










观测云采集云资源自定义标签最佳实践

什么是云上自定义标签
云上自定义标签是阿里云、AWS、华为云等云服务提供商提供的一项功能,它允许用户通过键值对的形式为云资源添加个性化标识。这种灵活的标签系统不仅有助于用户在复杂的云架构中高效地组织和追踪资源,还能简化资源管理,并增强自动化处理能力。用户可以根据自己的业务需求和运维策略,对云资源进行细致的分类和精确的访问控制,从而实现更高效的资源管理和优化的运维流程。
采集自定义标签的必要性是什么
当观测云利用 DataFlux Func 平台同步云资源监控数据时,它通常会采集云监控数据和对象数据,并默认提取一些关键属性作为标签(tags)。尽管这种方法能够满足基本需求,但对于一些用户而言,这些预设的标签并不足以支持他们快速定位和筛选资源。因此,他们需要在采集指标的同时,额外采集数据标签以增强资源的可识别性和筛选效率。以下内容将指导用户如何在数据上报前,为采集的数据补充额外的自定义标签。
观测云方案
在不修改官方采集器的前提下,采集器本身提供了 after_collect 参数,用户可赋值一个函数,对采集后的数据做二次处理,其中就包括添加额外的 tags。
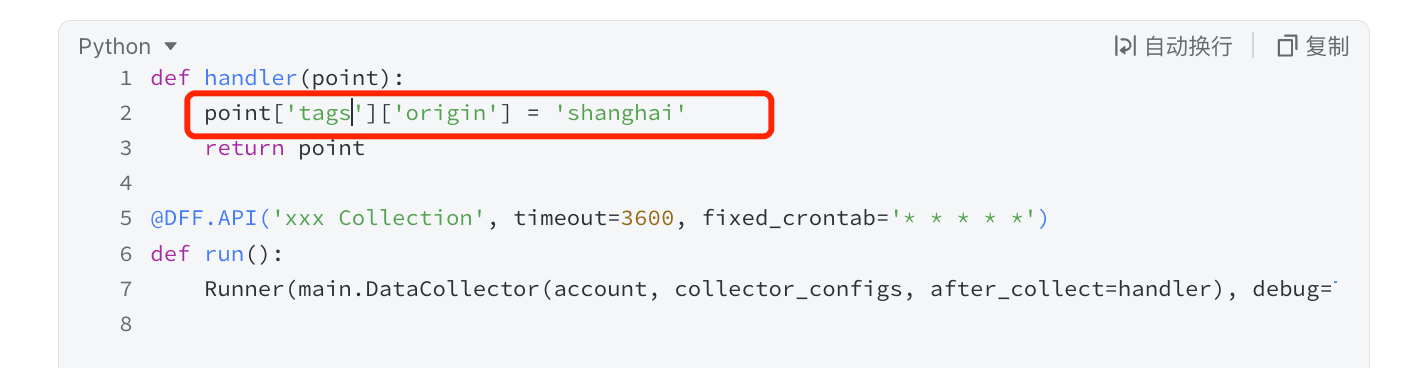
为大家介绍一个 handler 函数,示例如下:
def handler(point):
point['tags']['origin'] = 'shanghai'
return point
