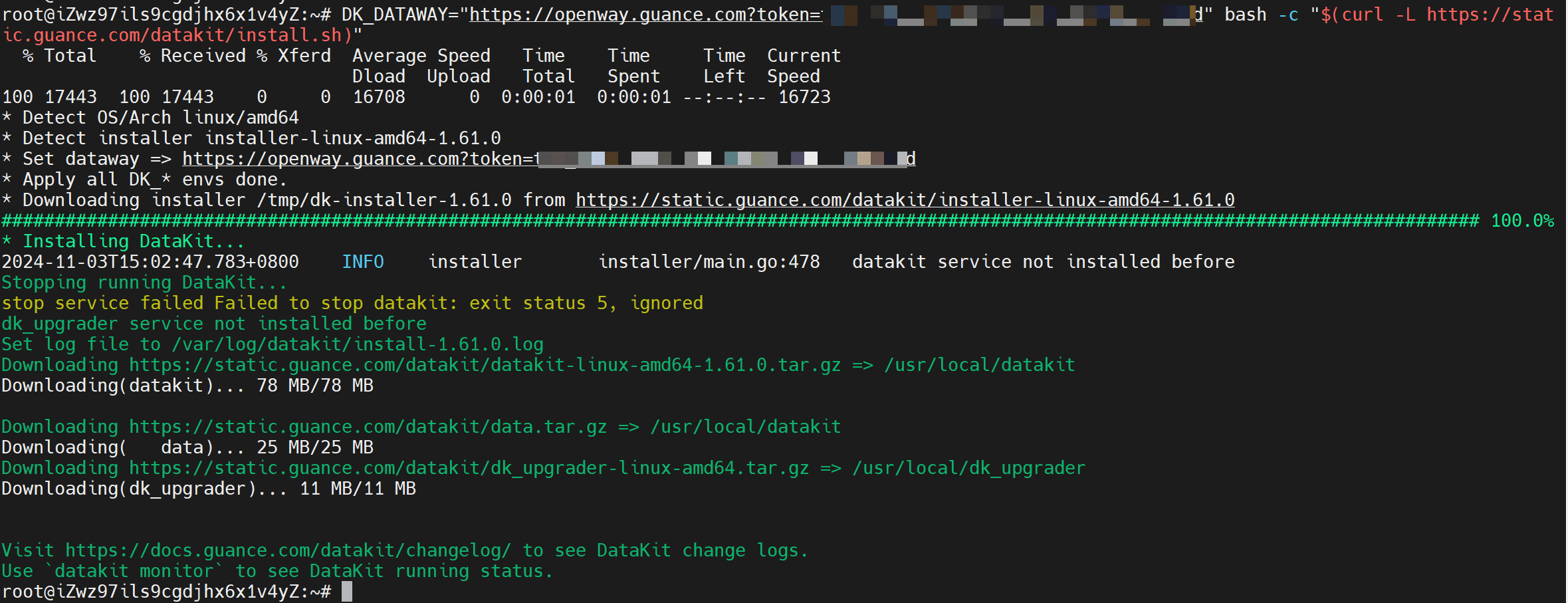
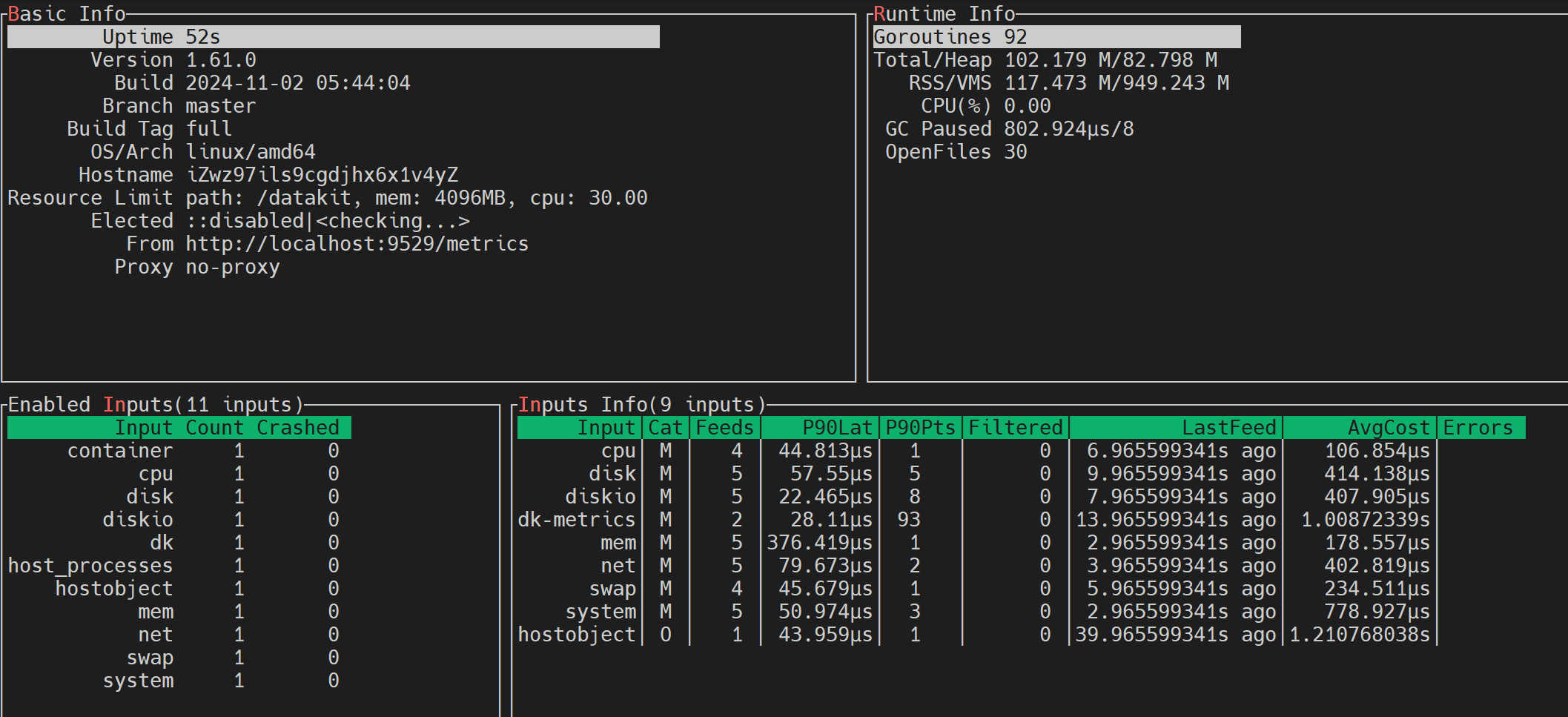
随后执行 datakit monitor 命令,如果出现以下界面,则说明 datakit 安装成功。
datakit monitor
DataKit 默认允许只接收 localhost 的数据,为了允许 Func 通过 DataKit 上报「资源目录」数据,我们需要在 DataKit 上放开监听。
找到 /usr/local/datakit/conf.d/datakit.conf 配置文件,修改 [http_api] 中的 listen 字段,确保对 0.0.0.0:9529 进行监听。
[http_api]
rum_origin_ip_header = "X-Forwarded-For"
listen = "0.0.0.0:9529"
disable_404page = false
rum_app_id_white_list = []
public_apis = []
request_rate_limit = 20.0
timeout = "30s"
