










我们是如何构建自己的可观测性的

近日,关于云平台自身的可靠性问题又成为大家关注的焦点。系统一定会有故障,相信作为用户都能理解,但用户需要在故障发生后,能尽快知晓造成故障的根本原因和修复计划,以便有效调整受影响的业务来降低损失;也需要在一次故障解决后,开发运维团队可以总结出经验教训,来提升自己管理运营能力,和提出之后的预防措施。过程中,最好有详细、准确和实时的数据作为佐证,使团队间的沟通无阻、协同高效,这就需要提到可观测性能力。
「观测云」guance.com 是一个可提供强大的系统可观测能力的 SaaS 平台,帮助用户确保他们的系统持续健康和稳定地运行。可作为一个 SaaS 平台,我们是如何构建自己的可观测性呢?观测云提供的可观测服务,能直接用来监测自己吗,还是需要用到其他更厉害的工具,或是更复杂的方法?
对观测云节点的整体自监测方案
有句话是神医难自医,当医生自己生病了,只能找另一个医生来治疗自己。监测平台对自身的监测亦是如此,因为自身已在功能故障的情况下,无法确保可对自身实施有效的故障诊断和修复。
「观测云」的自监测解决方案,利用了本身多站点的特性,实现不同站点间的互相监测。「观测云」目前有中国区1(杭州)、中国区2(宁夏)、中国区3(张家口)、中国区4(广州)四个国内 SaaS 服务节点,以及一个海外1(俄勒冈)节点,互相作为对方的观测平台。
可用性监测
可用性监测是指站点、API 等在不同地域、不同运营商网络下的定时拨测,观测云的可用性监测支持国内四大地域(华北、华东、西南、西北)、三大网络运营商网络(移动、电信、联通)的 12 个节点,以及四个海外节点。
对于观测云自身,我们**从三个维度进行可用性监测:URL、地域、网络运营商。**可用性监测的目的是监控我们的站点或 API URL 在不同地域及网络运营商下的可用性及响应延时情况,但是由于不同网络运营商可能存在的网络波动,因此我们需要考虑一个容差,我们的最佳实践是某个 URL 在某个地域的网络运营商下,15 分钟内超过 3 次不可用,视为此 URL 不可用,需要进行告警。实际可以根据业务的需要来进行最佳实践配置监测。
