










用“录制回放“现场还原“删库跑路”的高风险行为

数据库是公司重要资产,在此类重要资产平台上,尤其是重要操作,应该保持敬畏心。
数据库被删了?可怎么证明是某某某删了数据库?或者根本都不知道谁删除了数据库,又没抓现行,该怎么办?
正文
第一步 证据先行,有录屏有真相
删库动作的录制回放
录制回放让团队能清楚了解和学习用户路径和行为,其中对于关键页面诸如删除等高价值的动作,可以开启录制回放功能,比如下图,就是某一用户某一行为的屏幕录制情况。
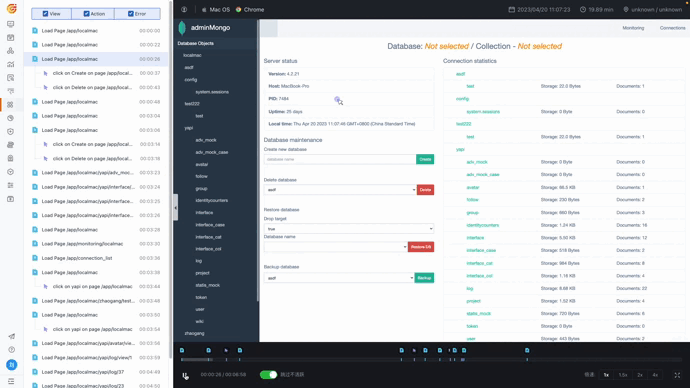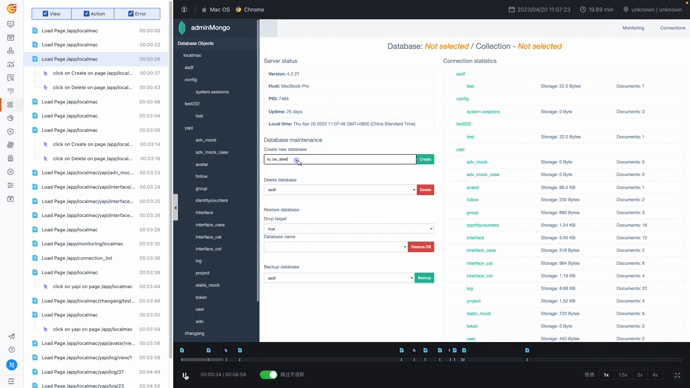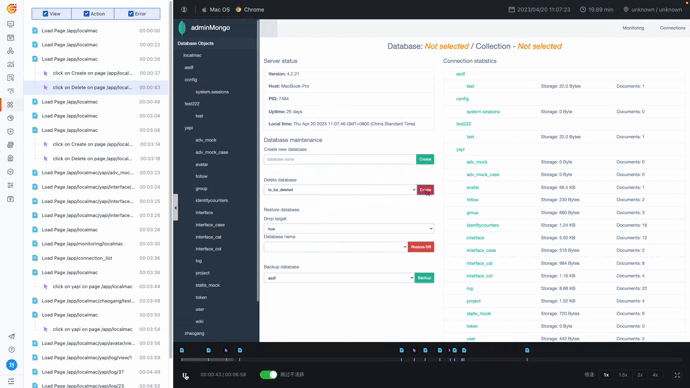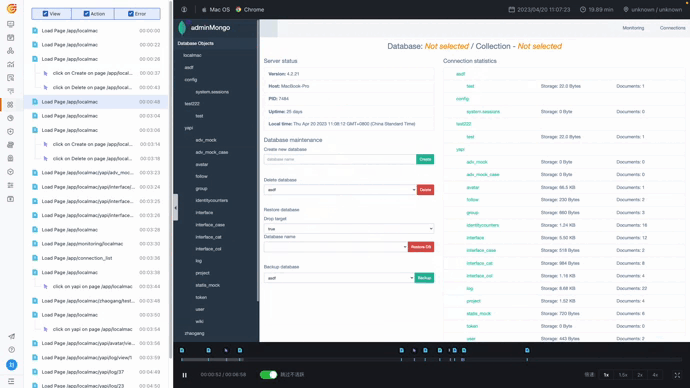
删库成功的页面截图
针对录制回放的内容,可以看到用户点击删除按钮这一高风险行为。

第二步 录屏背后是详细的用户访问数据
在rum中查看用户会话
