Pipeline 引用外部数据源最佳实践

场景解析
在企业网络安全日志处理场景中,防火墙、入侵检测系统(IDS)等设备会持续产生大量日志,记录网络流量、访问请求、异常事件等基础信息,但这些原始日志仅能呈现表面现象,难以全面剖析安全威胁,需要在日志处理过程中引入外部数据增强安全分析能力。
例如,某天 IDS(入侵检测系统) 日志记录到多个来自同一 IP 地址的异常端口扫描行为,原始日志仅显示时间、源 IP、扫描端口等信息,无法判断该 IP 是否为恶意攻击源,也不清楚其背后的攻击意图。此时,就需要引用外部数据来丰富日志内容。可以从威胁情报平台获取该 IP 地址的历史攻击记录、所属的恶意组织标签等数据,从地理位置数据库获取其所在地区、网络服务提供商等信息,并将这些外部数据与原始日志进行关联整合。
经过数据融合后,原本孤立的日志事件就有了更丰富的背景信息。安全人员可以通过这些丰富的日志数据,快速判断该 IP 地址是否属于已知的恶意攻击源,是否存在特定的攻击目标偏好,进而采取更精准的安全防护措施,如封禁 IP、加强对应端口的防护策略等。同时,还能基于这些数据对攻击模式进行分析,预测潜在的安全风险,提前完善安全防御体系,提升企业整体的网络安全防护能力。
方案解析
观测云 Pipeline 是一个可编程数据处理器,使用观测云开源的 Platypus 语言作为运行时,能够在边缘节点进行大规模数据分析和特征提取。Datakit Pipeline 提供以下两个内置函数用于从外部表引用数据:
- query_refer_table(),函数原型为
fn query_refer_table(table_name: str, key: str, value),它能够查询 table_name 表中 key 列为 value 的行,将返回的首行数据丰富至日志中; - mquery_refer_table(),函数原型为