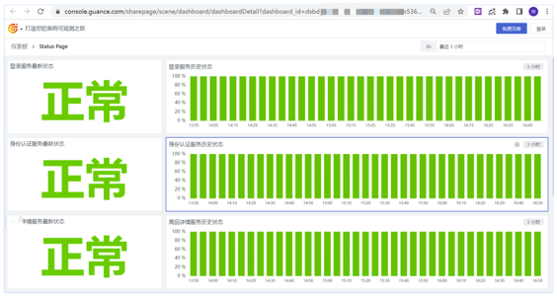
监测告警
监测的告警根据重要级别分为两级,第一级是通过钉钉群通知告警,如发生错误日志、错误链路等,第二级是比如基础设施的不可用等重要监控(比如磁盘剩余过小、数据库等中间件的不可用等)还需要对相关人进行短信通知,第二级问题的响应度需要更高。
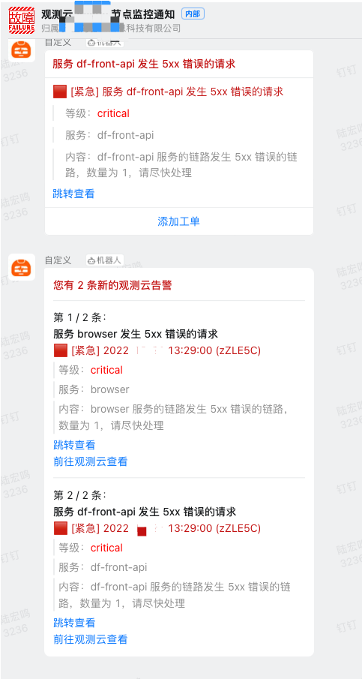
平台业务指标监测
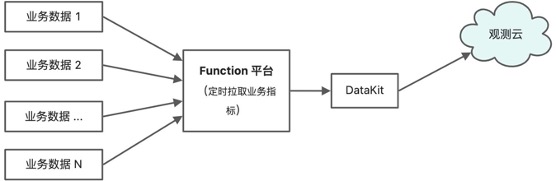
平台业务指标,主要包括每一项数据的增量、工作空间维度的数据增量、活跃程度等等统计指标数据。这些业务指标既不是数据库等各种标准中间件,也不是业务服务自身可以吐露出来的指标,需要自己编程去各种业务数据存储中去定时统计采集出来,以指标或日志的形式打到观测云平台中,我们是利用 Function 数据处理平台来实现的。说明页:func.guance.com。
- 使用 Function 平台接入业务指标数据架构:
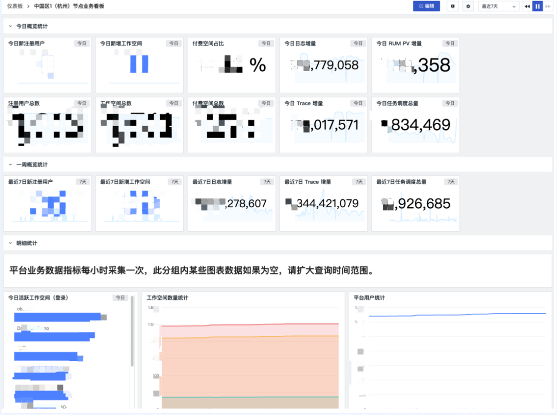
- 业务看板效果:
各个业务服务状态监测
常见的基础设施及标准中间件等组件,可以直接采集其指标及日志等数据;各业务服务自身的指标,需要服务自身来暴露指标,一般都遵循 OpenMetrics 标准。OpenMetrics 是一种云原生下的高度可扩展指标协议,它定义了大规模上报云原生指标的事实标准,同时支持文本表示协议和 Protocol Buffers 协议,它也是云原生下的事实标准监控方案 Prometheus 的标准数据采集方案,使用观测云的采集器 DataKit 也可以直接采集,或者对接 Prometheus 获取数据。
- 任务调度服务,我们需要重点关注 任务队列排队任务数、任务调度总数等指标
- 数据的接收、预处理、写入存储、查询服务,我们需要重点关注的是 查询响应时间、写入响应时间、写入错误数、数据队列中的待写入数量等指标