在用户使用产品的那一刻,用户体验就开始了。用户体验数据洞见很多,加购物车、下单、视频播放等高价值按钮背后的性能等相关数据和业务息息相关:比如下图展示了成功删除数据库的提示弹窗。
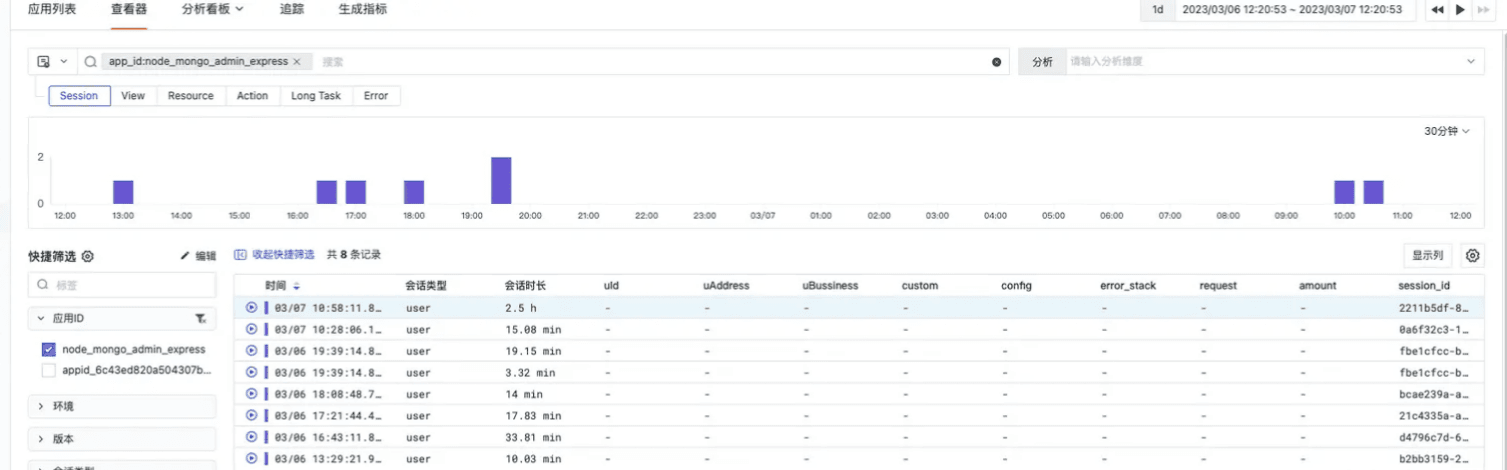
发现用户登录并浏览数据库平台的详细信息
每一次用户会话中,记录着用户的来源、访问时长,以及用户行为,这里面就包含对页面的加载(切换)和按钮点击。下图便是一个用户登录数据库管理平台后,0-20分钟以内的用户旅程:
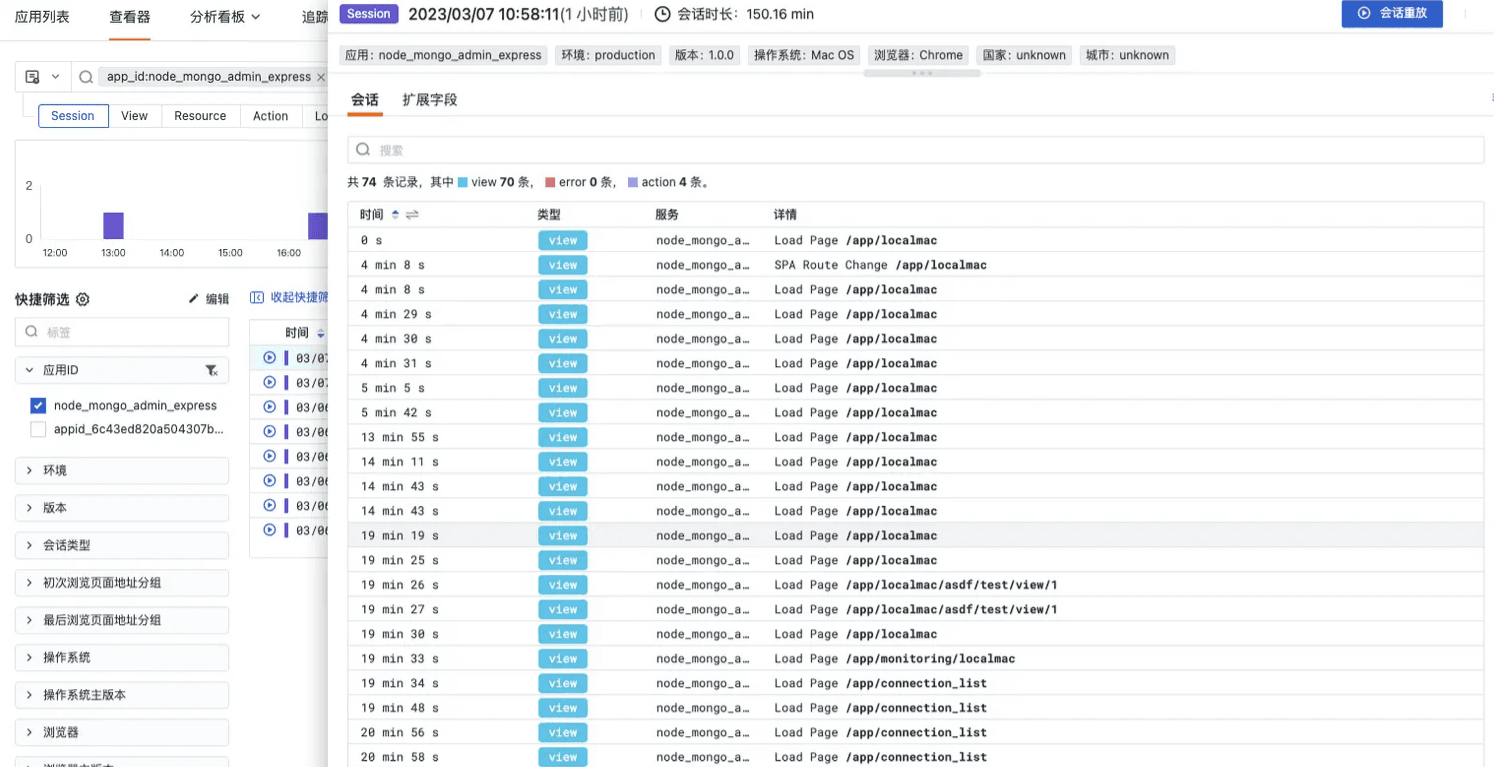
发现用户点击删除库的按钮的详细信息
链接或者按钮背后隐藏着逻辑和用户动机,充分利用能转化良好化学反应。反之,在用户旅程中,也能看到用户点击删除数据库的按钮的行为,如下图所示:
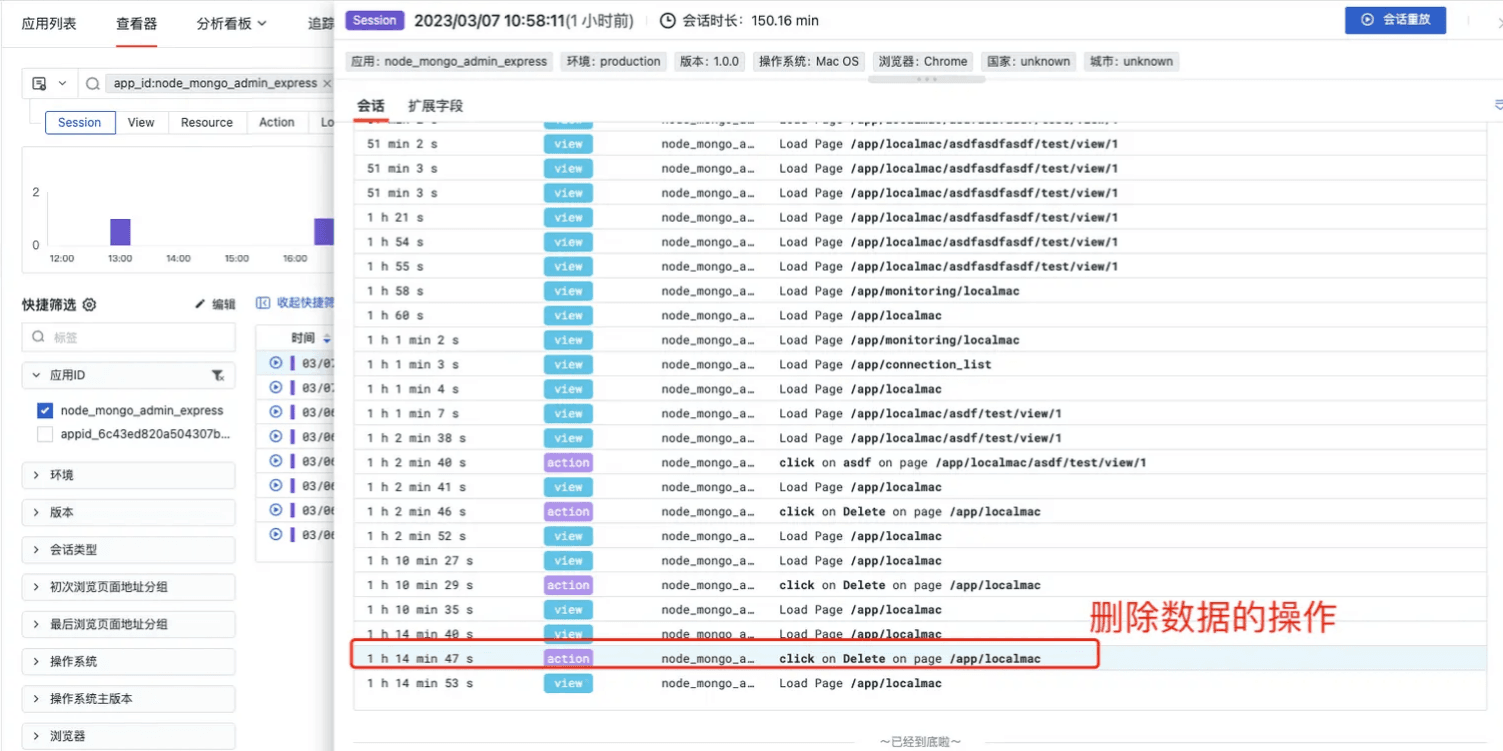
点击按钮成功触发删除数据库的接口请求
为了明白请求或行为在系统中的'前世今生',链路追踪已经成了必备,在下图中,用户行为触发的请求的完整上下文就被“追踪”到了:
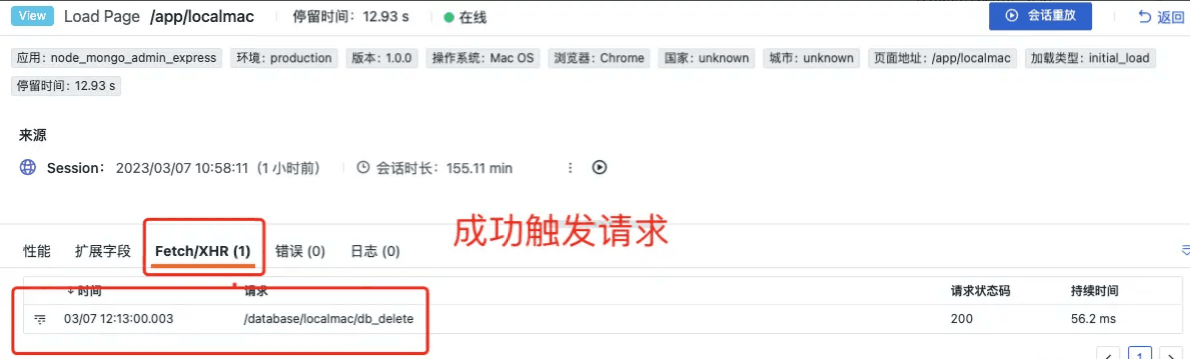
后台处理接口请求
在产品使用流畅度中,丝滑不一定是卖点,但“慢”肯定是用户卡点,通过全链路链路追踪综合分析,可以得到请求耗时占比,进一步定位卡在哪里(前端、后端、网络),详情见下图:

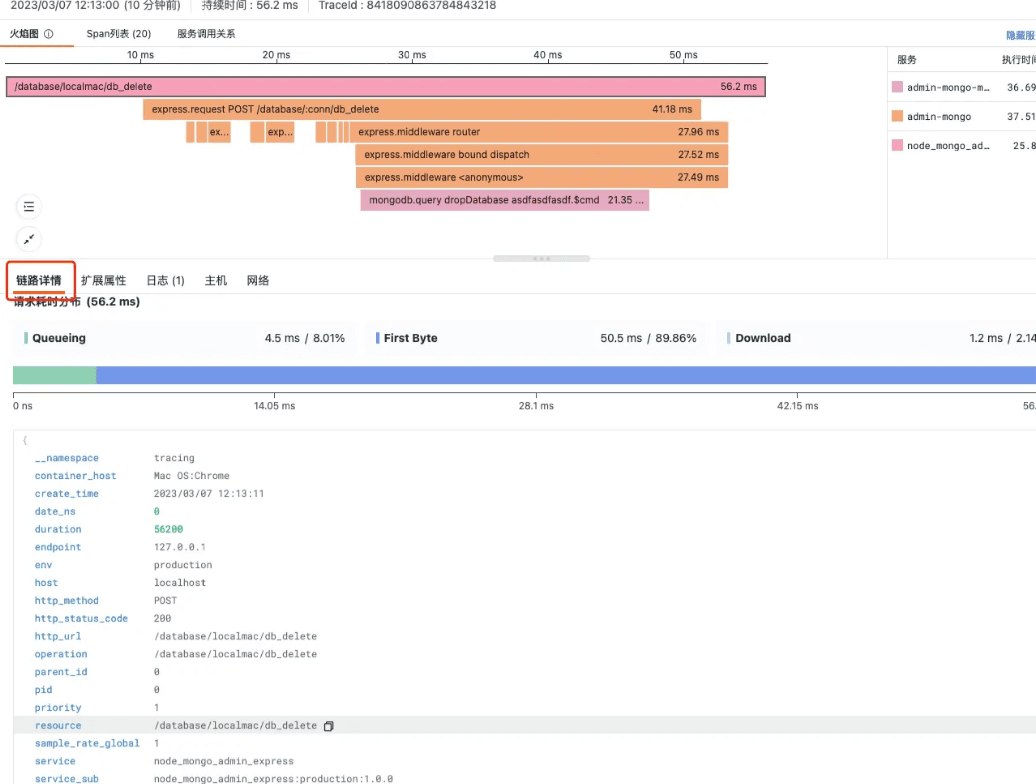
第三步 成功删库的链路详情
前后端加上数据库形成可视化闭环,构成的业务链路,能够高效定位业务情况,下图能完整看出一次删库的效率:
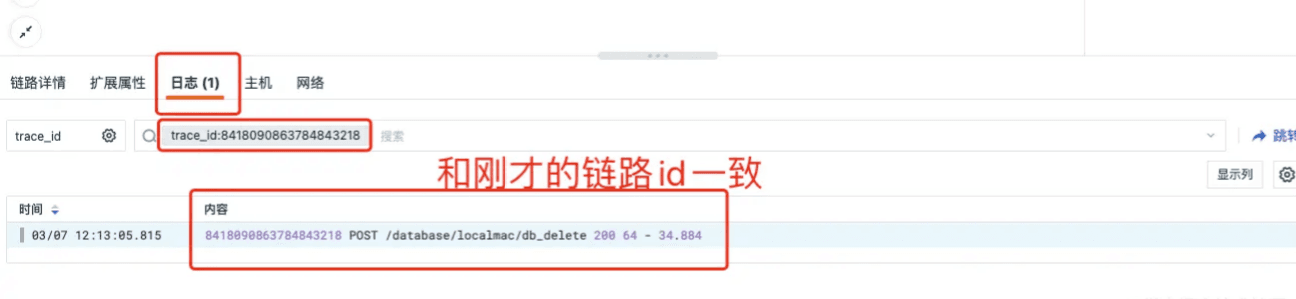
第四步 自动关联删库日志
让全链路追踪能锦上添花的要数自动关联日志的功能了,下图能清晰看到链路所产生的日志:
以上我们便通过用户删库的录屏,用户行为、链路信息、操作日志等,还原了删库现场。当然,其中涉及了很多技术内容,下面整理了其中一些常见问题。
相关技术点的FAQ :
1. 如何针对关键步骤开启录制回放功能
以 删除按钮 为例 ,用户点击删除按钮后 可以开启 录制回放功能
