










演讲实录|一线真实交付经验, 在大客户复杂系统中落地可观测性

如果用一个词来形容大型系统里的可观测性建设,很多人会说是工具选型。
但在我看来,它更像是一场长期的系统工程。
作为观测云华南区域的交付伙伴,我这些年接触的,往往不是从 0 到 1的系统,而是已经跑了很多年、业务不断增长、架构不断叠加的大型生产环境。
在深圳可观测日上,我分享的并不是某一个成功案例,而是这些系统在规模化之后,反复出现的共性问题,以及观测云在交付中扮演的角色。
01 大型客户的可观测困境,从来不止工具多
在真实的客户环境中,我很少见到没有监控的情况。大多数大型客户,早就搭建好了自己的监控体系:如Prometheus + Grafana 看指标,Pinpoint 看调用链,ELK 或托管 ES 查日志。
每一套工具单独看,都没有问题。但真正的问题出现在系统复杂到一定程度之后。

当一次故障涉及多个 AZ、多个服务、多个团队时,工程师需要在不同系统之间频繁切换,靠经验去拼接一条完整的因果链路。Trace、Metrics、Logs 是割裂的,跨区域调用是追不全的。
更现实的是,在生产故障发生时,团队往往会高频查询 7 天、30 天甚至更长时间范围的历史数据。
日志、指标、链路彼此影响,查询压力叠加,监控系统本身反而成了瓶颈。
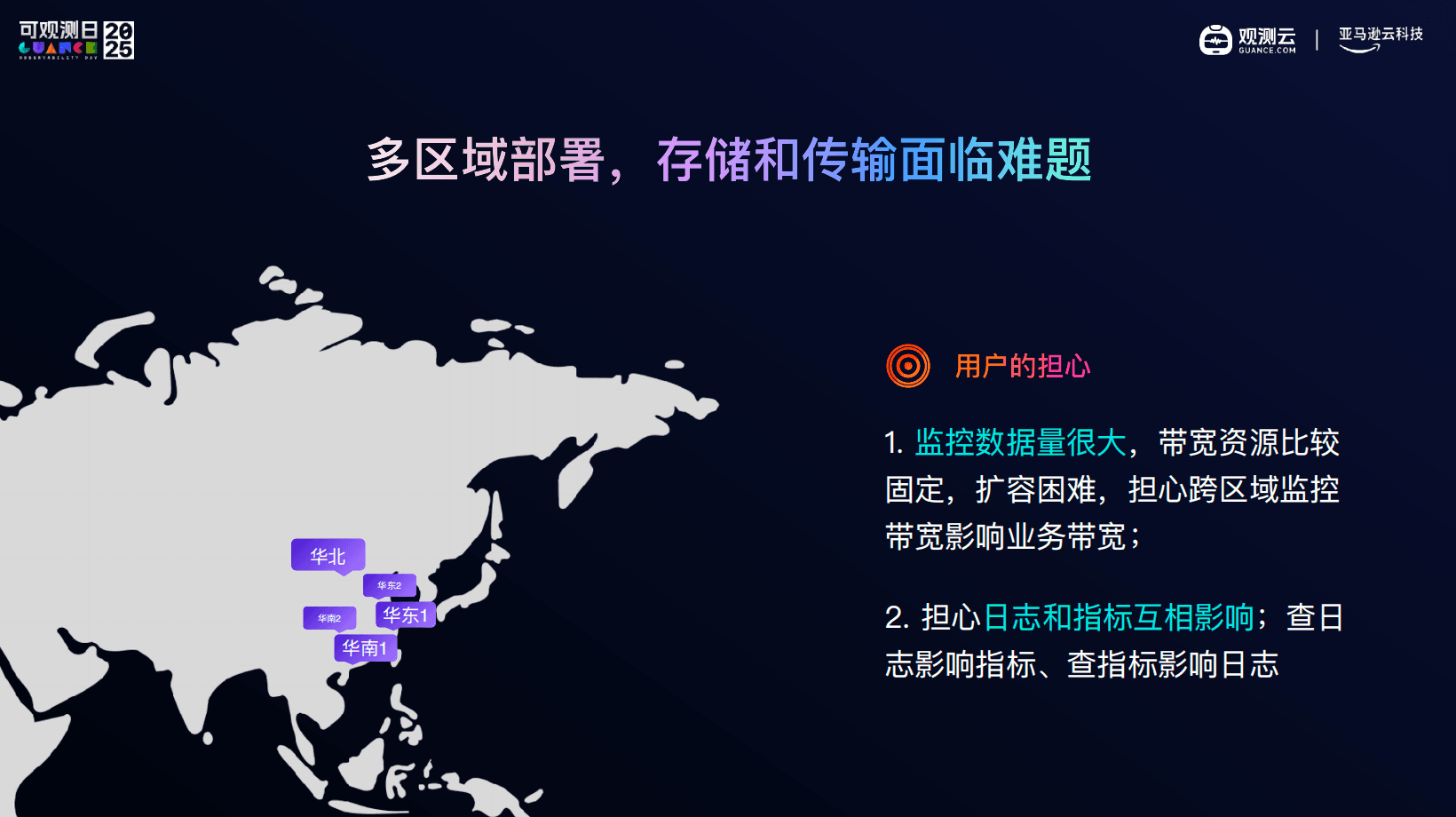
很多客户都会明确提出一个要求:观测系统,必须比业务系统更稳。
02 破局:不是再加工具,而是重构观测方式
在交付中,我们并没有继续往原有体系里补工具,而是选择与观测云一起,重新审视观测体系的设计方式。
我们的目标很清晰:统一视角,全栈关联。
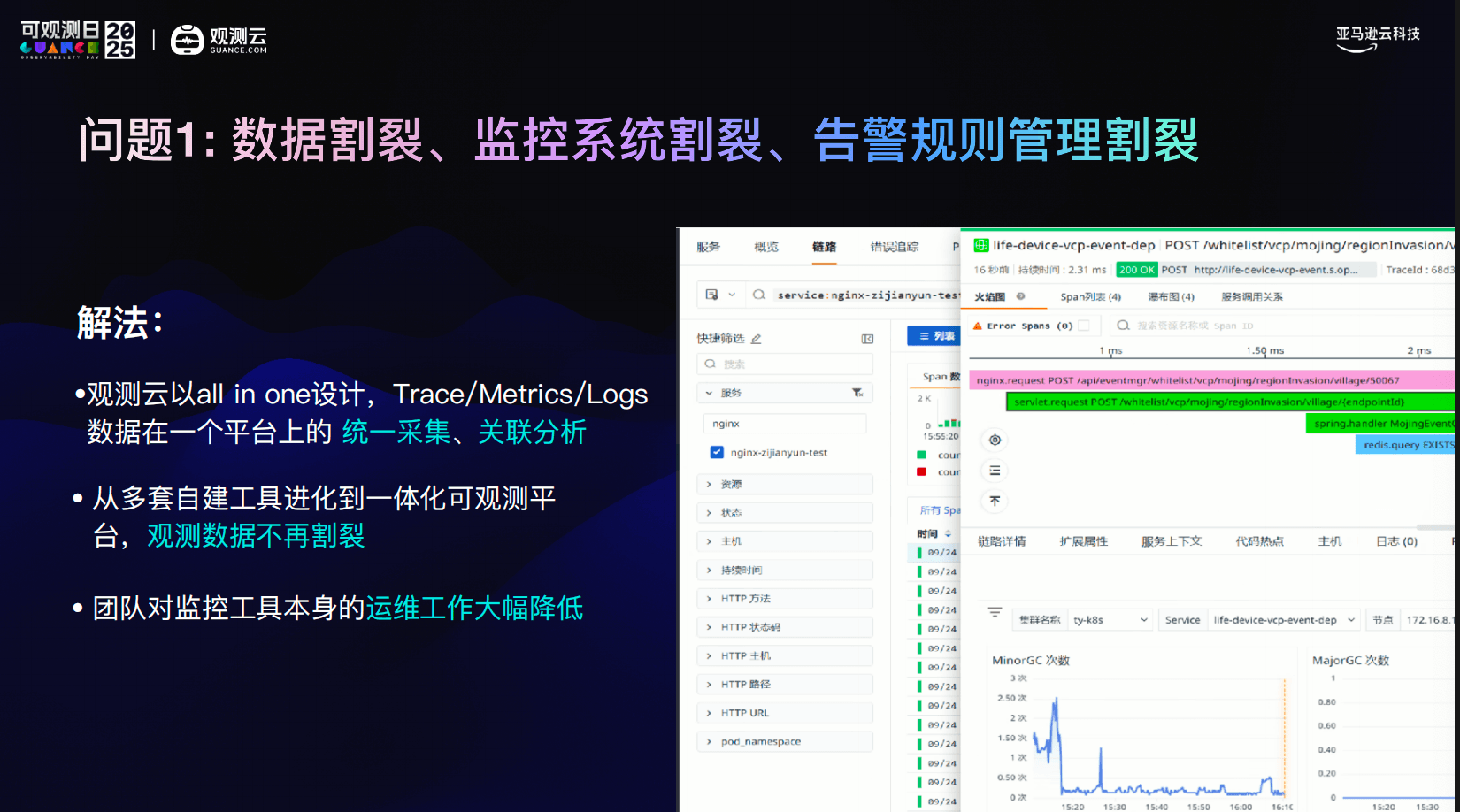