- 用户平台后端,我们需要重点关注当前在线用户数、每个工作空间活跃用户、Redis 用量等指标
每个服务暴露了自身的指标后,需要配置应用的服务指标仪表板,这里的一大原则是服务暴露的指标可以尽量多,仪表板可以只展示最重要的指标,一个仪表板上指标过多,会让看的人抓不到重点。其余的可以作为监控指标,去配置监控项。
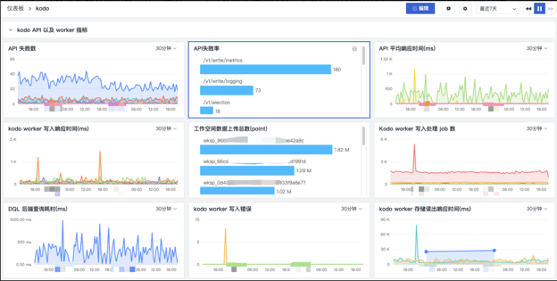
以观测云的数据服务 Kodo 为例,它的服务指标观测仪表板:
问题汇总和 SLO
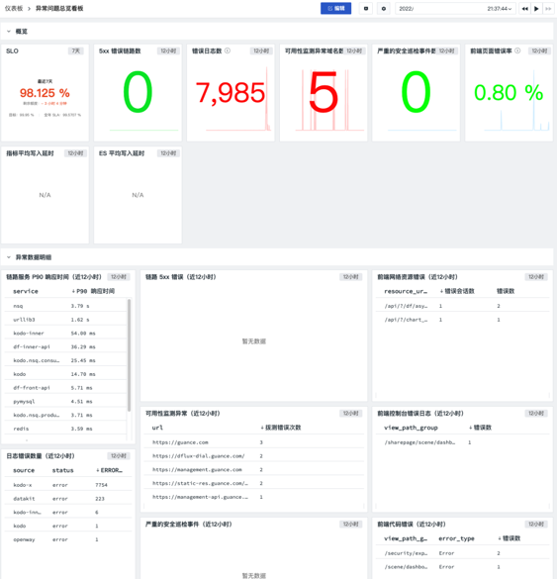
「观测云」内部的各开发和运维团队,可通过仪表板获得多维度的数据汇聚展示,即可将前端收集到的所有需关注事件、告警、或报错都汇总到同一个仪表板上,做到一目了然,不必在各个不同的仪表板,甚至不同监测工具间频繁切换。当需要定位一个具体的报错来源时,通过点击该报错条目在仪表板上的关联链接,即可下钻到对应的数据查看器,展示出相关联的上下文数据条目,每个条目又可以再次下钻出更多细节,所以能很快挖掘到故障根因。
- 观测云的问题汇总仪表版如下:
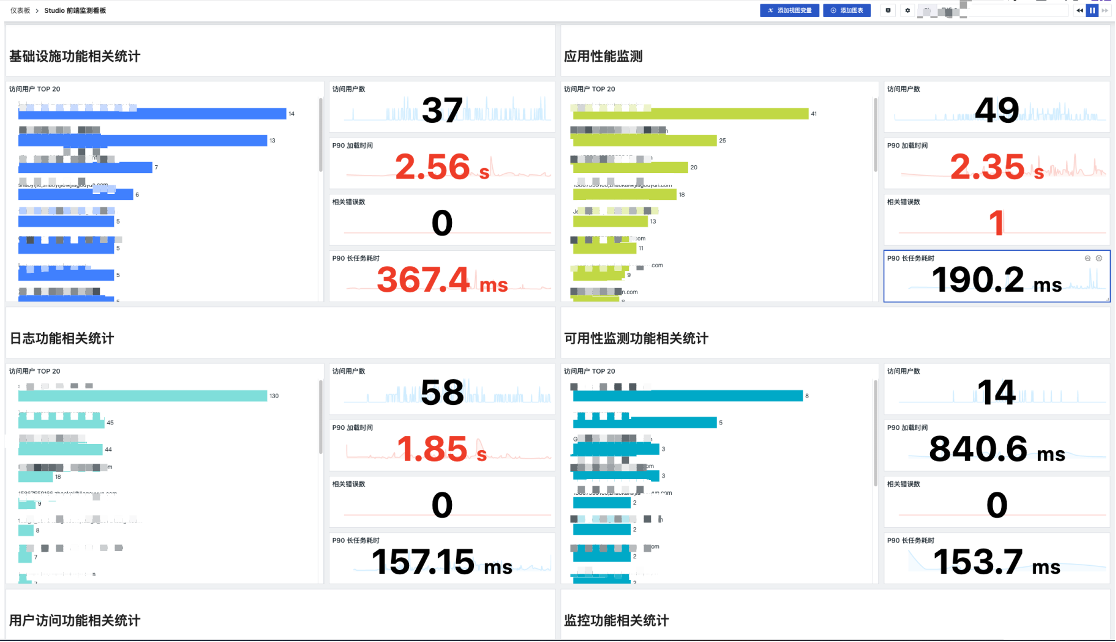
- 各维度问题统计仪表板:
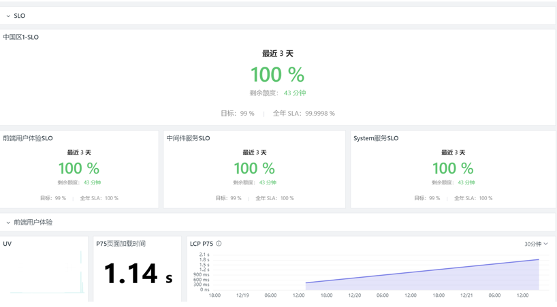
当前阶段的系统运行状态,会通过 SLO 信息同步给所有团队。SLO 是对 SLI 的一个度量,用来度量产品的服务质量情况。SLI 是一个比较复杂的定义过程,需要根据不同服务场景以及服务等级需求来定义,最基本的是基于可用性的定义,比如站点 URL 拨测达到不可用次数、链路或日志的错误率达到一个比值(我们定义的是错误率达到 0.05%)。SLI 标准的定义一般可以从系统的性能、可用性、服务质量等几方面来考虑,实际应用中的 SLI 度量值需要根据实际业务来调整实践。
- SLO 仪表板:
结语
观测云的使命是「向全球用户提供最好的可观测性服务」,希望通过这篇对自身可观测性构建的简述,为更多用户提供借鉴,有任何想法和建议欢迎在留言区内或加入社群讨论。