function deleteDB(){
showConfirm(deleteDB).then((yes,no)=>{
if(yes)=>[ datafluxRum.startSessionReplayRecording();]
})
}
2. 录制回放是否涉及密码等用户私密信息
出于数据安全考虑,任何情况下,以下元素都会被屏蔽:
- password、email 和 tel 类型的输入
- 具有 autocomplete 属性的元素,例如信用卡号、到期日期和安全代码
3 . 如何将 用户行为与 后端 进行关联
前后端关联通过http请求头的traceID进行关联,开启rum和apm简单设置即可实现关联。 在rum中仅仅需要在启动时注明后端地址。以本文的后台管理系统为例,需要在启动rum时开启allowTracingOrigin这个字段,配置见下图

可以参照如下代码
window.DATAFLUX_RUM &&
window.DATAFLUX_RUM.init({
applicationId: "node_mongo_admin_express",
datakitOrigin: "http://mongodb_admin:9529", // 协议(包括://),域名(或IP地址)[和端口号]
env: "production",
service:"node_mongo_admin_express",
version: "1.0.0",
trackInteractions: true,
allowedTracingOrigins: ["http://mongodb_admin:1234"], // 非必填,允许注入trace采集器所需header头部的所有请求列表。可以是请求的origin,也可以是是正则
sessionSampleRate: 100,
sessionReplaySampleRate: 100,
defaultPrivacyLevel: 'allow',
});
window.DATAFLUX_RUM && window.DATAFLUX_RUM.startSessionReplayRecording()
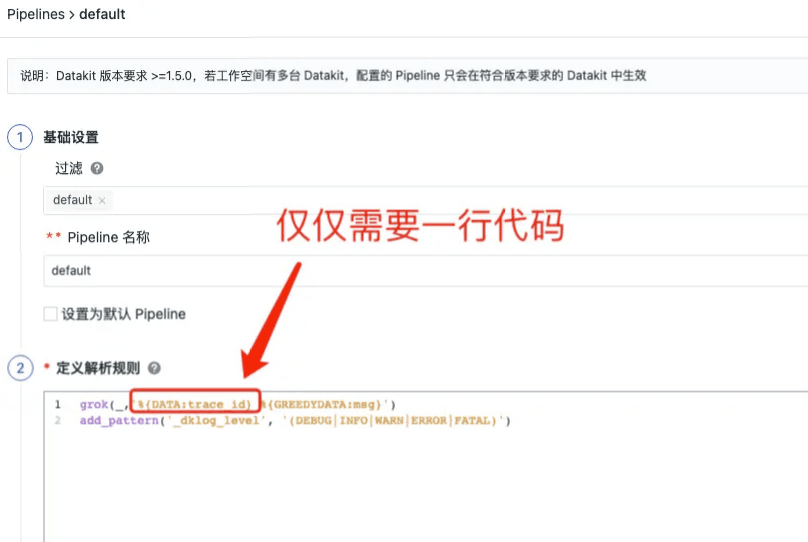
4. 如何自动将采集的日志和链路信息进行关联
需要将traceID注入日志,进行切分,就可以实现链路和日志的关联。本文仅用一行进行了关联,代码见下图。
5. 如何从后端下钻到数据库
仅需要接入追踪工具即可实现下图全链路追踪,本文后端使用node的express框架,链路追踪展示图如下:

其中服务调用拓扑关系如下,也就是web端访问后端(node技术栈)的,后端调用数据库(mongo)

6. 后端支持java吗?
支持java、python、go以及.net等,接入的学习成本是有的,整体对于开发而言,接入配置问题不大。
7. 前端的技术架构或技术栈有兼容性吗?
目前不论是mpa还是spa,不论是ssr、还是csr,亦或是vue、react、jQuery等,都支持,但针对不同架构,需要选择接入的场景。
8. 还支持哪些场景?
支持的场景很多,比如:
- 线上告警的故障定位
- 开发、测试环境的bug调试
- 用户行为的追踪与回放
- 性能瓶颈的查找与性能提升
9.有关请求耗时占比,能更详细的举个例子吗?