close_idle_connection = false
allowed_cors_origins = []
[http_api.tls]
cert = ""
privkey = ""
并执行 datakit service -R 重启生效。
datakit service -R
2. Func 安装及配置
2.1 Func 下载
访问 Func 产品的下载和安装页面,按照文档依次下载、安装 Func 观测云特别版(GSE版)。
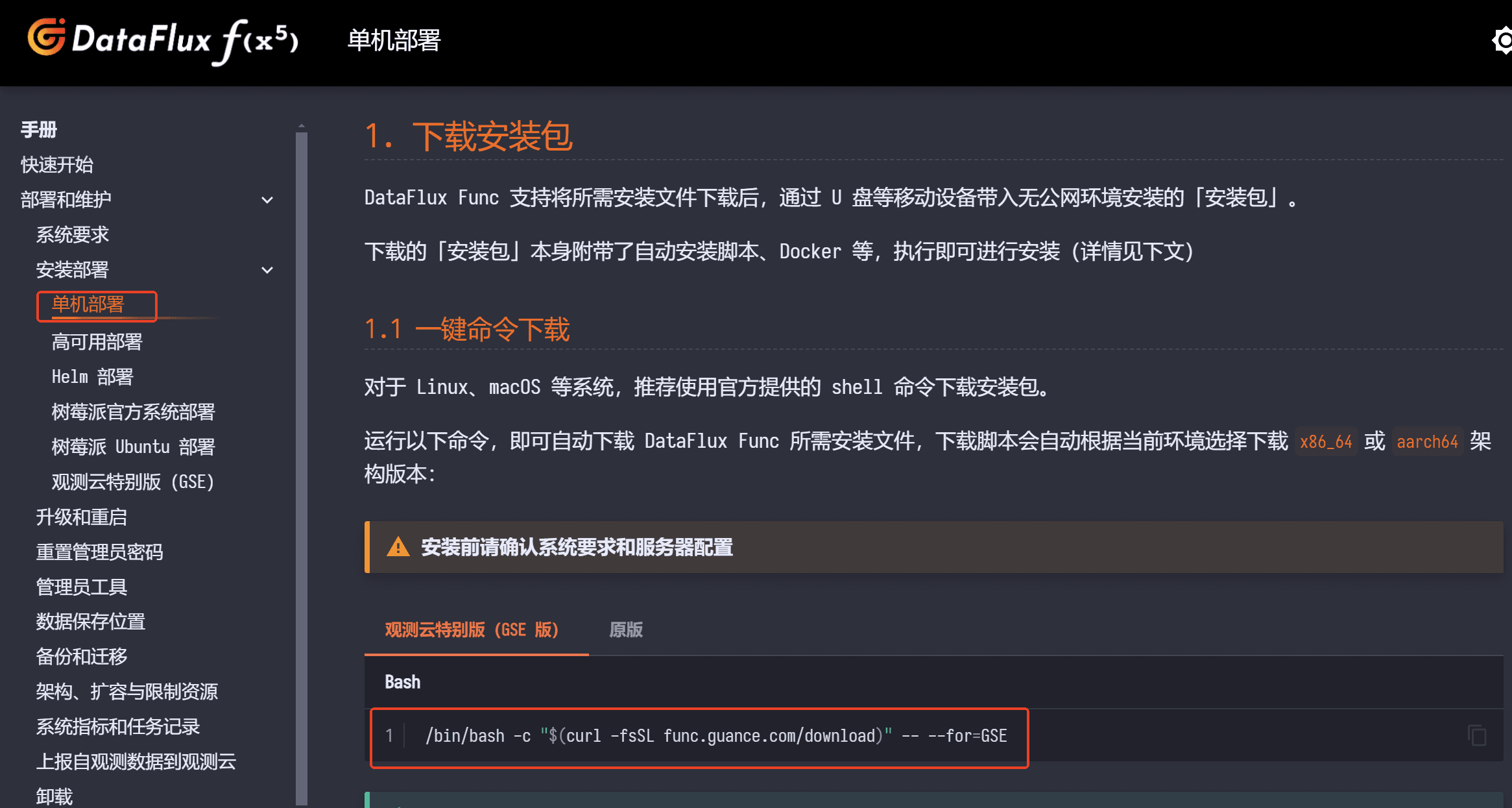
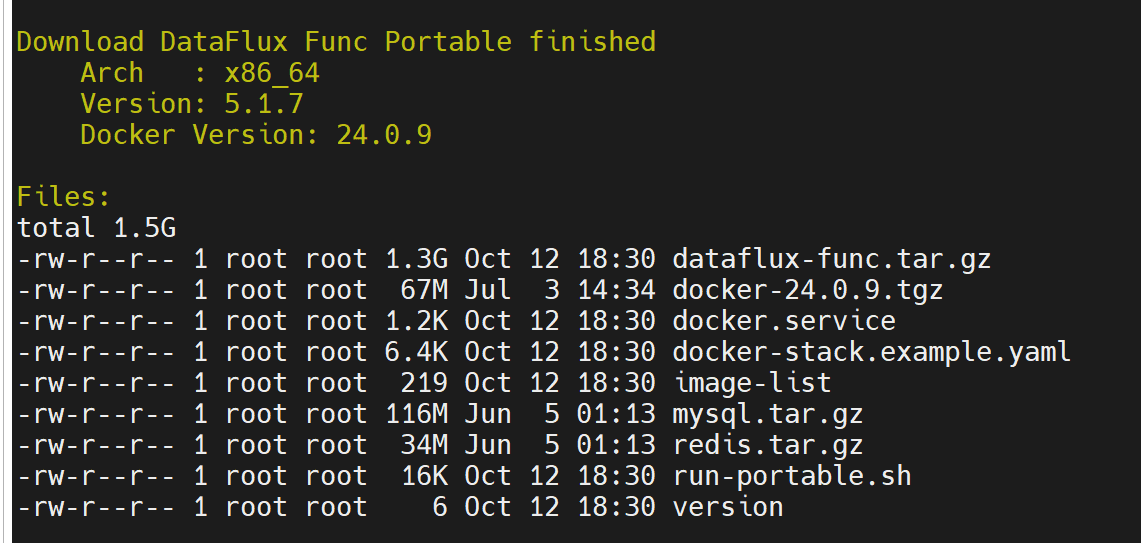
登录到 node2 执行如下命令,系统会自动下载:docker、mysql、redis、func 安装包等物料,完成后会有如下提示:
/bin/bash -c "$(curl -fsSL func.guance.com/download)" -- --for=GSE
2.2 Func 安装
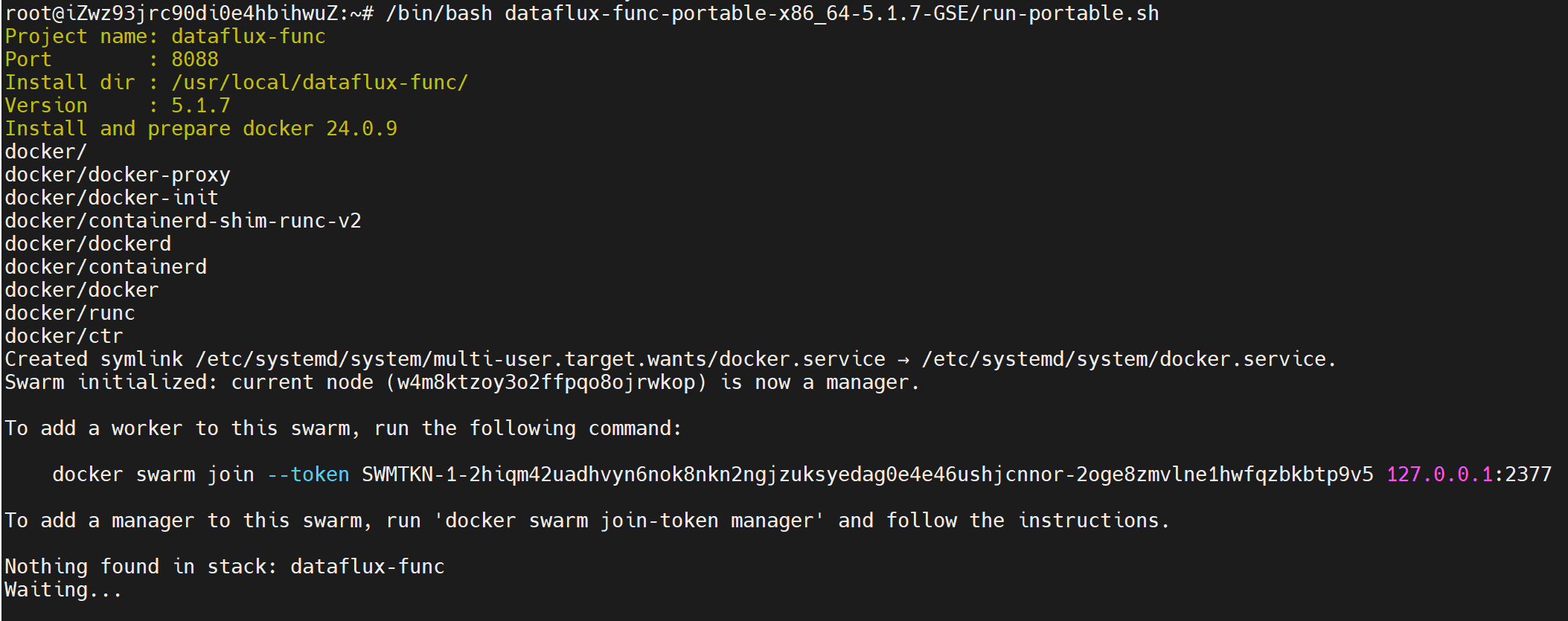
根据界面提示,我们继续执行安装步骤,执行如下命令:
/bin/bash dataflux-func-portable-x86_64-5.1.7-GSE/run-portable.sh
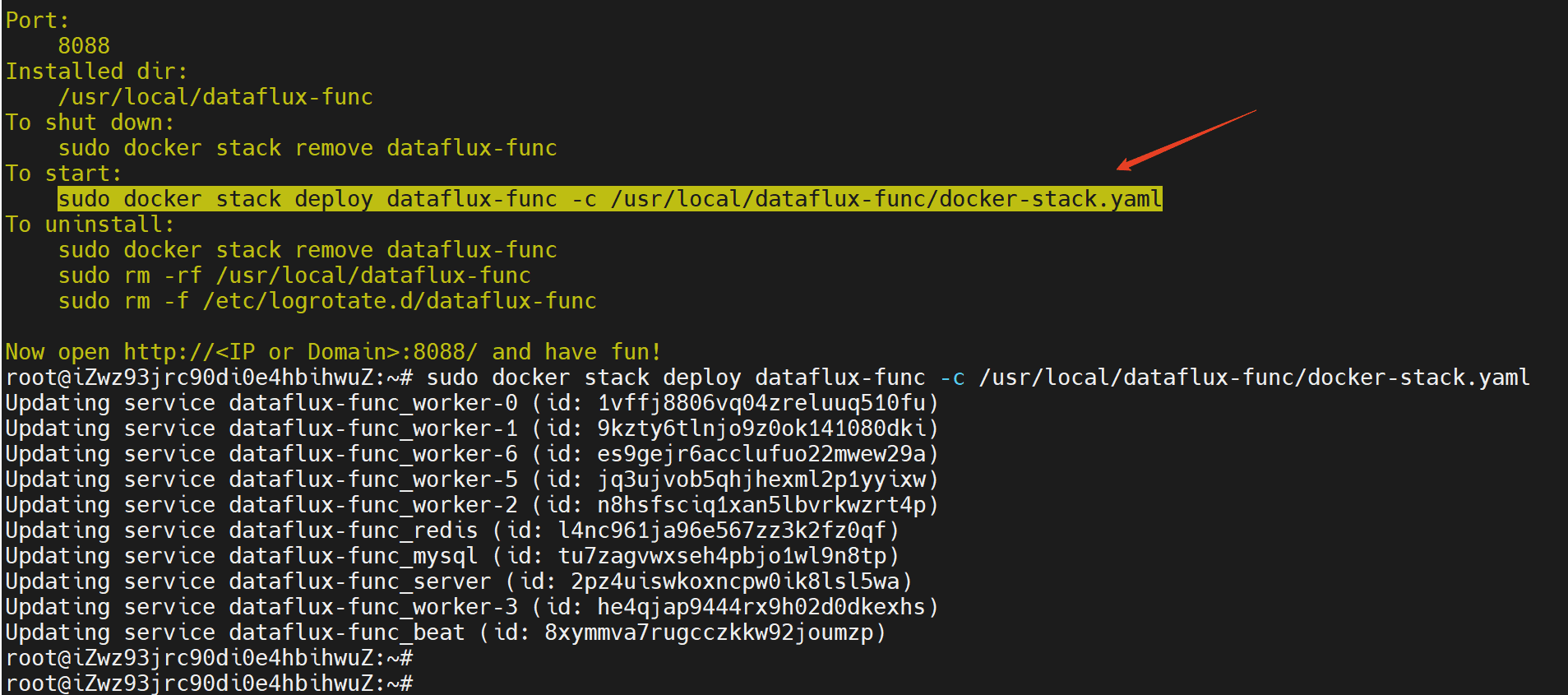
等待数分钟后,func 安装完成,会有如下提示,最后执行 docker stack deploy 命令启动服务。
sudo docker stack deploy dataflux-func -c /usr/local/dataflux-func/docker-stack.yaml
2.3 Func 初始化
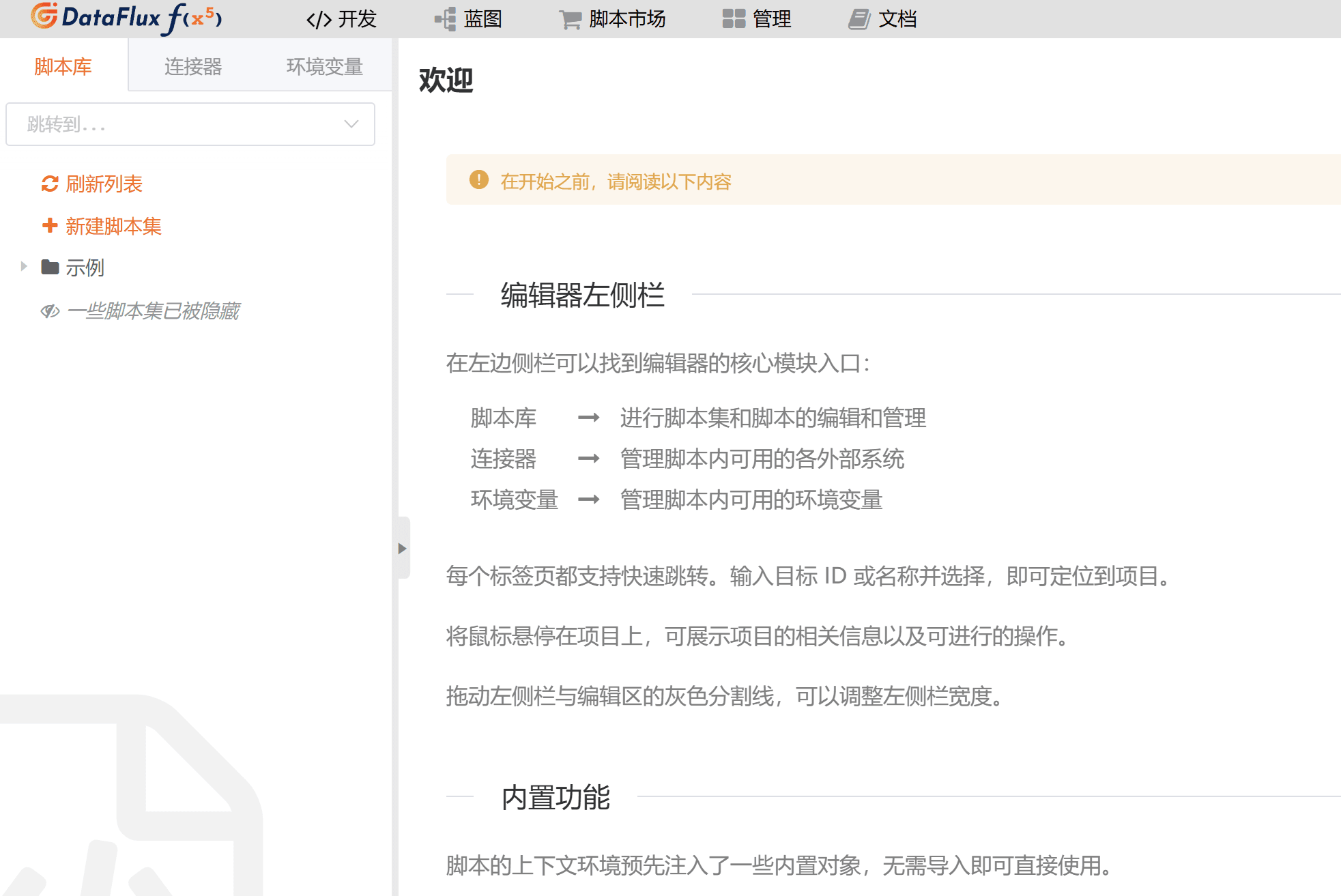
此时已经完成部署并可以访问 Func 的 web 页面了,可在浏览器输入 http://服务器IP地址:8088 ,点击保存并初始化数据库进行初始化。

随后输入管理员用户名、密码进行登录,进入到 Func 页面。
2.4 在 Func 上配置 DataKit 连接器
点击「连接器」-「添加连接器」,选择"观测云DataKit(HTTP)"类型,并输入 node1 的 IP ,由于在本文中的 node1 和 node2 在同一个 VPC ,因此使用内网进行通信,用户可根据实际的部署架构进行配置。