fn mquery_refer_table(table_name: str, keys: list, values: list),相比 query_refer_table(),该函数能够使用多个列和值对 table_name 表进行查询。
在以上函数的支持下,Pipeline 能够使用外部表对安全日志进行丰富,以 Zeek conn.log 为例,丰富前的日志如下:
{
"ts": 1591367999.3059881,
"uid": "CMdzit1AMNsmfAIiQc",
"id.orig_h": "192.168.4.76", # 源 IP
"id.orig_p": 36844,
"id.resp_h": "192.168.4.1",
"id.resp_p": 53,
"proto": "udp",
"service": "dns",
"duration": 0.06685185432434082,
"orig_bytes": 62,
"resp_bytes": 141,
"conn_state": "SF",
"missed_bytes": 0,
"history": "Dd",
"orig_pkts": 2,
"orig_ip_bytes": 118,
"resp_pkts": 2,
"resp_ip_bytes": 197,
"ip_proto": 17
}
假设在 Pipeline 中引用了风险情报表,此表中记录了危险 IP,包含 IP 列和信息列,当源 IP id.orig_h 字段的值能够匹配到风险表中 IP 列的值时,就会为此日志丰富风险信息字段,丰富后的日志如下:
{
"ts": 1591367999.3059881,
"uid": "CMdzit1AMNsmfAIiQc",
"id.orig_h": "192.168.4.76", # 源 IP
"id.orig_p": 36844,
"id.resp_h": "192.168.4.1",
"id.resp_p": 53,
"proto": "udp",
"service": "dns",
"duration": 0.06685185432434082,
"orig_bytes": 62,
"resp_bytes": 141,
"conn_state": "SF",
"missed_bytes": 0,
"history": "Dd",
"orig_pkts": 2,
"orig_ip_bytes": 118,
"resp_pkts": 2,
"resp_ip_bytes": 197,
"ip_proto": 17,
"risk_ip": "192.168.4.76", # 丰富风险信息字段
"risk_info": "此 IP 近期发起大量攻击" # 丰富风险信息字段
}
在对日志完成丰富后就可以在观测云过滤存在 risk_info 字段的日志进行告警和特征分析,具体的分析方法和场景根据丰富的字段扩展,例如丰富了风险 IP 的地理位置和运营商信息后就能在观测云仪表盘中以地图的方式呈现攻击来源。
在外部表管理方面,Datakit 从 refer_table_url 中以指定间隔拉取外部表数据供 Pipeline 使用,外部表数据必须组织为以下格式:
[
{
"table_name": "table_abc",