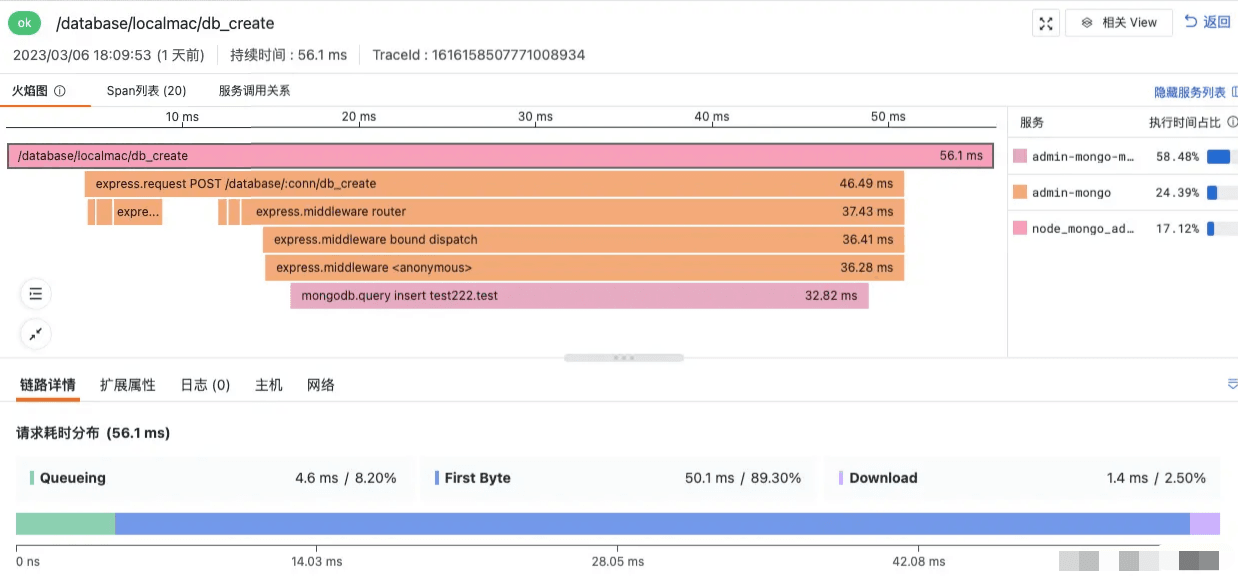
这些数据是如何统计得出的呢?感兴趣的同学可以查看下图:
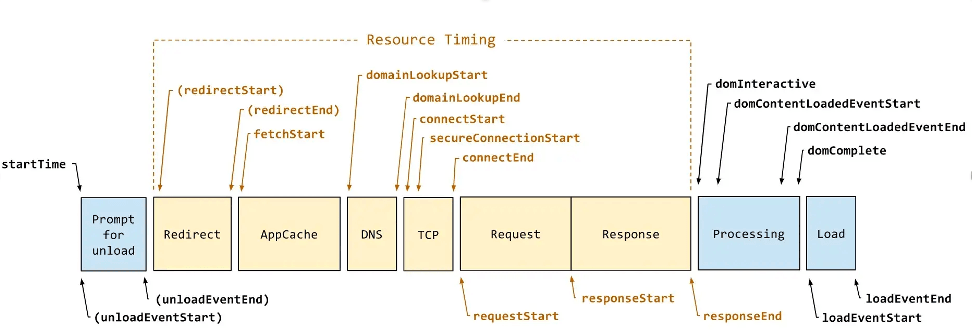
其中每个部分的计算原理如下:
Queueing(队列)耗时 = Duration - First Byte - Download
First Byte(首包)耗时 = responseStart - domainLookupStart
Download(下载)耗时 = responseEnd - responseStart
更深入的技术内容,将在今后的文章继续为大家整理。
综上所述
可观测性切入点很多,聪明的团队会观测;可观测性是研发质量的试金石,是企业城墙的基石,用好可观测性,能更多的了解系统,扩宽业务。
本文由观测云高级产品技术专家 刘刚 和交付工程师 苏桐桐 共同撰写,其中所有截图及数据,均来自模拟数据,此外也欢迎一起探讨技术和业务。
参考词汇
- adminMongo:mongo数据库管理平台
- rum: 真实用户体验
- apm: 应用性能管理
- metrics:指标
- logs:日志
- trace:链路