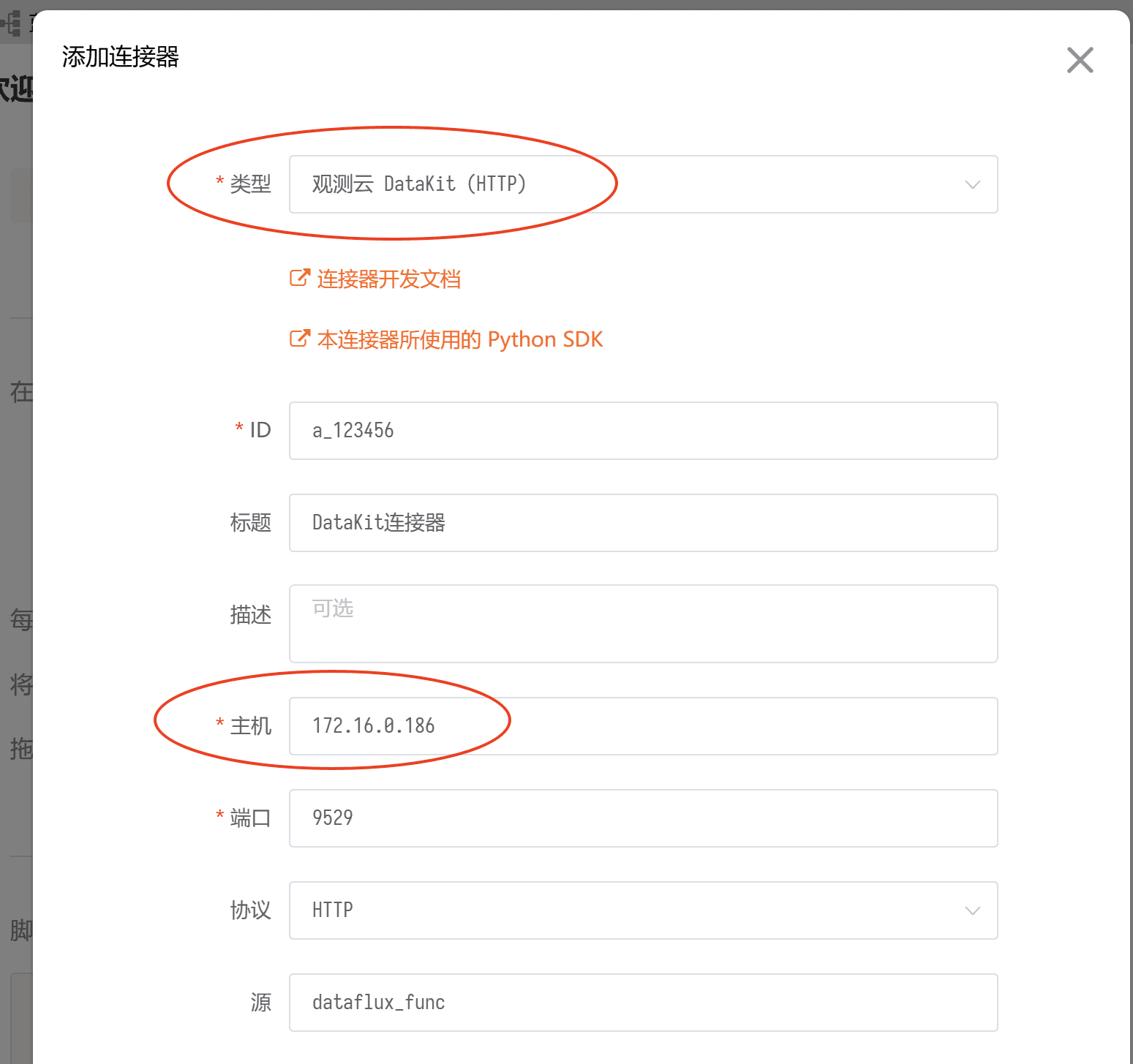
保存成功后可看到该连接器。
3. 自定义资源上报
3.1 安装阿里云 Python SDK
在「管理」-「实验性功能」-「PIP工具」界面,选择"阿里云镜像",复制 aliyun-python-sdk-core 到空白行,并点击安装,如下图所示:
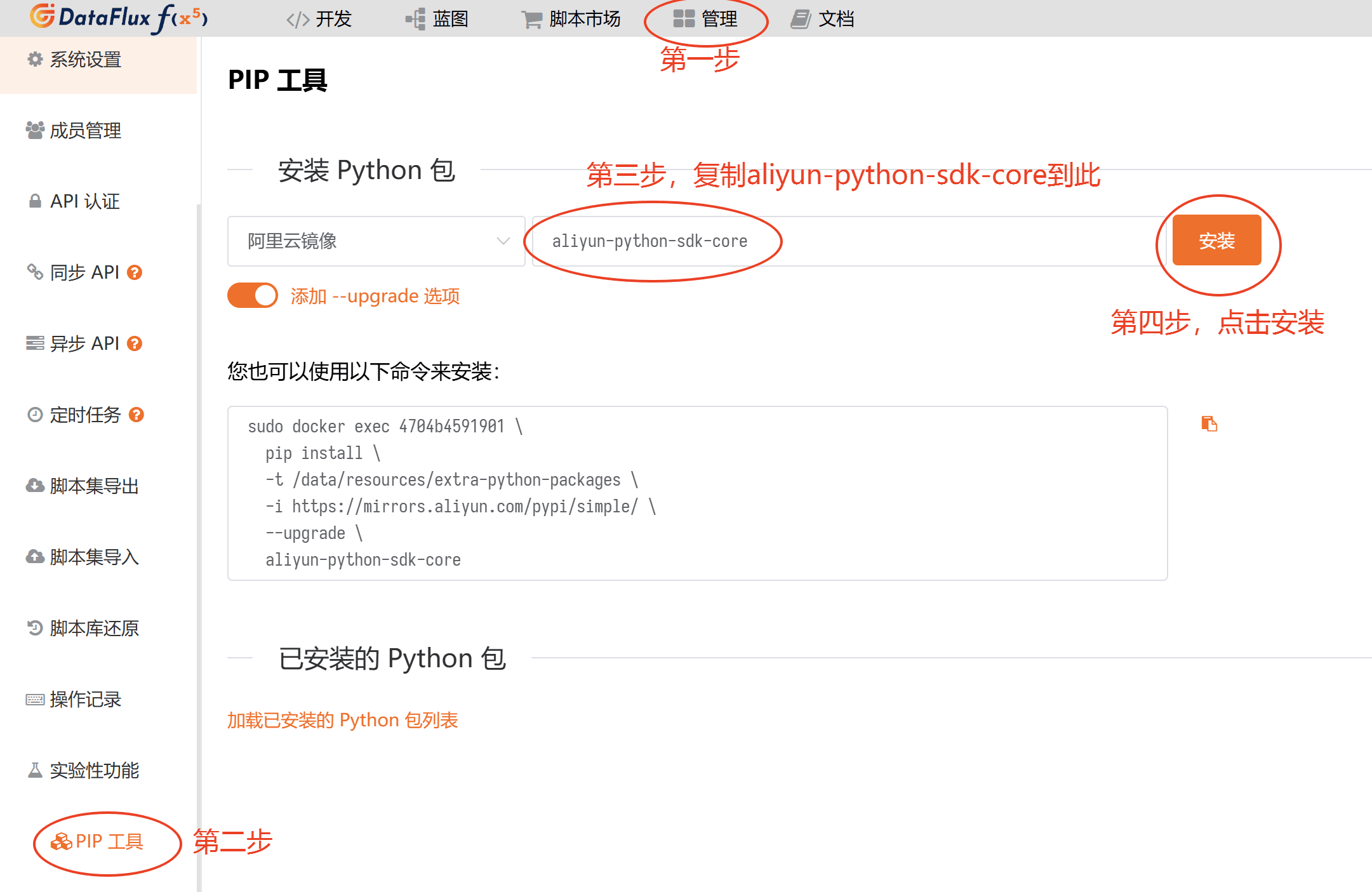
等待数秒即可安装完成。

3.2 添加阿里云资源采集脚本
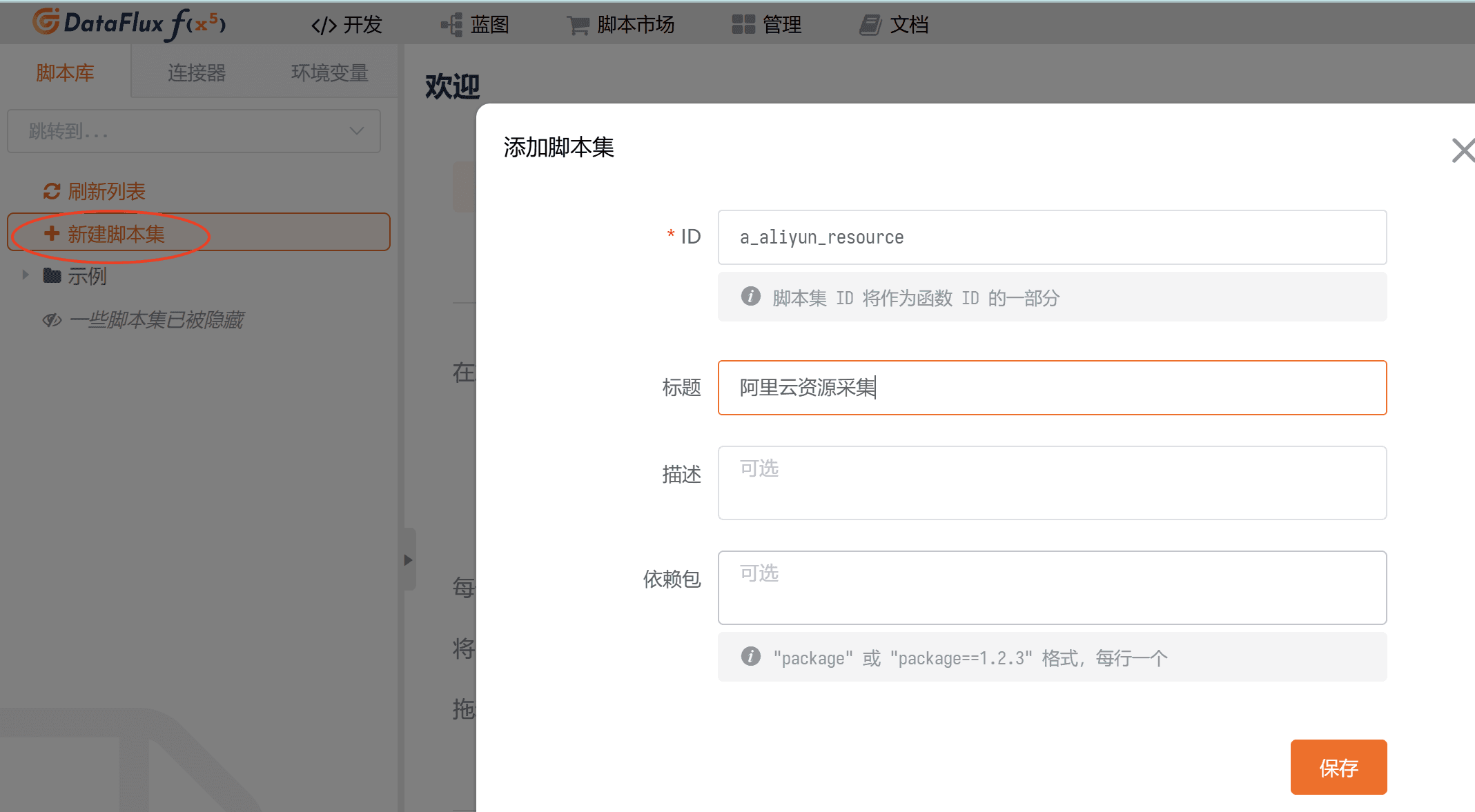
在 func 的「开发」-「新建脚本集」,添加一个方便辨识的脚本集并保存,可参考下图:
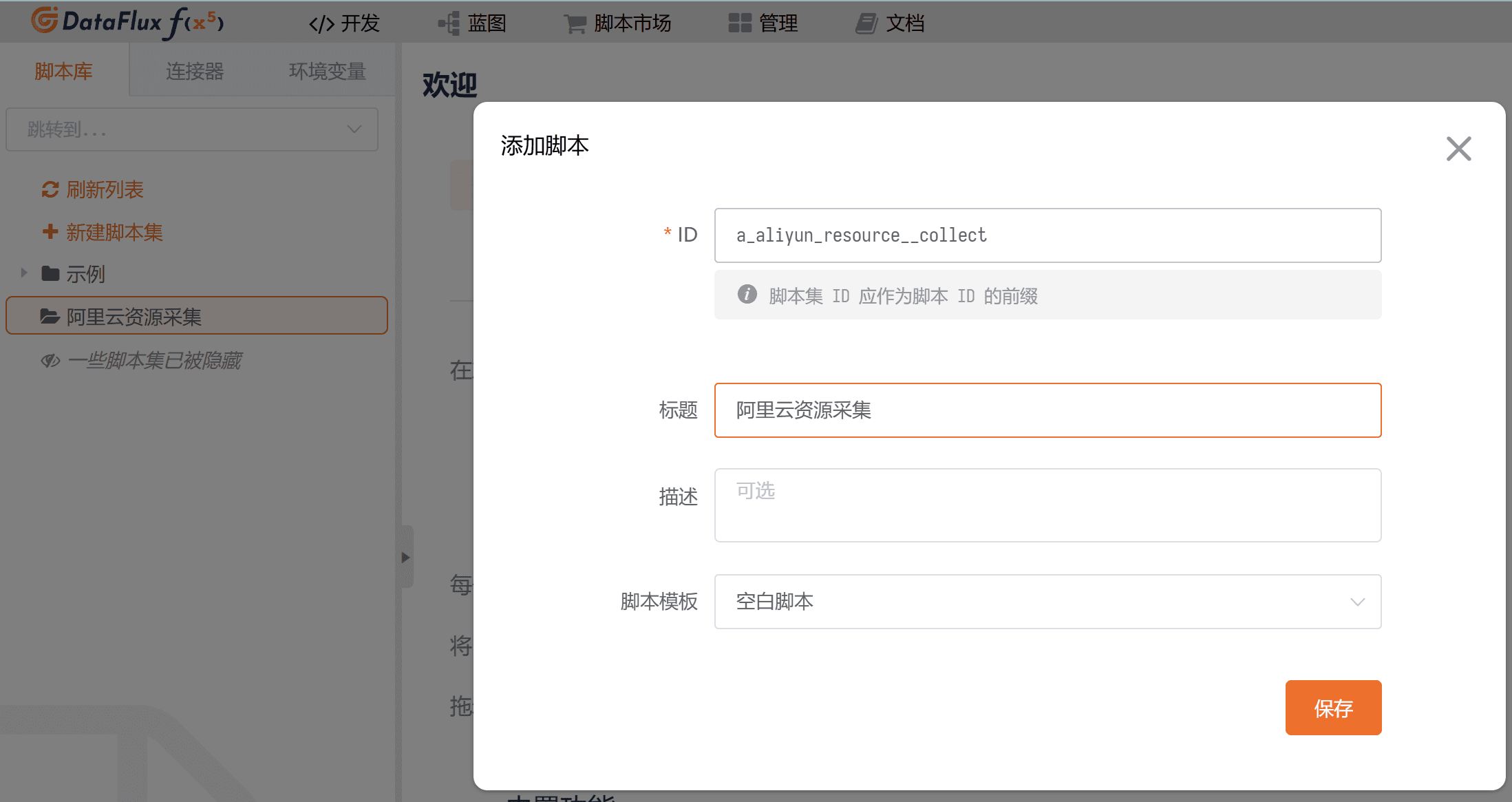
鼠标 hover 到该脚本集上,可新建一个空白脚本,如下图所示。
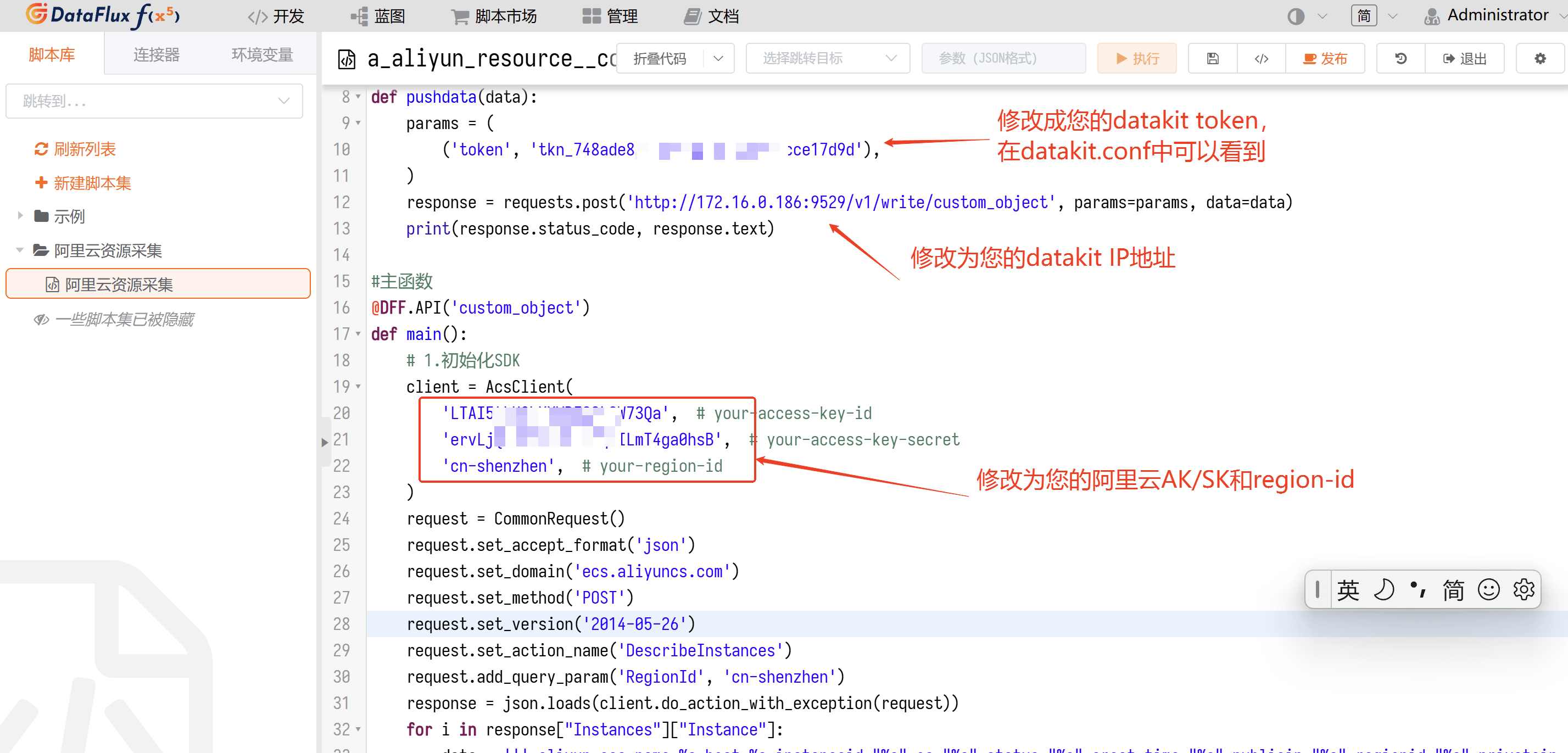
在脚本编辑处,将脚本模板粘贴进来并根据实际情况进行调整。
from aliyunsdkcore.request import CommonRequest