观测云采用的是 All in One 的一体化设计,把 Trace、Metrics、Logs 放在同一个平台中统一采集、统一建模。
- 一次请求,可以从链路直接下钻到日志;
- 日志可以反向关联到主机、容器和指标;
- 数据之间的关联,不再依赖工程师在多个监控系统中频繁切换,凭经验去脑补业务链路、服务依赖,以及指标、日志、链路数据之间的因果关系。
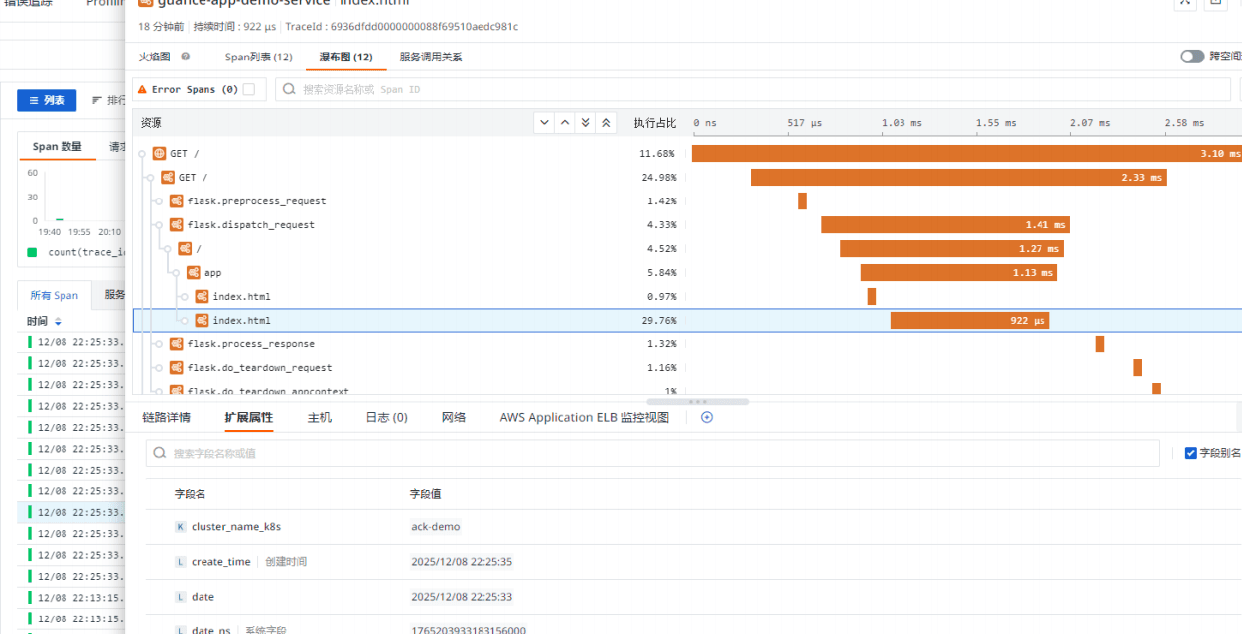
运维的视角,从我现在该去哪查,变成了这个问题本身在系统里的完整轨迹是什么。
03 多区域架构下,观测首先要跑得稳
在多区域、多 AZ 的架构下,客户最关心的往往是性能和稳定性:
- 跨区域采集,会不会影响业务带宽?
- 日志和指标,会不会互相拖慢?
- 数据量上来之后,还能不能查?