"column_name": ["col", "col2", "col3", "col4"],
"column_type": ["string", "float", "int", "bool"],
"row_data": [
["a", 123, "123", "false"],
["ab", "1234.", "123", true],
["ab", "1234.", "1235", "false"]
]
},
{
"table_name": "table_ijk",
"column_name": ["name", "id"],
"column_type": ["string", "string"],
"row_data": [
["a", "12"],
["a", "123"],
["ab", "1234"]
]
}
]
也就是说必须提供一个 HTTP/HTTPS 端点暴露表数据,可以使用 Nginx 托管 JSON 文件的方式,但是考虑到更灵活的集成能力,推荐内网部署观测云 DataFlux Func,Func 是一个函数开发、管理、执行平台,可将集成了威胁平台的 Python 函数暴露为拉取表数据的端点,也就是说,当 Datakit 从此端点同步数据时会触发脚本运行,脚本将从一个或者多个平台获取数据并组装为指定的格式。整体架构如下:
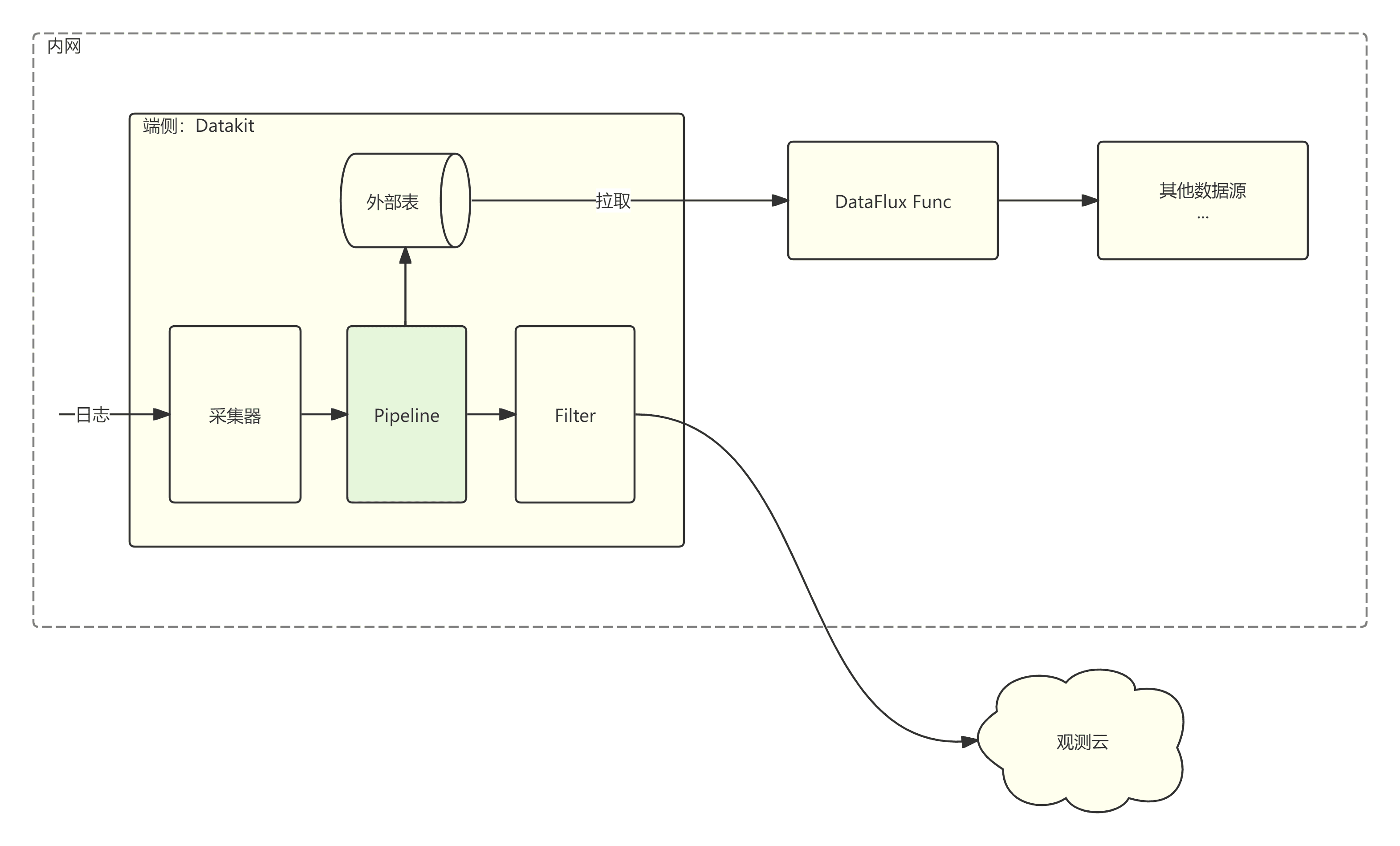
注意:该功能内存消耗较高,以 150 万行(refer_table 行数)、磁盘占用约 200MB(JSON 文件)的不重复数据(string 类型两列;int,float,bool 各一列)为例,内存占用维持在 950MB ~ 1.2GB,更新时的峰值内存 2.2GB ~ 2.7GB,可通过配置 use_sqlite = true,将数据保存到磁盘上(即使用 SQLite 存储数据,而不是内存)。