@DFF.API('xxx Collection', timeout=3600, fixed_crontab='* * * * *')
def run():
Runner(main.DataCollector(account, collector_configs, after_collect=handler), debug=True).run()
该函数仅支持一个参数 point 。point 是采集器即将上报的数据,所有的数据结构可参考相关采集器文档「数据上报格式」,如下图是 ECS 的示例:
在脚本市场中,每一个脚本示例都会有一个「数据上报格式」。
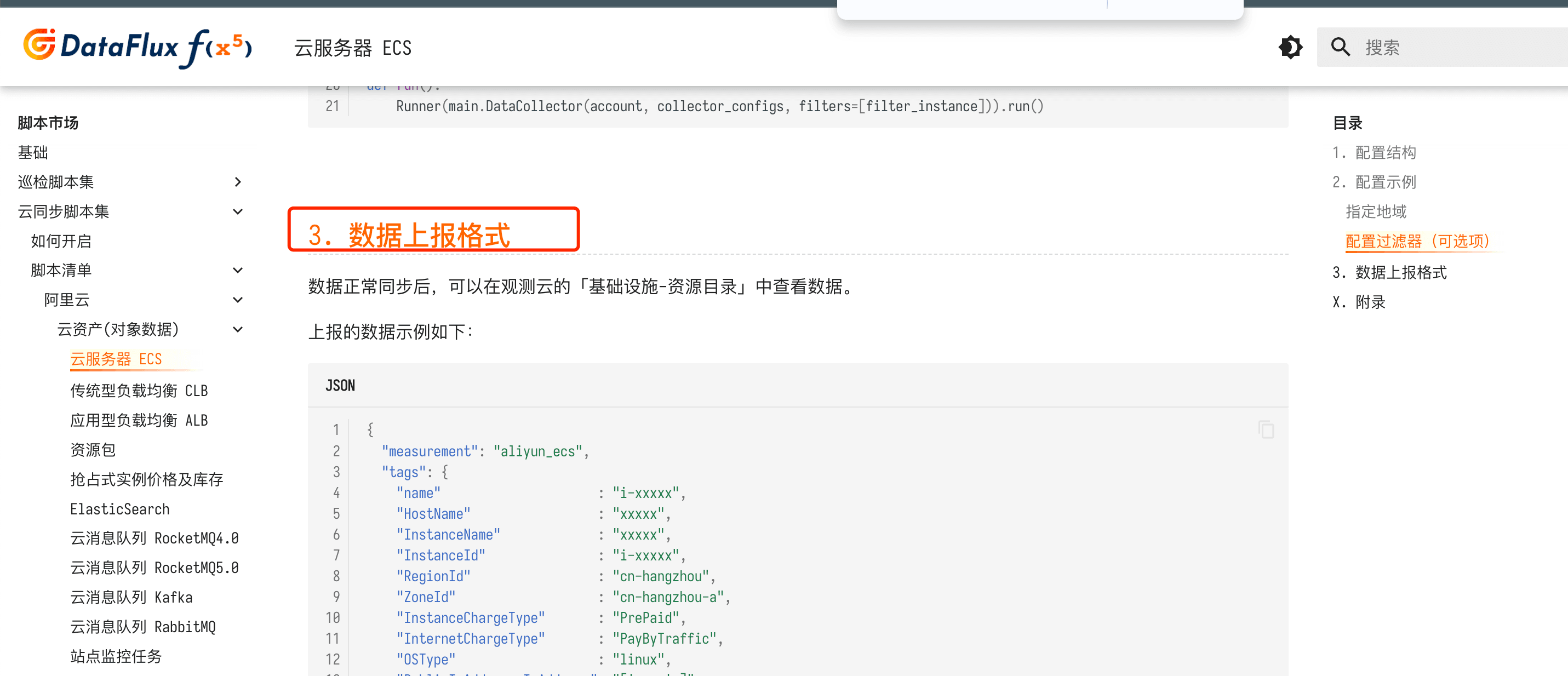
其中包含三个字段分别是 measurement、tags、fields 。
我们重点关注的就是 point.tags 字段,而外添加 Tags 的最终目的为:将待补充的健值对插入 tags 。
示例中相当于给 point.tags 添加一个 key 为 origin ,value 为 shanghai 的健值对。
对此,大家对这个概念应该清楚一些了,接下来有一个实际的例子为大家演示。
实战操作
背景介绍
客户在使用阿里云环境时,希望采集 ECS(Elastic Compute Service)数据,并为了方便在阿里云平台上的查看和管理,运维团队已经自定义了一些标签,例如 project 和 env 。然而,在首次尝试通过观测云采集数据时,发现这些自定义标签并未被成功采集。为了解决这一问题,我们需要确保在数据采集过程中,除了标准的监控指标外,还能够捕获并包含这些关键的自定义标签。以下是确保自定义标签被正确采集和上报的步骤和方法。