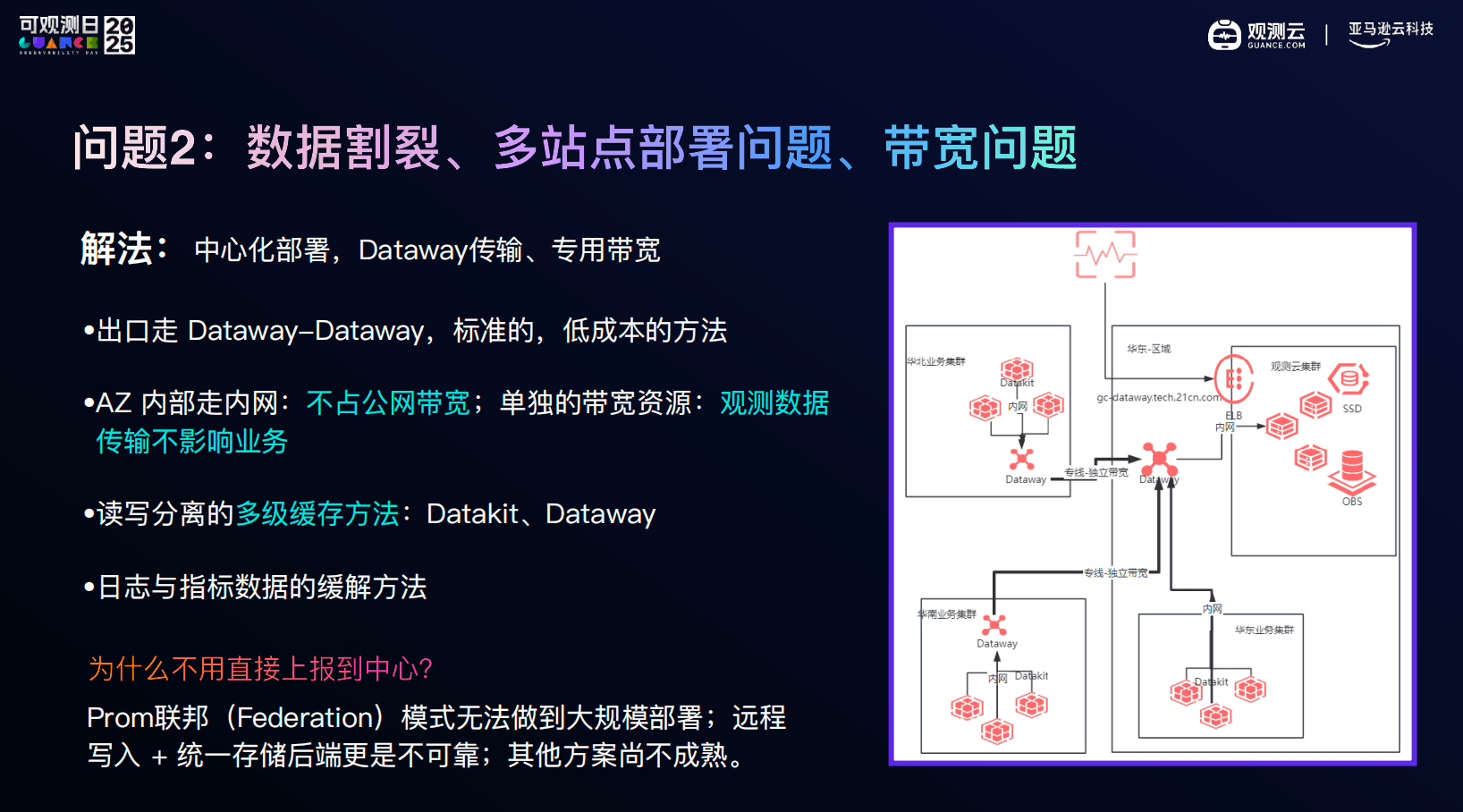
在观测云的交付实践中,我们采用的是中心化部署思路:
- AZ 内部走内网采集,避免占用业务公网带宽
- 通过 Dataway–Dataway 进行观测数据传输,实现与业务流量隔离
- Datakit 与 Dataway 采用读写分离和多级缓存机制
- 日志、指标、链路在底层进行解耦,互不干扰
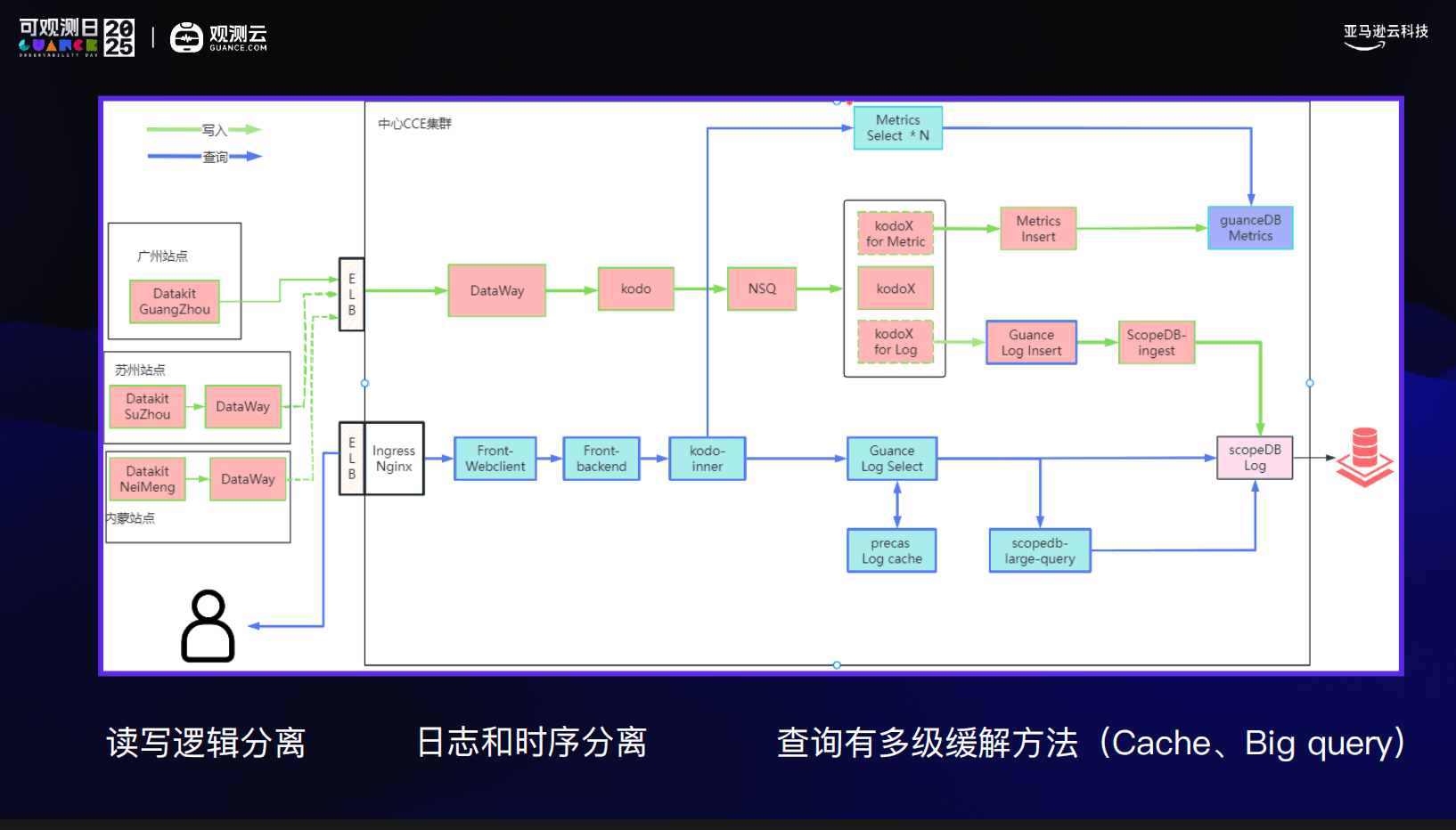