演示用例
前置条件
假设用户具备以下条件:
- 部署了 DataKit 的 Linux 主机;
- 部署了 DataFlux Func。
配置 Func
在 Func 中新建脚本集 “Pipeline 外部表 Demo”,新建 main 文件,写入以下函数后发布:
@DFF.API('外部表', cache_result=3000, timeout=10)
def refer_table():
'''
返回符合 Pipeline query_refer_table() 和 mquery_refer_table() 函数格式要求的表数据。
'''
data = [
{
"table_name": "risk_ip",
"column_name": ["risk_ip", "risk_info"],
"column_type": ["string", "string"],
"row_data": [
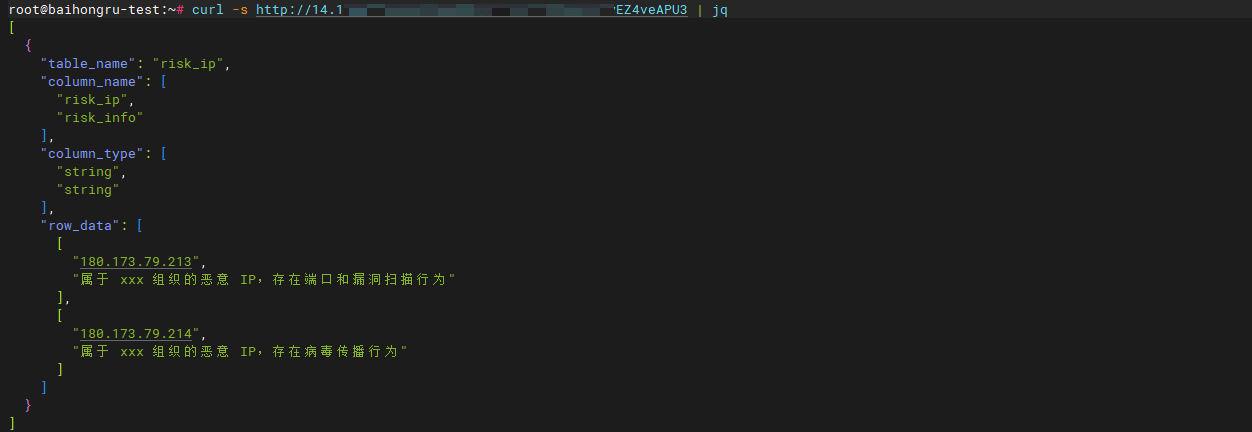
["180.173.79.213", "属于 xxx 组织的恶意 IP,存在端口和漏洞扫描行为"],
["180.173.79.214", "属于 xxx 组织的恶意 IP,存在病毒传播行为"],
]
}
]
print('执行同步请求')
return data
在 Func 管理页面中新建同步 API,将此函数暴露为接口,为 DataKit 提供外部数据,点击“示例”即可查看接口 URL:
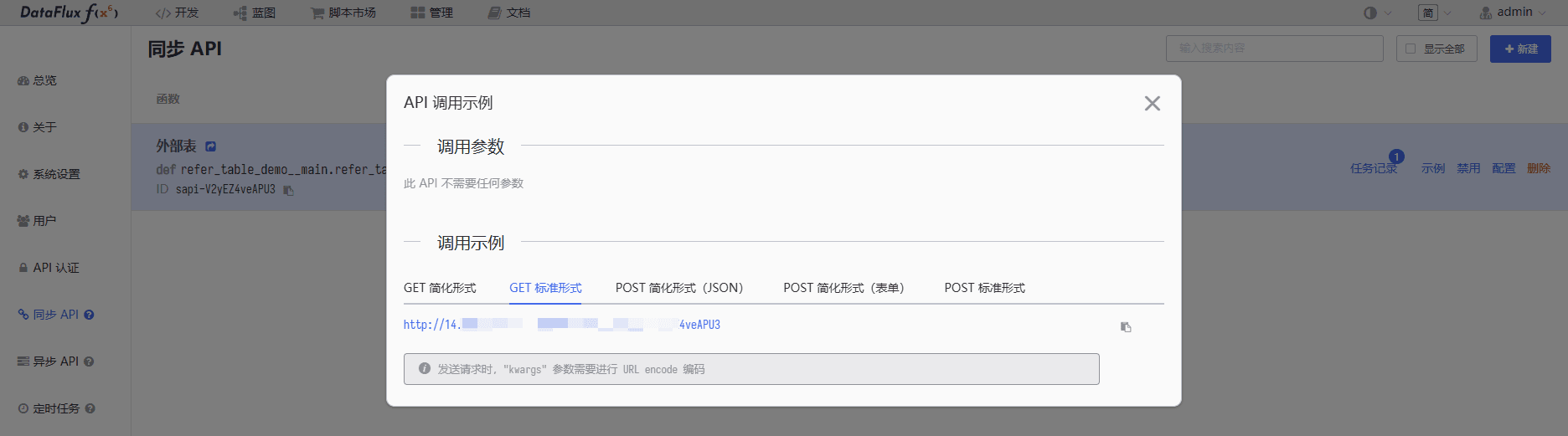