完整代码案例
# Fill in the following configuration as required
# For details, please refer to:https://func.guance.com/doc/script-market-guance-aliyun-ecs/
# For details, please refer to:https://func.guance.com/doc/script-market-guance-aliyun-monitor/
# AlibabaCloud AK
account = {
"ak_id" : "xxxx",
"ak_secret" : "xxxx",
"extra_tags": {
"account_name": "xxxx", # Your Account Name
}
}
# Collector configuration
collector_configs = {
'regions': ['cn-shanghai']
}
monitor_configs = {
'targets': [
{
'namespace': 'acs_ecs_dashboard',
'metrics' : [
'CPUUtilization', 'memory_usedutilization', 'load_1m',
'load_15m', 'load_5m', 'DiskReadBPS', 'DiskWriteBPS',
'DiskReadIOPS', 'DiskWriteIOPS', 'disk_readiops',
'disk_writeiops', 'diskusage_utilization', 'fs_inodeutilization',
'GroupVPC_PublicIP_InternetInRate', 'GroupVPC_PublicIP_InternetOutRate',
'IntranetInRate', 'IntranetOutRate', 'concurrentConnections',
'cpu_wait', 'cpu_user', 'cpu_system', 'memory_freeutilization', 'disk_readbytes',
'disk_writebytes', 'networkin_rate', 'networkin_packages', 'net_tcpconnection',
'memory_freespace', 'memory_usedspace', 'memory_totalspace'
],
},
],
}
# Instance filter
def filter_instance(instance):
'''
return True|False
'''