这套设计的核心目标只有一个:在大规模、高并发查询场景下,观测系统依然可用。
04 观测的价值,不应只停留在技术层
在很多大型客户中,我们还会反复遇到另一个问题:数据很多,但没人知道这些数据属于谁。
于是,在交付中我们会做一件看似不那么技术的事情:把 CMDB、业务模块、负责人、重要级别等业务属性,通过观测云的能力,打进指标、日志和链路中。
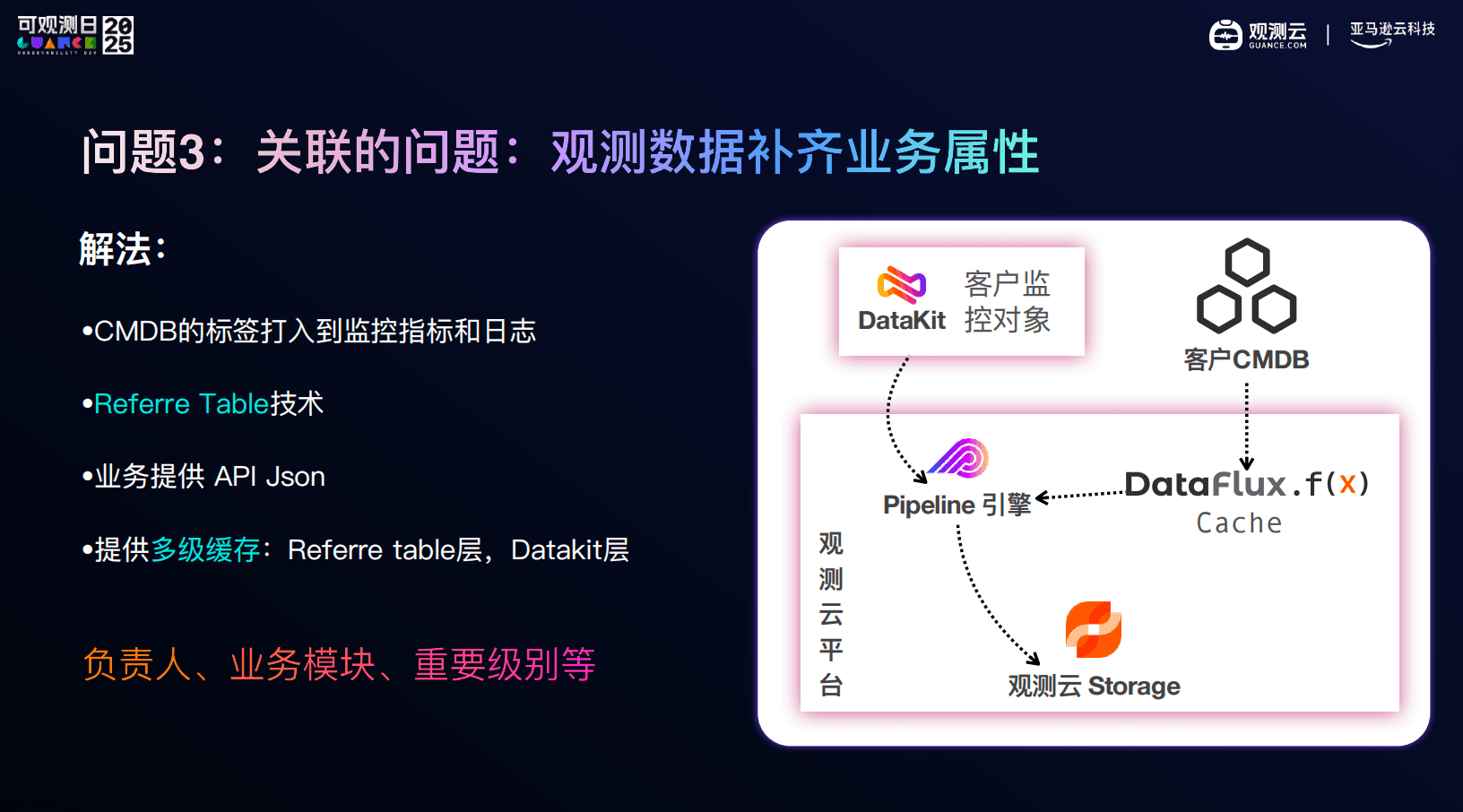
