










演讲实录 | 深信服SRE手记,我们基于观测云的可观测落地实践

如果用一个词来形容 SRE 的工作,很多人会说是救火。但在我看来,SRE 更像是系统的守护者。
作为深信服的 IT-SRE,我所面对的,是一张支撑着数千名员工、遍布全球业务的庞大 IT 全景图。在这里,每一行日志的跳动,都可能关乎着财务的一笔回款,或者海外客户的一次关键交付。
今天,我想聊聊过去的一年里,我们是如何打破监控的传统边界,用观测云的全链路可观测性(Observability)为深信服构建数字化底座的。
1. 挑战:成长的烦恼
深信服的 IT 架构,是典型的高可用混合架构。
随着公司业务的飞速发展,我们的 IT 环境也在不断演进:核心的 ERP、CRM、供应链系统承载着巨大的业务流转压力;底层既有成熟的超融合、托管云,也有最前沿的 K8s 容器化微服务集群,甚至还保留着部分运行多年的 IIS 多站点系统 。
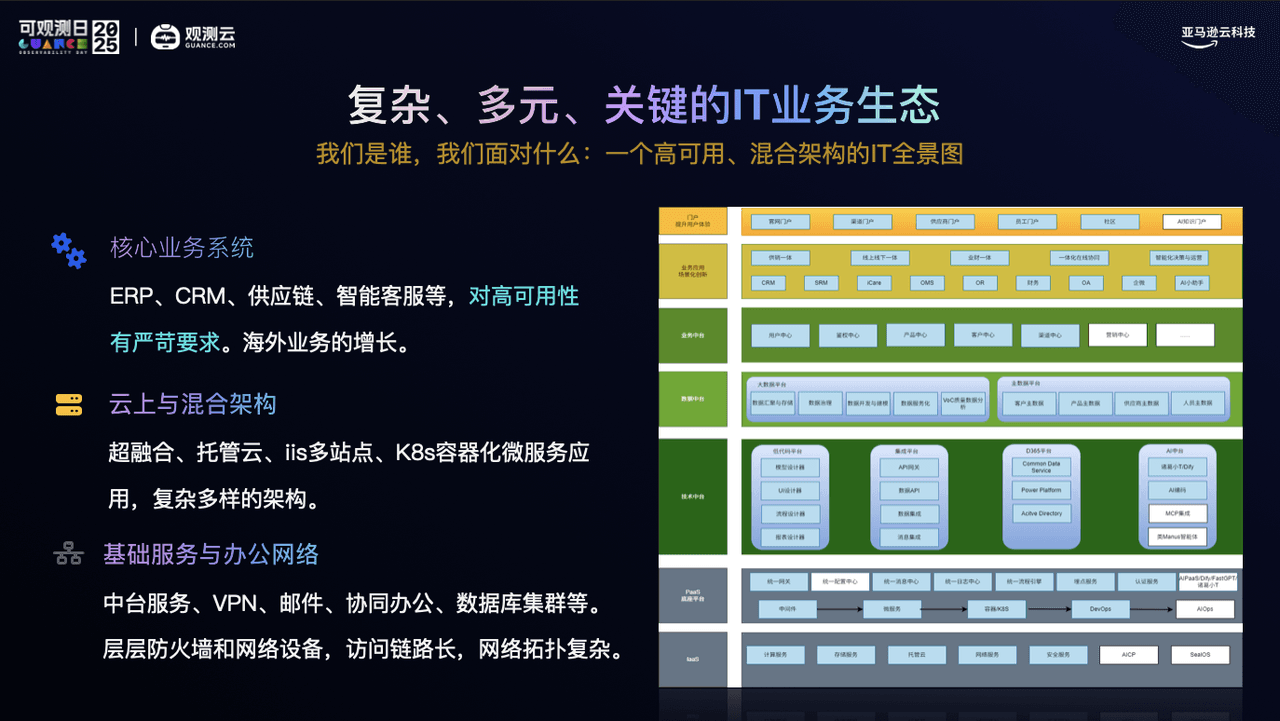
这种“多代同堂、云地混合”的架构,是许多大型企业数字化转型的必经之路,但也给我们带来了不小的挑战:
当业务部门反馈系统响应变慢时,我们需要在指标(Metrics)、日志(Logs)和链路(Traces)等多个独立的监控工具间来回切换 。这种碎片化的视角,一度让我们在排查跨服务、跨层级的复杂问题时,难以在第一时间锁定根因。