在 Shell 中请求此 URL 即可获得数据:
配置 DataKit 拉取外部表
编辑 DataKit 配置文件:
vim /usr/local/datakit/conf.d/datakit.conf
修改以下配置:
[pipeline]
# 将 <YOUR-FUNC-API-URL> 替换为 Func 同步 API 的 URL
refer_table_url = <YOUR-FUNC-API-URL>
refer_table_pull_interval = "5m"
use_sqlite = true
sqlite_mem_mode = false
重启 DataKit 使配置生效:
datakit service -R
配置示例日志
执行以下命令,使用脚本生成测试日志:
# 创建测试目录
mkdir -p ~/workspace/log_demo && cd $_
# 创建脚本
cat > gen_log.sh << 'EOF'
#!/bin/bash
while true; do
timestamp=$(date +%s.%N | cut -c1-17)
ips=("180.173.79.213" "180.173.79.214")
log="{\"ts\":${timestamp},\"uid\":\"CMdzit1AMNsmfAIiQc\",\"id.orig_h\":\"${ips[$((RANDOM % 2))]}\",\"id.orig_p\":36844,\"id.resp_h\":\"192.168.4.1\",\"id.resp_p\":53,\"proto\":\"udp\",\"service\":\"dns\",\"duration\":0.06685185432434082,\"orig_bytes\":62,\"resp_bytes\":141,\"conn_state\":\"SF\",\"missed_bytes\":0,\"history\":\"Dd\",\"orig_pkts\":2,\"orig_ip_bytes\":118,\"resp_pkts\":2,\"resp_ip_bytes\":197,\"ip_proto\":17}"
echo "${log}" >> ./demo.log
echo "++ gen log: ${log}"
sleep 1
done
EOF
# 运行脚本,将在当前目录下生成日志文件 demo.log
bash gen_log.sh
配置 DataKit 采集示例日志
配置 DataKit 日志采集插件:
cd /usr/local/datakit/conf.d/log
cp logging.conf.sample demo.conf
vim demo.conf
修改以下配置:
[[inputs.logging]]
# 日志文件路径
logfiles = [
"/root/workspace/log_demo/demo.log",
]
# 日志来源
source = "demo"
重启 DataKit 使配置生效:
datakit service -R
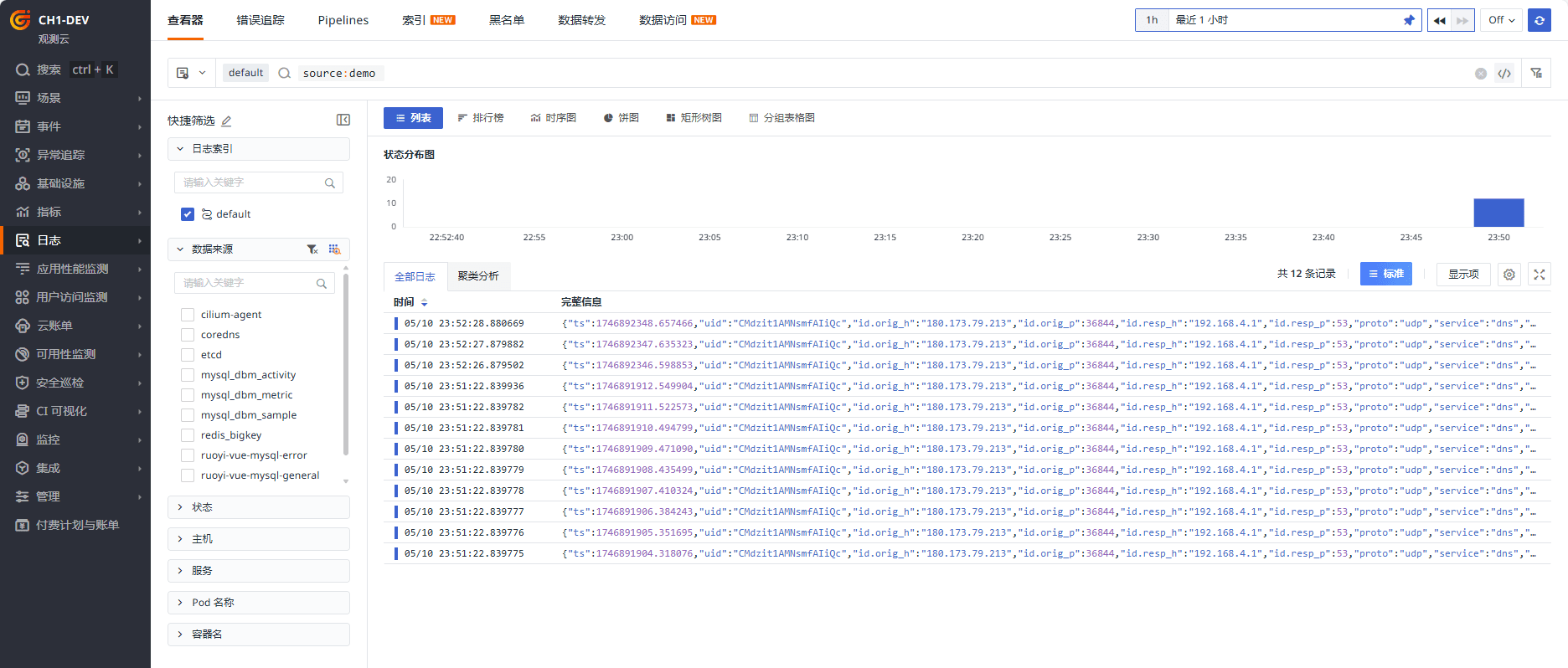
登录观测云点击【日志】,可见 demo.log 已经被采集。
配置 Pipeline
点击【Pipelines】-【新建 Pipeline】,运行模式选择“本地 Pipeline”,索引选择 “default”,日志来源选择 “demo”,Pipeline 名称填写 “demo”,在“定义解析规则”中输入以下脚本后点击保存:
# 将 JSON 字符串转换为对象
obj = load_json(_)
# 从 JSON 对象中提取字段并处理
# 原始日志使用时间戳标记日志时间,可读性差,提取此字段并转换为人类易读的格式
pt_kvs_set("ts_date", obj["ts"]*1000000)
datetime(ts_date, "us", "RFC3339Nano", "Asia/Shanghai")
# 从日志中提取源 IP,并根据源 IP 从外部表中丰富字段
pt_kvs_set("src_ip", obj["id.orig_h"])
# query_refer_table 函数的参数分别为外部表名、列名、列值
query_refer_table("risk_ip", "risk_ip", src_ip)
效果确认
Pipeline 保存后约 1 分钟后生效,生效后新增的字段需等待服务端刷新字段后才可查询,刷新完成后查看日志列表,已经丰富了相关字段。
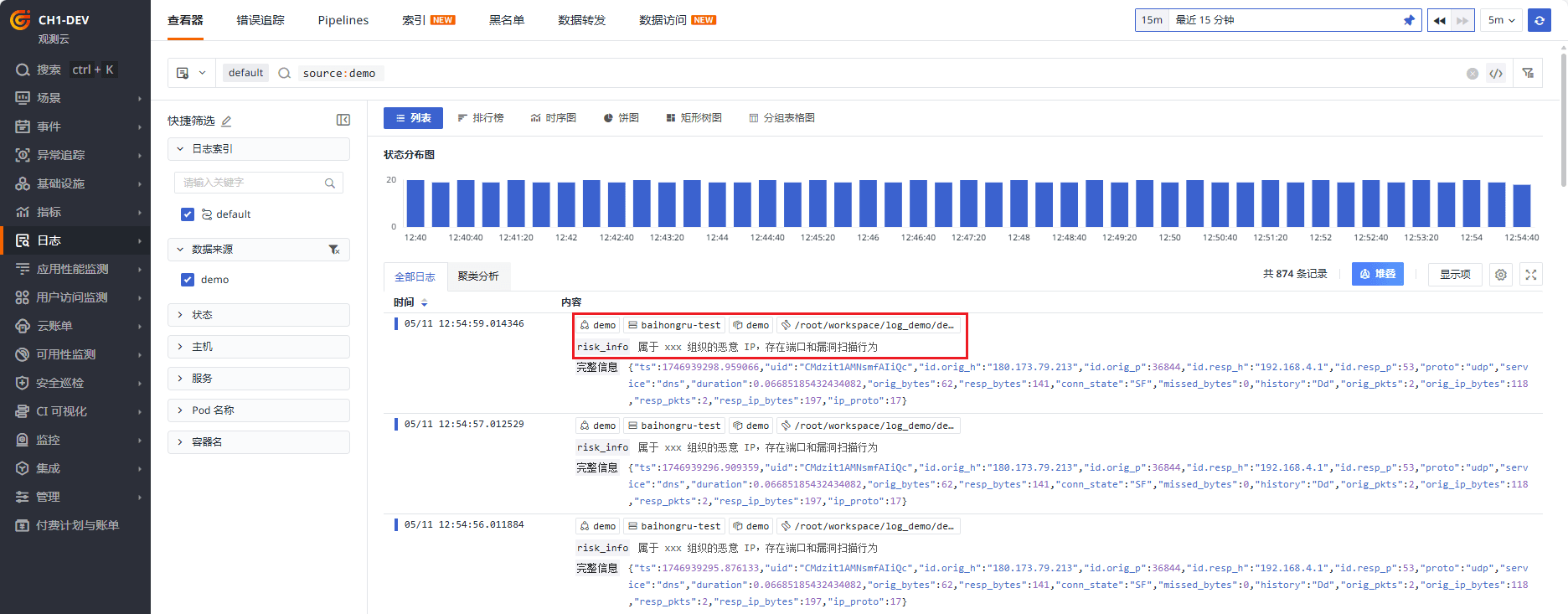
可以快速分析风险的趋势和占比。
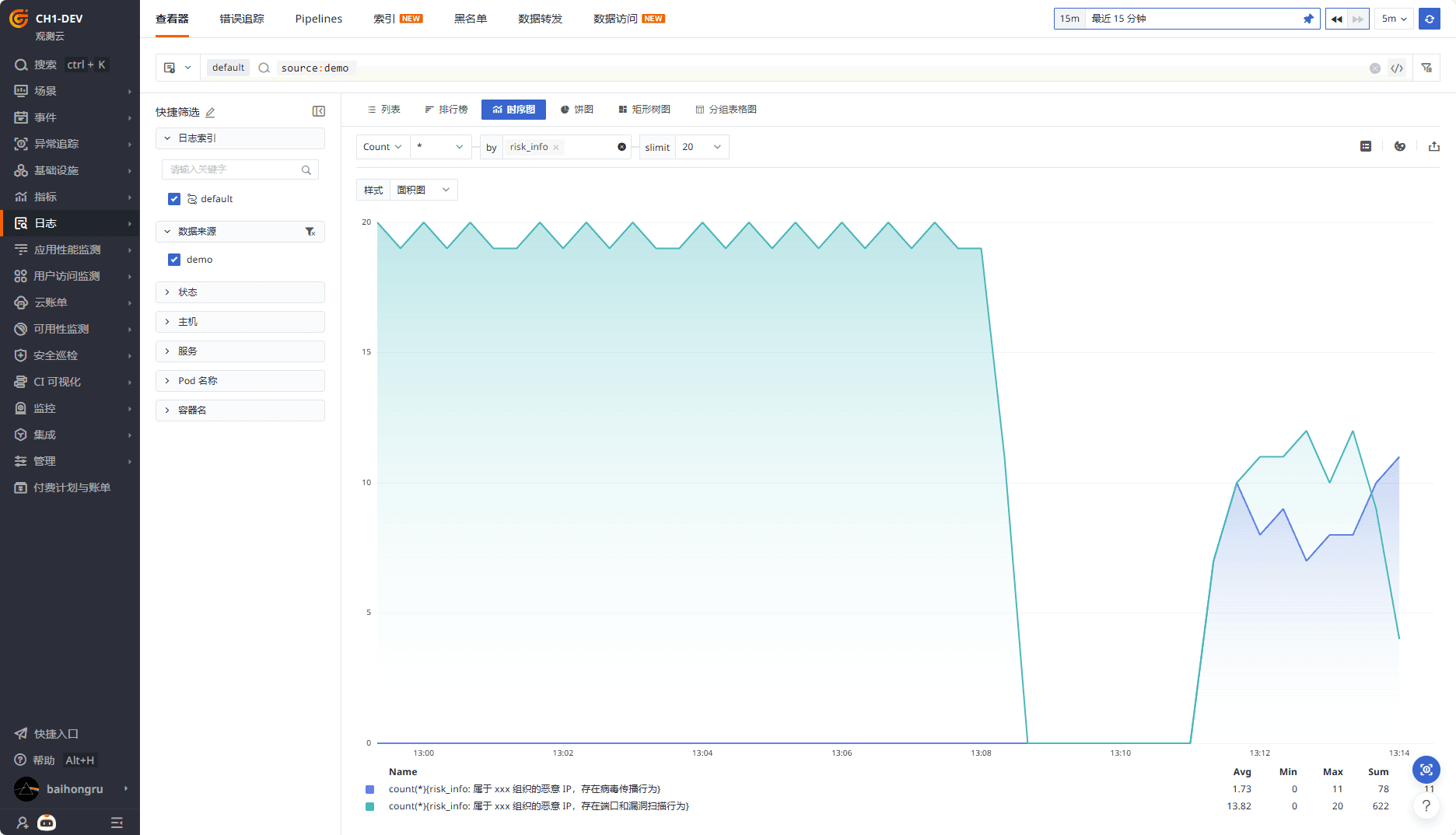
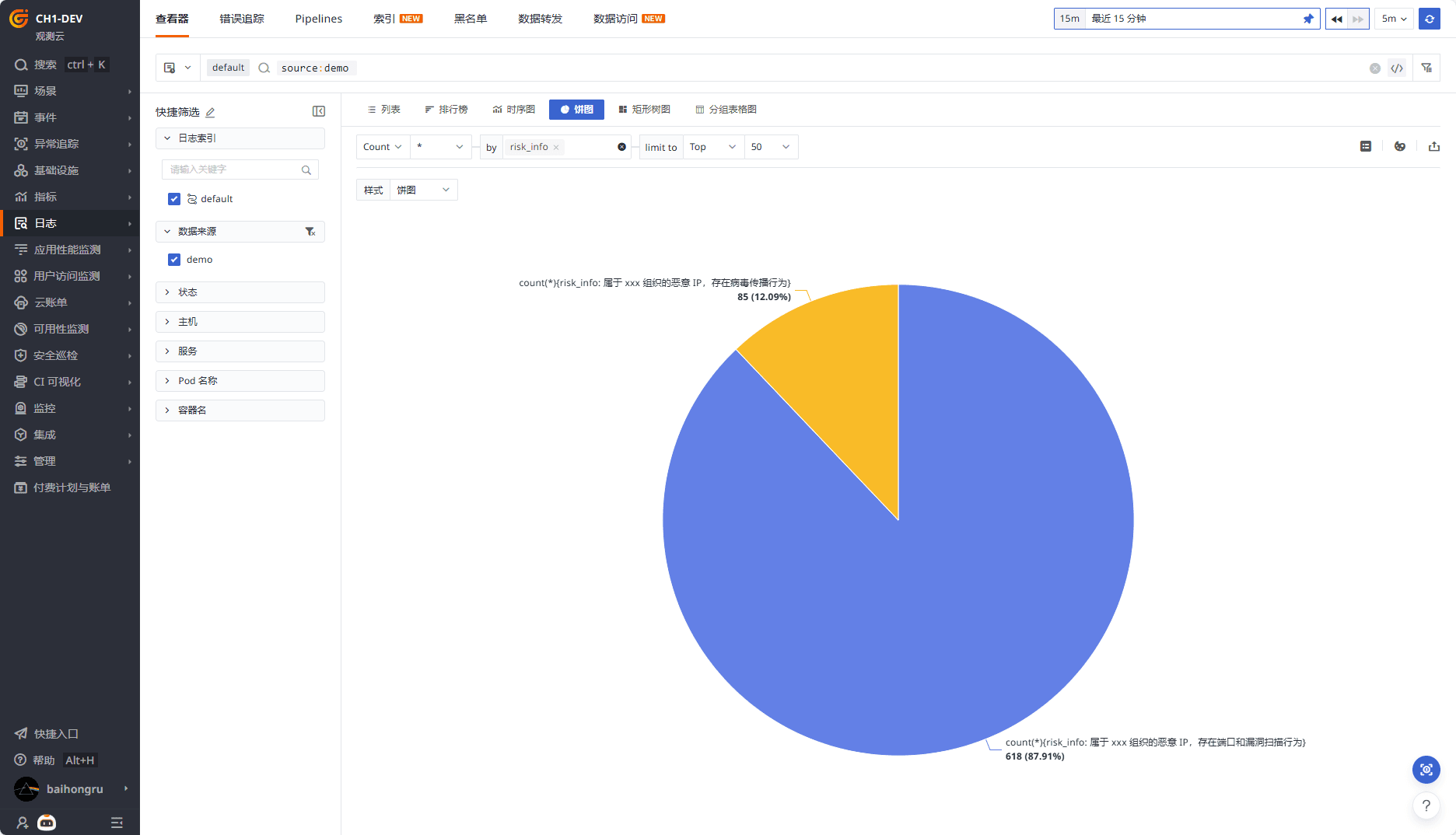
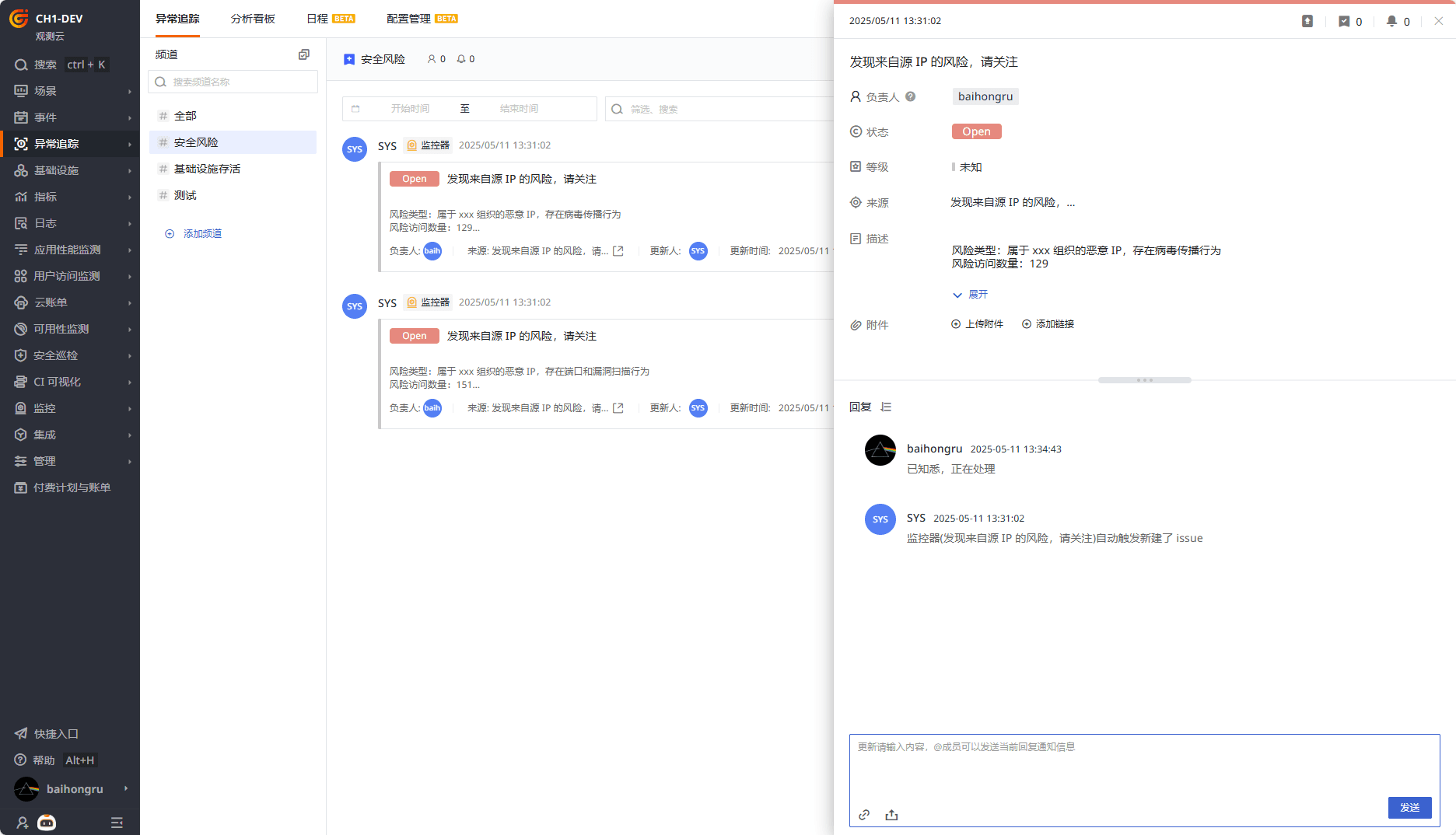
配置告警后,可在风险发生时及时告警。
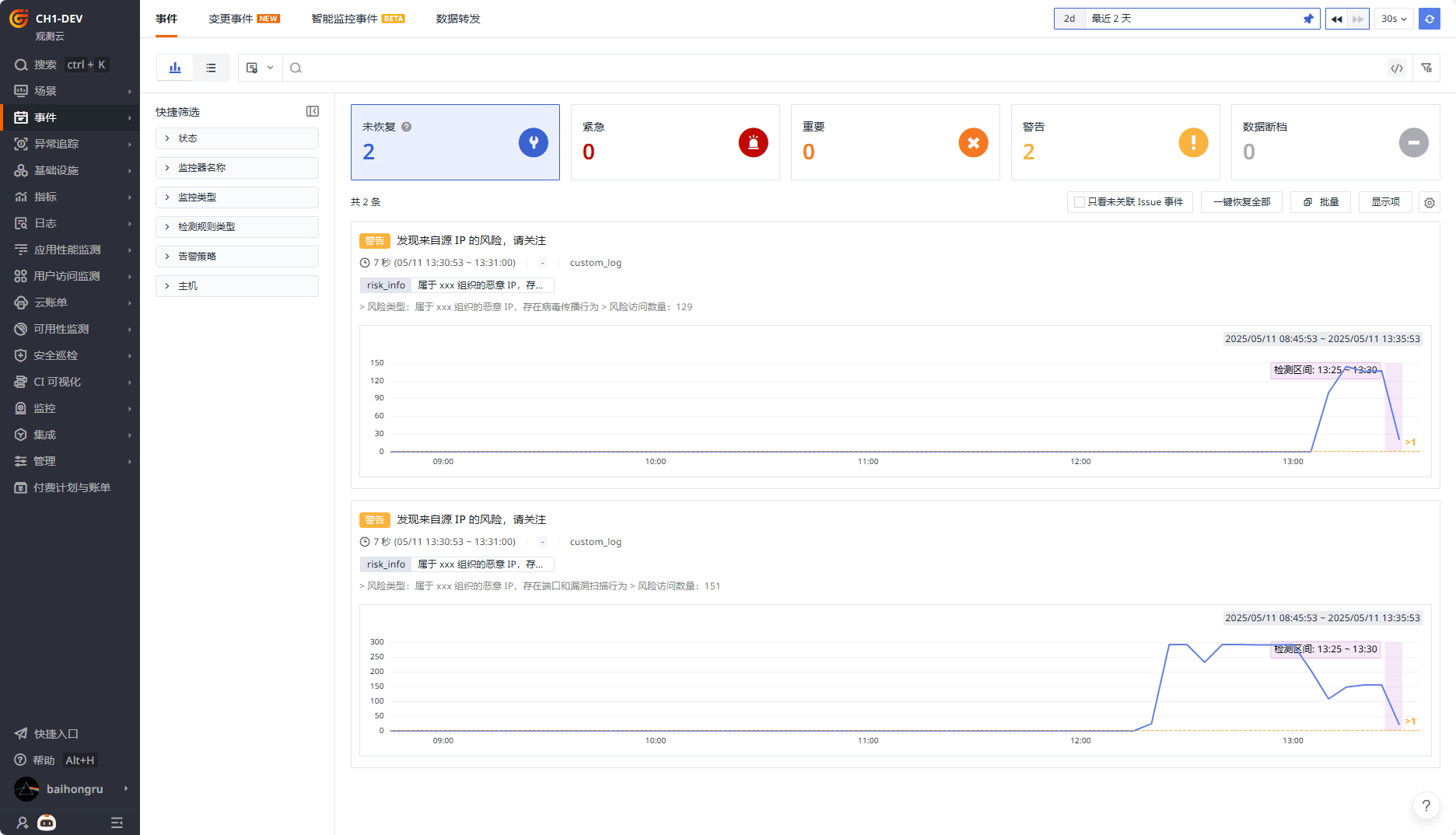
如果在告警中关联创建异常追踪,可闭环对安全风险的处理过程。