最终的效果并不是系统更复杂,而是当告警发生时,工程师能立刻知道:这是哪个业务、影响范围多大、该找谁。
观测数据,第一次真正参与到了业务决策中。
05 向前一步:当 SRE 遇上大模型
最后,我也分享了一个现在受到广泛讨论的趋势:AIOps 正在从概念,走向真正的产品形态,可以用自然语言查询实时观测数据,可以结合日志、指标、链路给出诊断建议,甚至在受控范围内执行动作。观测云也在探索大模型 + 实时观测数据的结合方式。
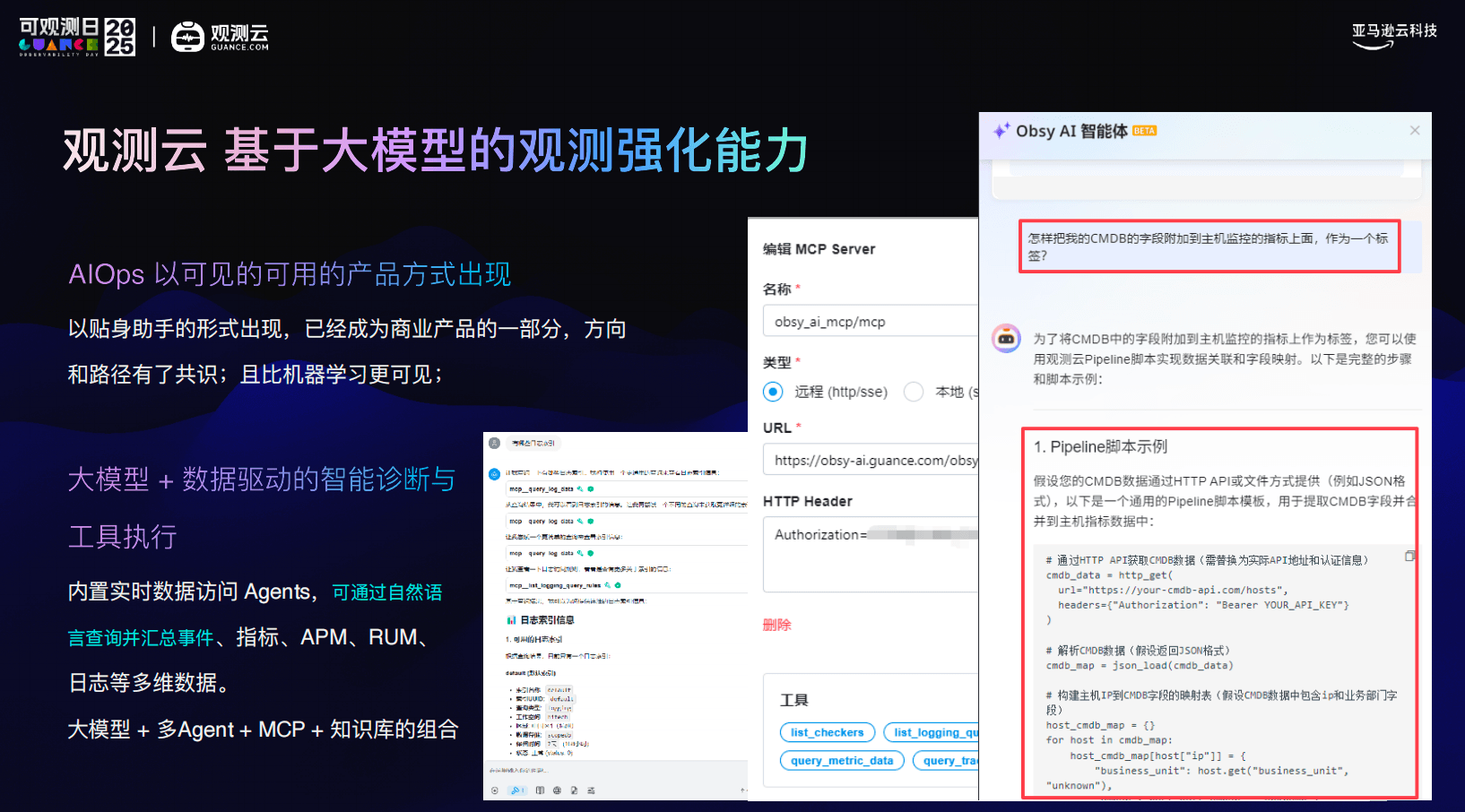
对我来说,这并不是要替代工程师,而是让工程师从大量低效、重复的排查工作中解放出来,把精力放在真正需要判断和决策的地方。
真实世界里的系统,只会越来越复杂。当复杂度跨过某个阈值,靠经验和人力堆叠,是撑不住的。
客户需要一个为复杂而生、并且能够持续演进的可观测平台。这也是我在交付中反复选择观测云的原因。