我们意识到,要保障业务的高连续性,必须要揉碎了,整合,再重构。
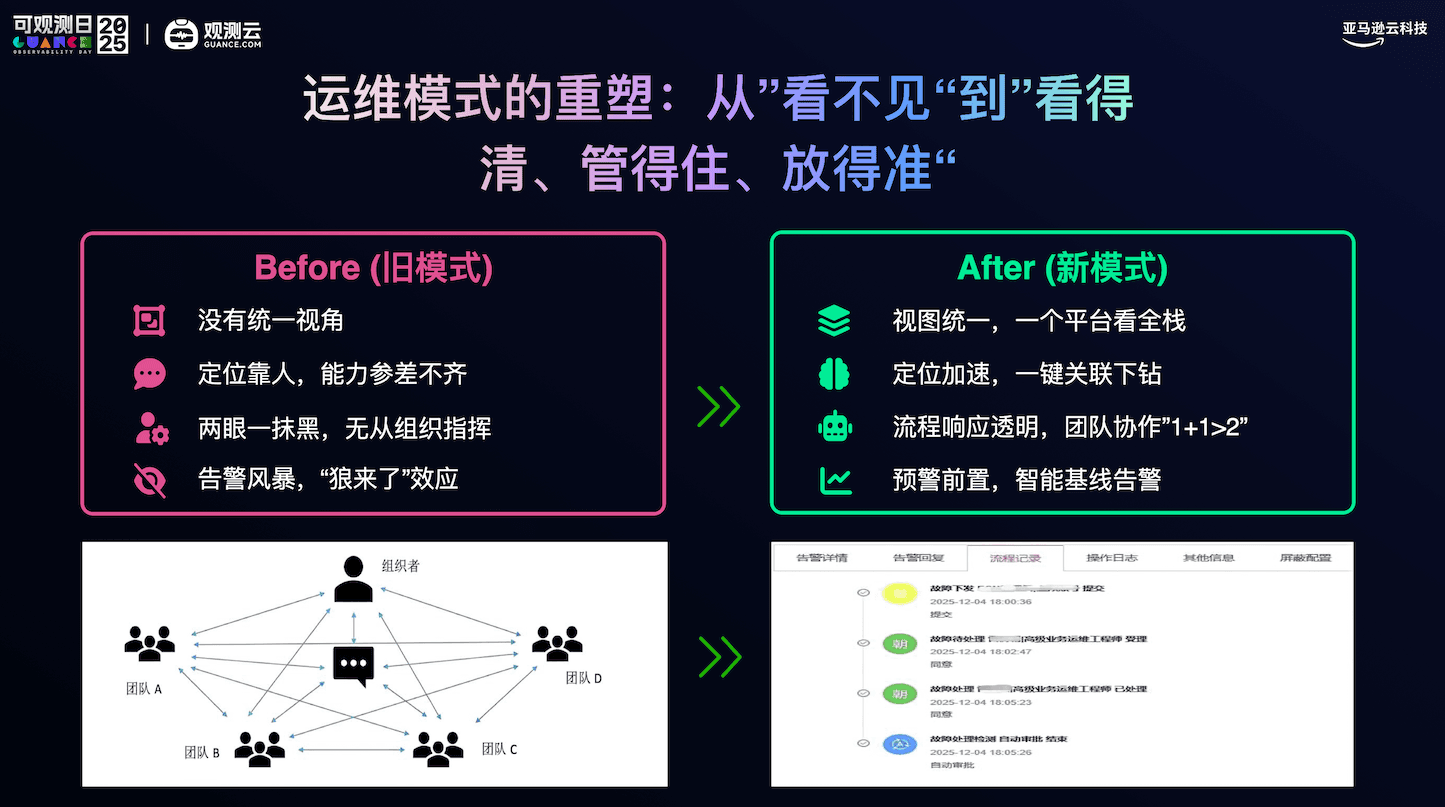
2. 破局:构建全链路上帝视角
为了彻底解决“数据孤岛”问题,我们携手观测云,开启了一场关于 IT 治理的重构。
我们的目标很明确:统一视角,全栈可控。
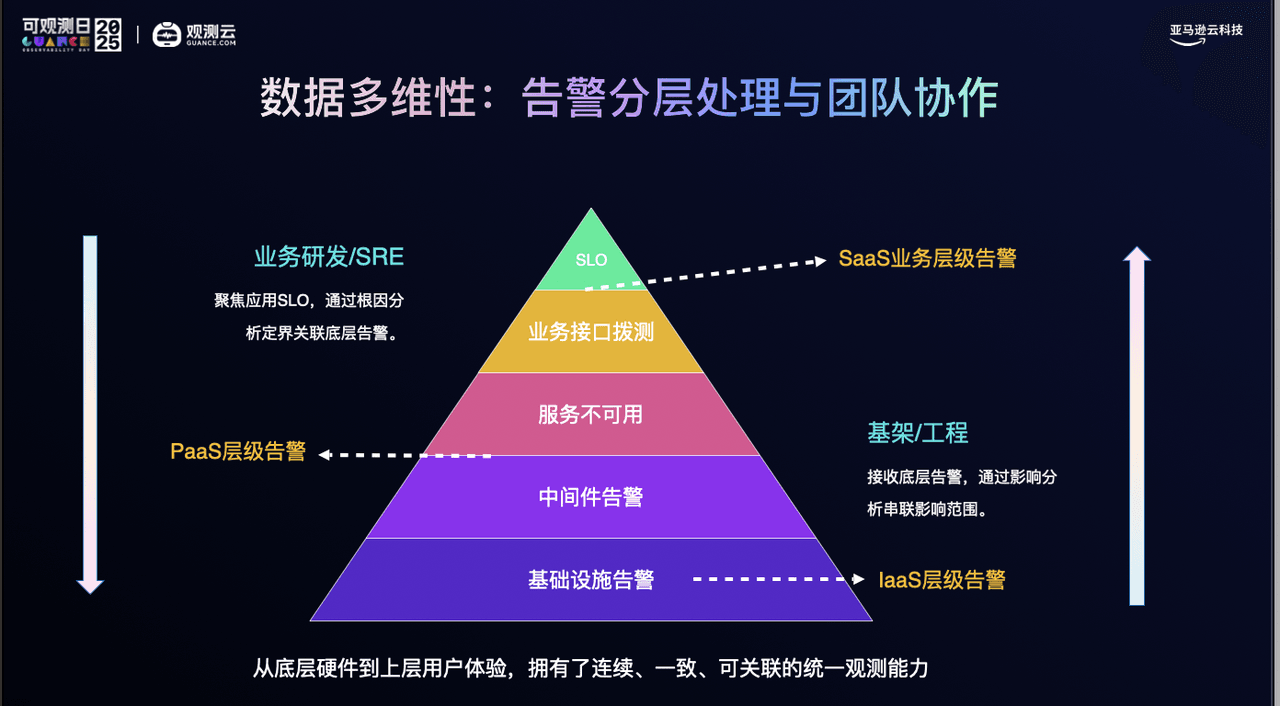
通过将 IaaS 基础设施、PaaS 中间件、以及上层 SaaS 应用的数据进行多维融合,我们建立了一套标准化的数据标签与等级划分体系。