from aliyunsdkcore.client import AcsClient
import requests
import json
import time
#推送数据到DF
def pushdata(data):
params = (
('token', 'tokn_bW47smmgQpoZxxxxxxx'),
)
response = requests.post('http://服务器IP地址:9529/v1/write/custom_object', params=params, data=data)
print(response.status_code, response.text)
#主函数
@DFF.API('custom_object')
def main():
# 1.初始化SDK
client = AcsClient(
'LTAI5t6d3sRh3xxxxxxxx', # 修改为您的AK
'CHdrce2XtMyDAnYJxxxxxxxxxxxxxx', # 修改为您的SK
'cn-qingdao', # 修改为您的区域ID,
)
request = CommonRequest()
request.set_accept_format('json')
request.set_domain('ecs.aliyuncs.com')
request.set_method('POST')
request.set_version('2014-05-26')
request.set_action_name('DescribeInstances')
request.add_query_param('RegionId', 'cn-qingdao')
response = json.loads(client.do_action_with_exception(request))
for i in response["Instances"]["Instance"]:
data = ''' aliyun_ecs,name=%s,host=%s instanceid="%s",os="%s",status="%s",creat_time="%s",publicip="%s",regionid="%s",privateip="%s",cpu=%s,memory=%s %s''' %(
i['HostName'],
i['InstanceId'],
i['InstanceId'],