# return True
instance_id = instance['InstanceId']
if instance_id in ['xxxxx']:
return True
return False
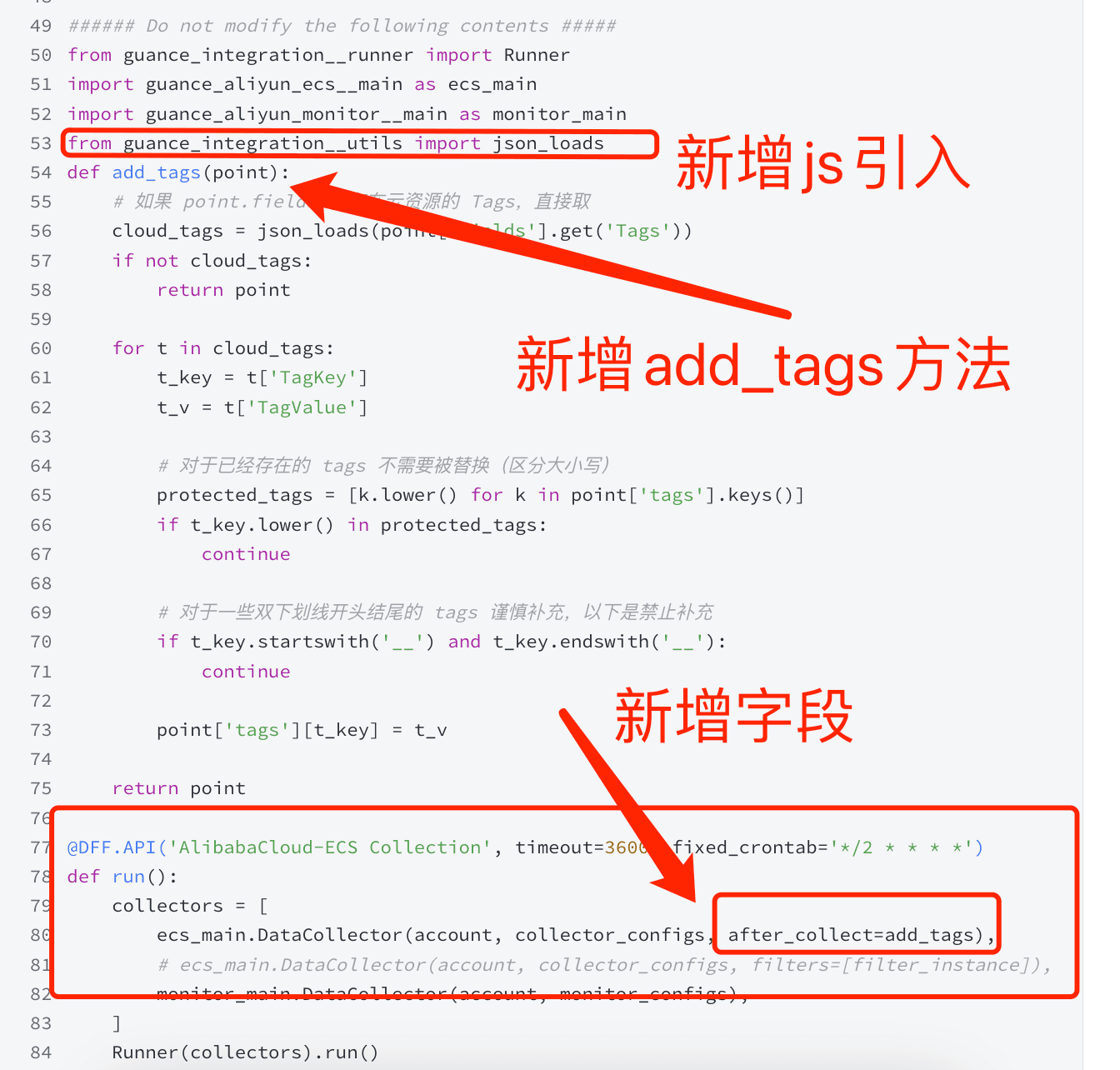
###### Do not modify the following contents #####
from guance_integration__runner import Runner
import guance_aliyun_ecs__main as ecs_main
import guance_aliyun_monitor__main as monitor_main
from guance_integration__utils import json_loads
def add_tags(point):
# 如果 point.fields 中存在云资源的 Tags,直接取
cloud_tags = json_loads(point['fields'].get('Tags'))
if not cloud_tags:
return point
for t in cloud_tags:
t_key = t['TagKey']
t_v = t['TagValue']
# 对于已经存在的 tags 不需要被替换(区分大小写)
protected_tags = [k.lower() for k in point['tags'].keys()]