在这个过程中,我们做了一个重要的管理创新。
过去,告警策略往往是一刀切。为了不错过任何风险,我们曾不得不忍受大量的冗余告警。而这一次,我们引入了精细化的分层治理机制:
- 业务分级:我们将应用划分为 S/A/B/C 四个等级,确保核心资源聚焦于 S/A 级关键业务。
- 策略解耦:我们将“监控项”与“应用层级”解耦。S级应用中的边缘日志不再触发高优告警,而 A 级应用中的致命错误则会立即升级。
这套组合拳打下来,效果立竿见影:我们的告警噪音下降了 70%。
这意味着,SRE 团队不再被无效信息淹没,每一次手机震动,都是真正需要立即处理的 Critical(紧急) 事件。
3. 价值:当 IT 听懂业务的语言
技术最终一定要服务于业务。在深信服,SRE 的价值不仅仅是保证服务器不宕机,更是要护航业务冲刺。
每逢季度末,财务与销售体系进入冲刺模式,ERP 和订单系统面临着高并发的考验。以前,我们更多关注 CPU、内存水位;而现在,我们更关注业务流的健康度。
我们构建了钱财物监控大屏,利用观测云的数据处理能力,将 IT 指标翻译成了业务语言:
- 报价 -> 合同 -> 下单 -> 发货 -> 回款,全链路实时可视化。
- 一旦“合同流转”环节出现微小的阻塞,或者“财务报表生成”出现延迟,系统会立即预警。
这让 IT 运维从幕后走向了台前,真正成为了业务冲刺中可靠的数字化基座。

4. 进化:迈向 AIOps 时代
在观测云的陪伴下,回望这一年,数据的变化印证了我们转型的成功:
- 平均故障定位时间(MTTI)下降 50%。
- 平均故障恢复时长(MTTR)下降 65%。
- 跨服务性能排查从小时级缩短至分钟级。

但这只是深信服 IT 演进的一个逗号。
在我们的规划中,未来的可观测性将更加智能。我们正在探索 AIOps(智能运维) 的落地,从目前的“智能巡检”向“自动化故障排查”演进。

我们希望通过引入 AI SRE Agent,让它像一位数字同事一样,协助工程师进行异常预测与根因分析。这样,我们的 SRE 工程师就能从重复劳动中解放出来,去专注于架构优化与技术创新。
深信服的 IT 运维变革之路不会就此停止。我们始终相信,只有不断打磨技术的深度,才能承载起业务的厚度。