i['OSType'],
i['Status'],
i['CreationTime'],
i['PublicIpAddress']['IpAddress'],
i['RegionId'],
i['NetworkInterfaces']['NetworkInterface'][0]['PrivateIpSets']['PrivateIpSet'][0]['PrivateIpAddress'],
i['Cpu'],
i['Memory'],
int(time.time()))
print(data)
pushdata(data)
其中部分参数需要根据您的实际情况进行调整。
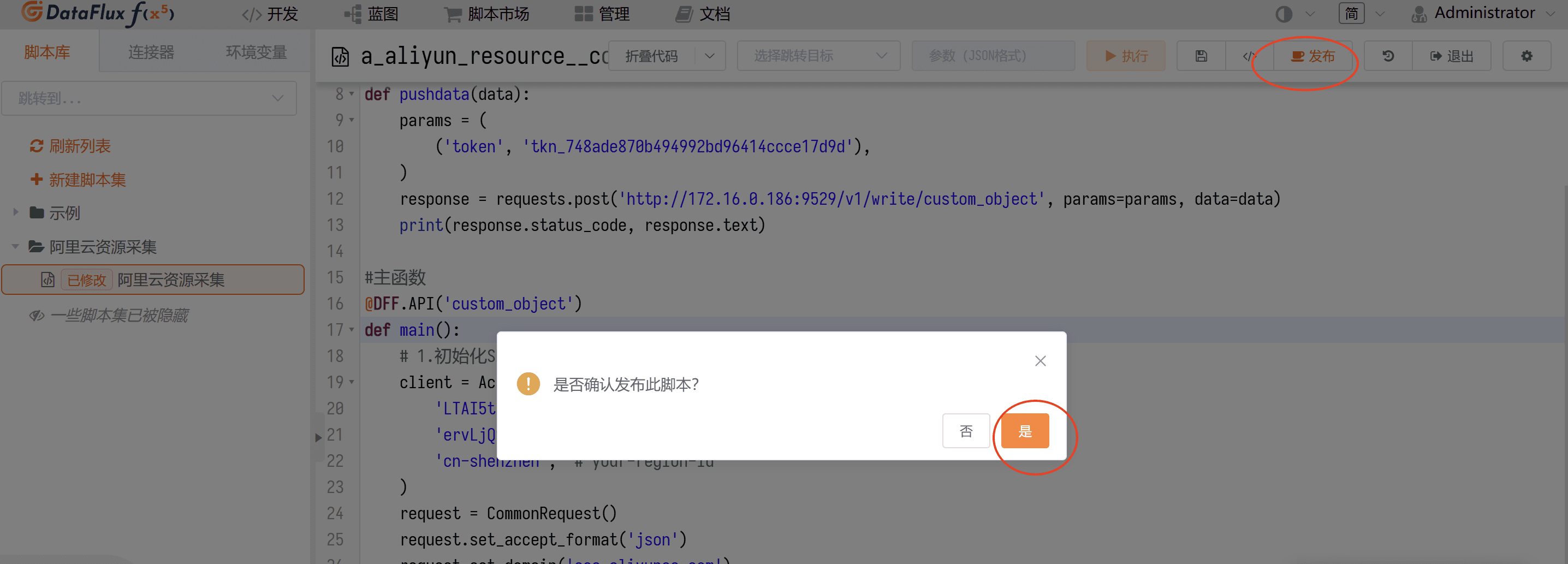
然后保存脚本,并发布(页面右上方)。
3.3 将脚本添加为定时任务
在 Func 的「管理」-「定时任务」下新建一个定时任务。
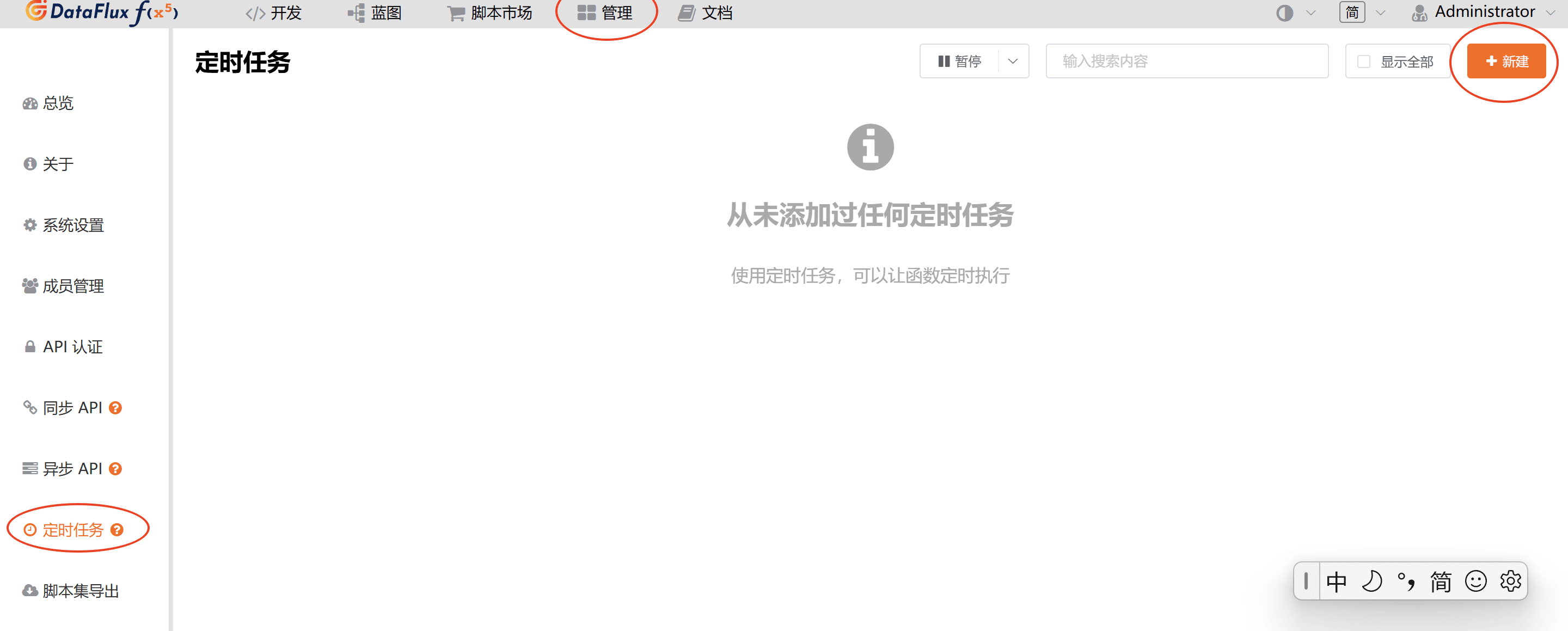
选择资源采集脚本,并根据实际情况配置定时任务的采集频率(为方便演示,本文档配置为每分钟采集)。在生产环境中由于自定义资源通常不会频繁发生变化,推荐将定时任务设置为每天 1 次。