if t_key.lower() in protected_tags:
continue
# 对于一些双下划线开头结尾的 tags 谨慎补充,以下是禁止补充
if t_key.startswith('__') and t_key.endswith('__'):
continue
point['tags'][t_key] = t_v
return point
@DFF.API('AlibabaCloud-ECS Collection', timeout=3600, fixed_crontab='*/2 * * * *')
def run():
collectors = [
ecs_main.DataCollector(account, collector_configs, after_collect=add_tags),
# ecs_main.DataCollector(account, collector_configs, filters=[filter_instance]),
monitor_main.DataCollector(account, monitor_configs),
]
Runner(collectors).run()
代码剖析
以下是优化后的步骤描述,用于指导用户如何修改脚本以添加自定义标签:
1、编辑脚本以支持JSON加载
首先,需要对原始脚本进行修改,以便能够加载和解析 JSON 格式的数据。这通常涉及到引入 json.loads 函数,它允许脚本将 JSON 字符串转换为 Python 字典,从而可以操作这些数据。
2、定义添加标签的函数
接下来,定义一个名为 add_tags 的函数,该函数负责将自定义标签添加到数据点中。这个函数将接收数据点作为参数,并根据需要添加或更新其中的标签。
3、在数据处理中调用添加标签函数
在数据处理流程中,确保在数据上报之前调用 add_tags 函数。这样,所有的数据点在发送到观测云之前都会包含所需的自定义标签。
4、保存并部署更新后的脚本
对脚本进行保存,并在观测云平台上重新发布。这将确保所有后续的数据采集和上报都包含完整的自定义标签信息。
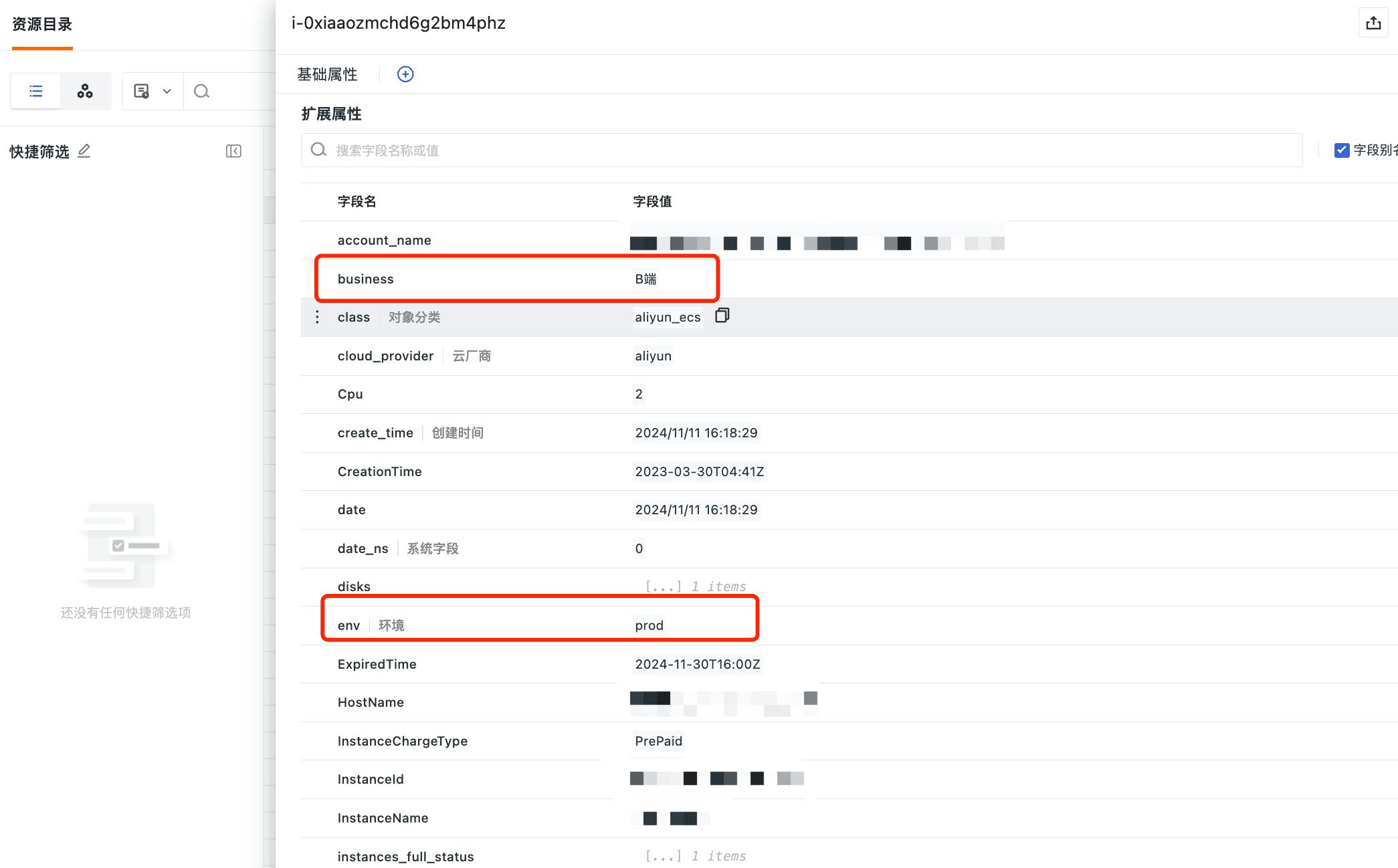
效果展示
在观测云「基础设施」-「资源目录」中可以查看已经采集到的标签。
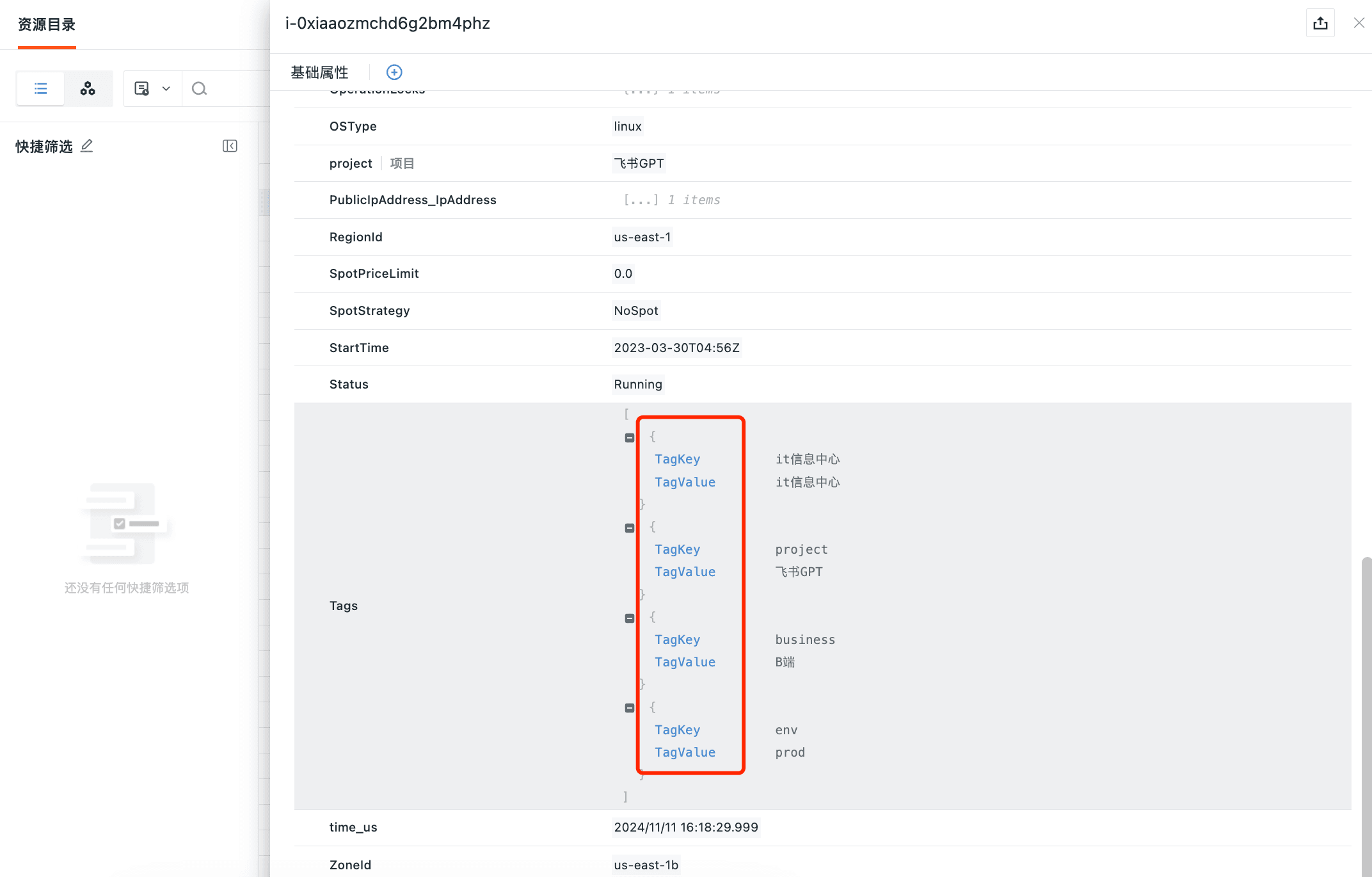
观测云默认将而外标签进行提取,提取到数据外层,方便查询。
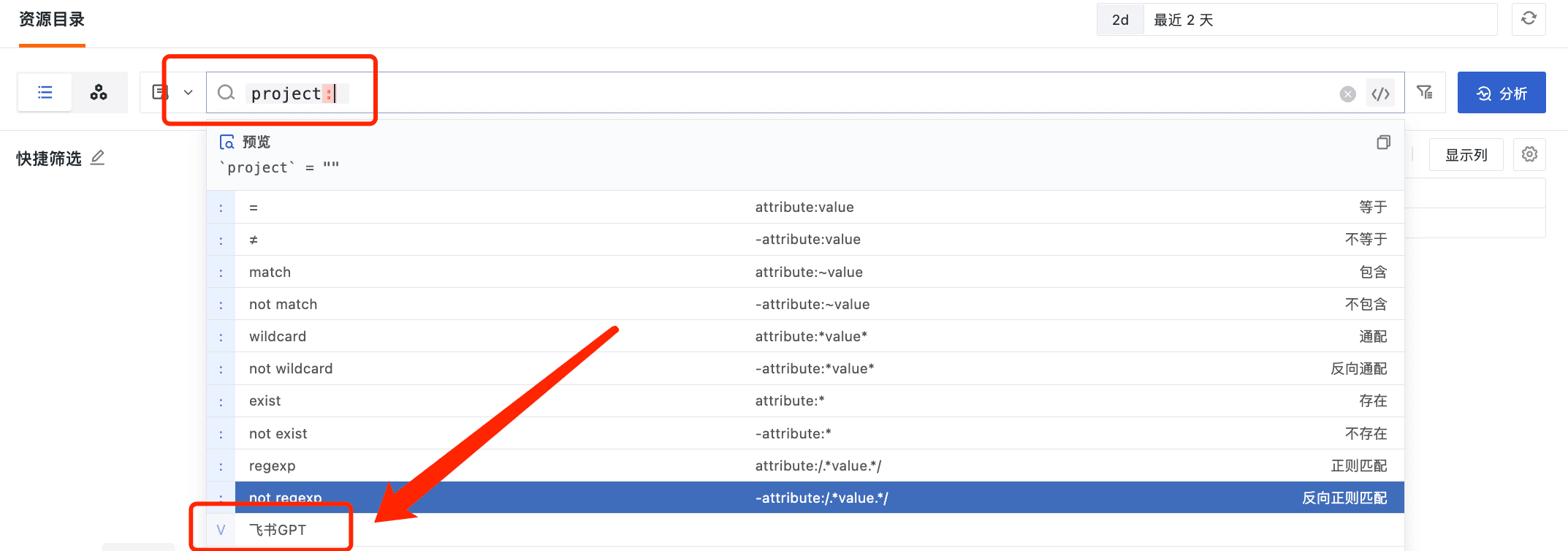
在筛选框中,支持快速筛选。
总结
观测云通过采集云资源的自定义标签,旨在提升资源管理的效率与灵活性。这一做法使得用户能够轻松识别、分类和筛选云资源,进而有效追踪成本并进行优化。自定义标签不仅增强了安全性,通过细致的访问控制确保只有授权用户访问敏感资源,还简化了监控和告警流程。用户可以依据特定标签迅速定位并响应潜在问题,从而提高运维效率和系统稳定性。