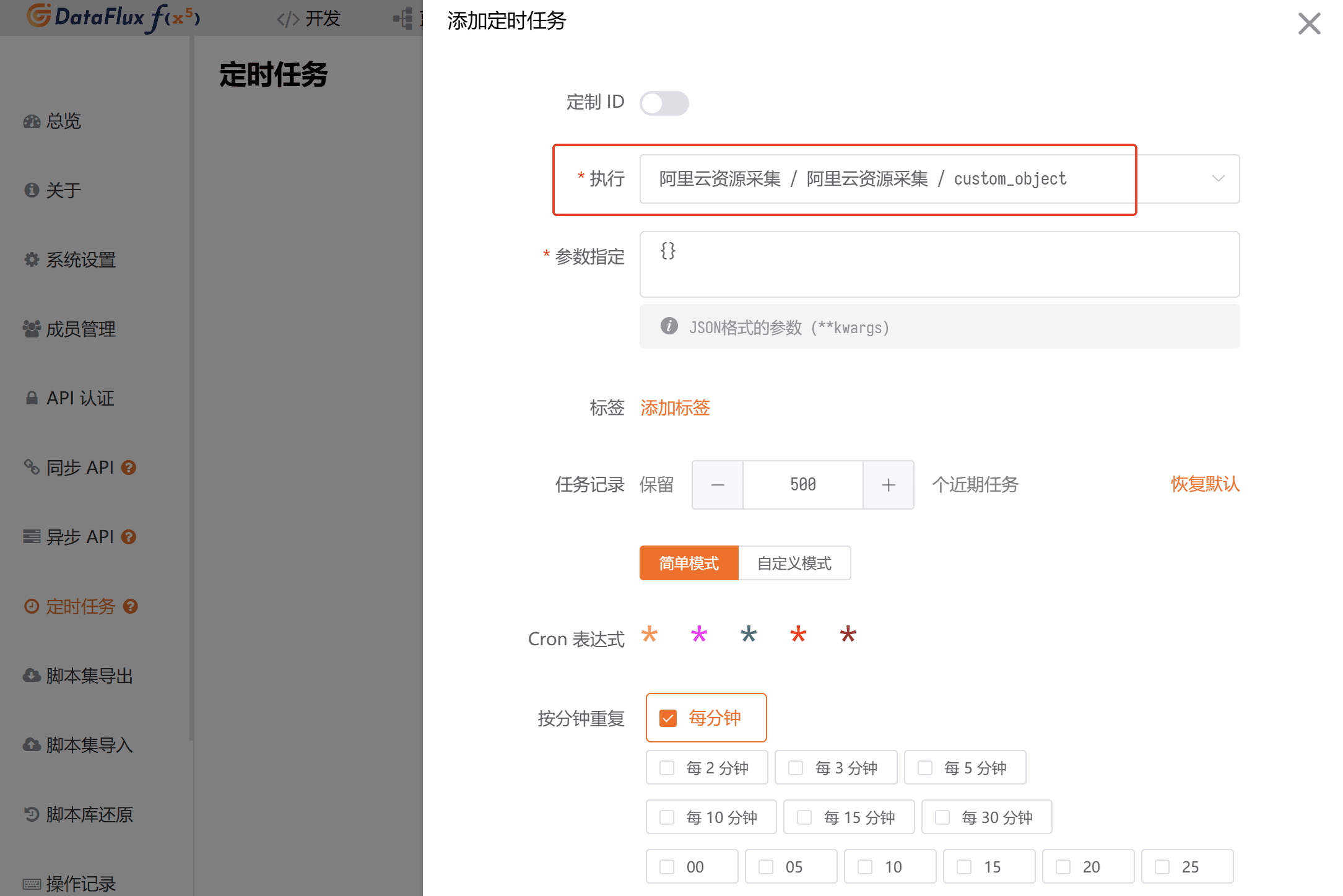
可通过「执行记录」查看该定时任务的近期执行情况。
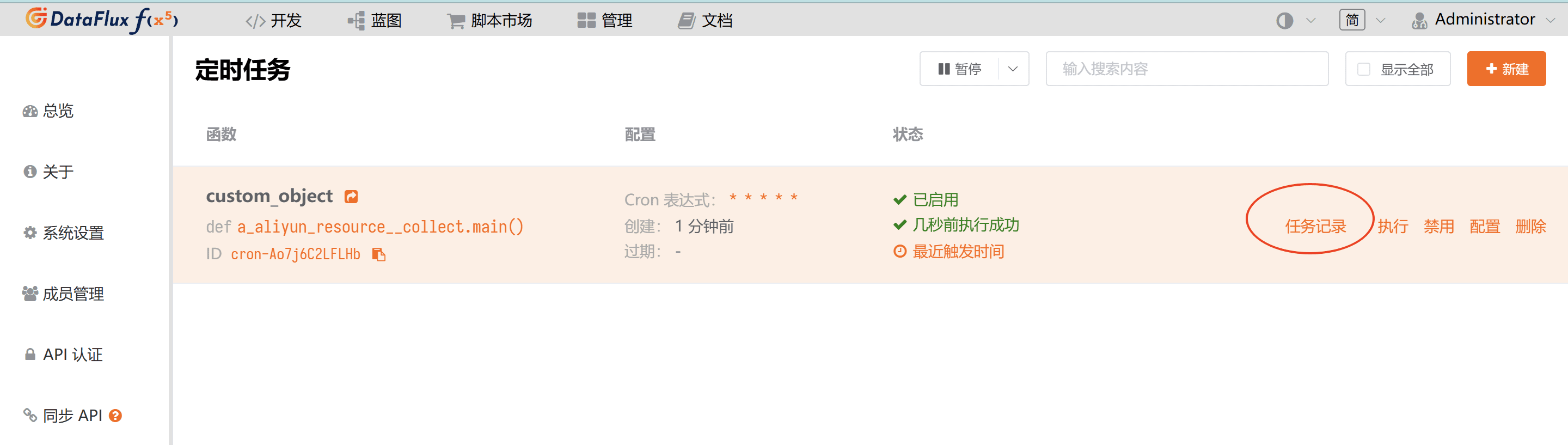
点击「显示详情」可查看定时任务的日志,便于对采集异常的情况进行排错。
详情如下图所示:

3.4 在观测云上查看「资源目录]」
接下来我们可以在观测云「资源目录」中看到这些自定义资源。
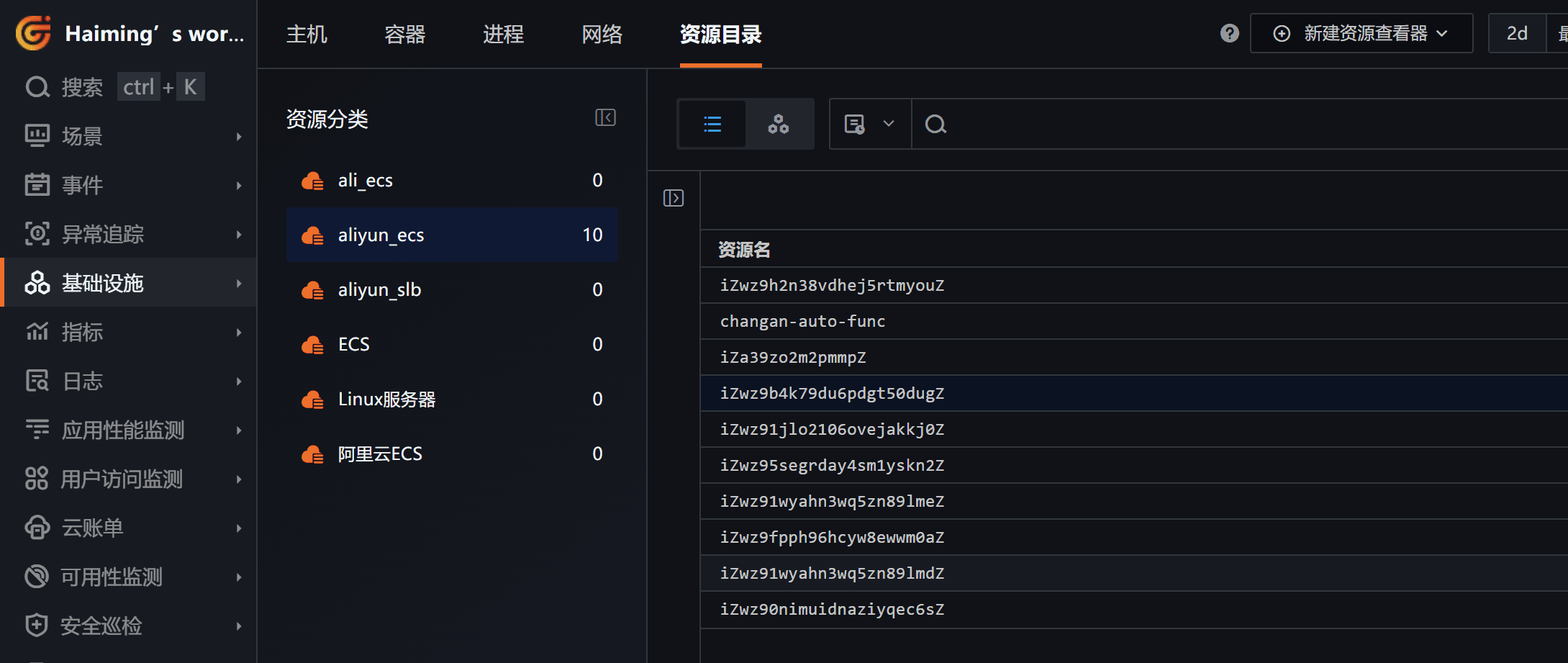
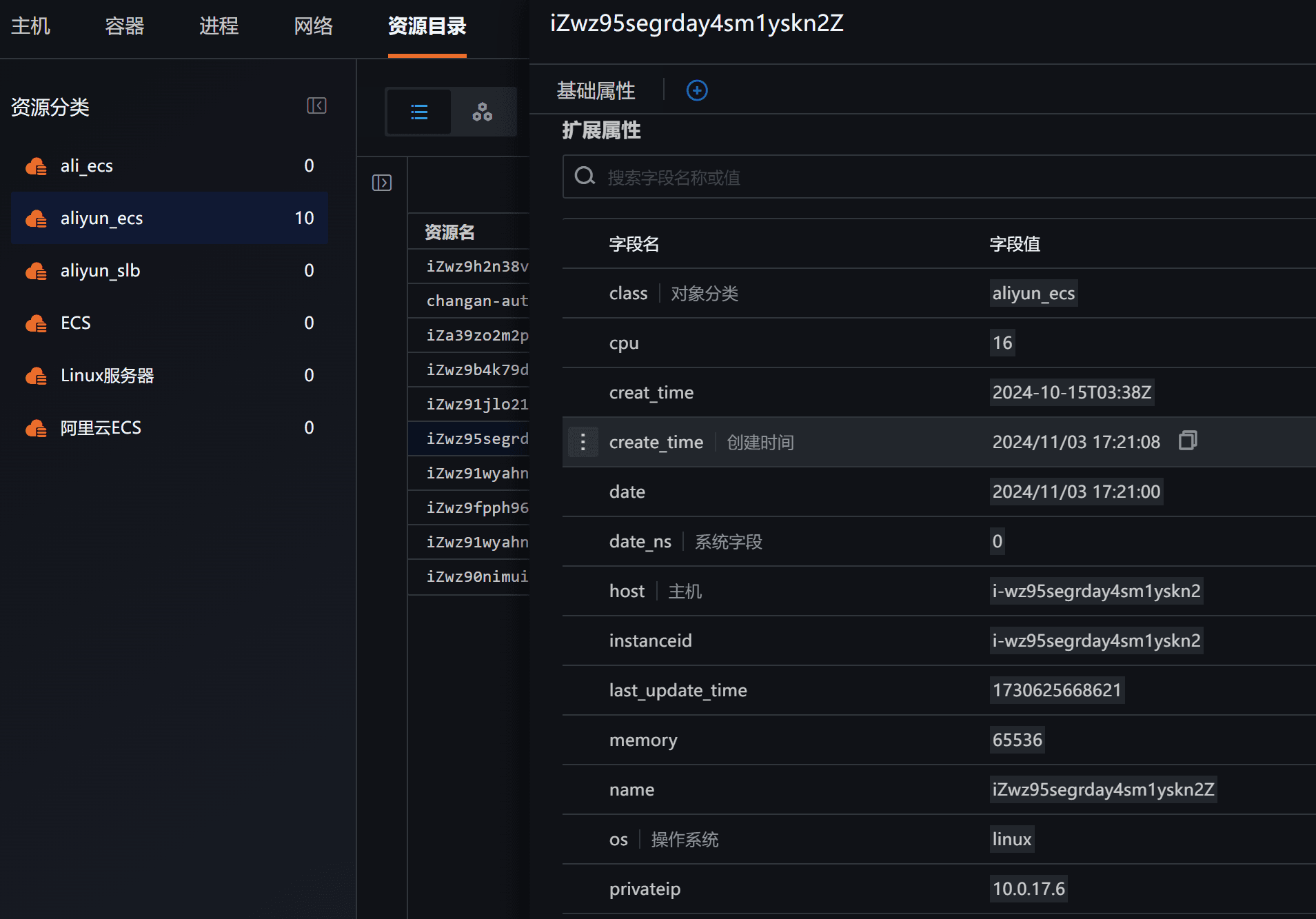
单击某个资源可查看详情,若认为信息不全可通过调整第 3.2 步中的代码来增加采集信息。
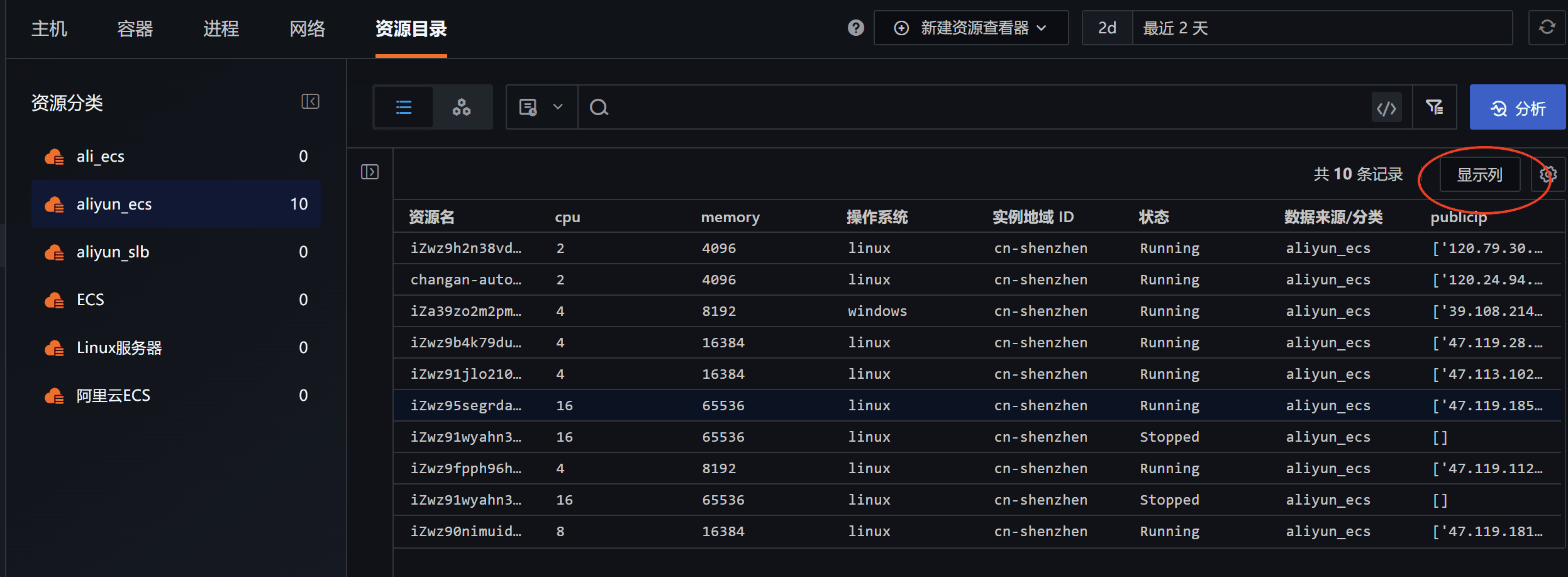
同时我们可以在「资源目录」下使用「显示列」功能来拓展资源的显示内容,更加方便管理。
结语
本文详细介绍了从阿里云同步云资源实例的对象数据到观测云的全过程,后续在采集到实例的指标数据之后,读者还可为这些资源绑定对应的仪表板,实现自定义对象数据与指标数据的关联,从而带来统一监控的最佳效果,减少多云、混合云等异构资源的管理负担。


