













热线电话:400-882-3320

继续自建更合理的情况
- 指标规模和保留周期可控,单集群或少量集群已能稳定运行
- 平台团队熟悉 PromQL、规则、容量和升级维护
- 当前主要问题就是指标可视化,不需要跨数据排障
Prometheus & Grafana Alternative Guide
面向已经用 Prometheus 采集指标、用 Grafana 查询和展示的团队,评估何时继续自建、何时使用 Remote Write 接入统一可观测平台,以及如何避免一次性替换带来的风险。
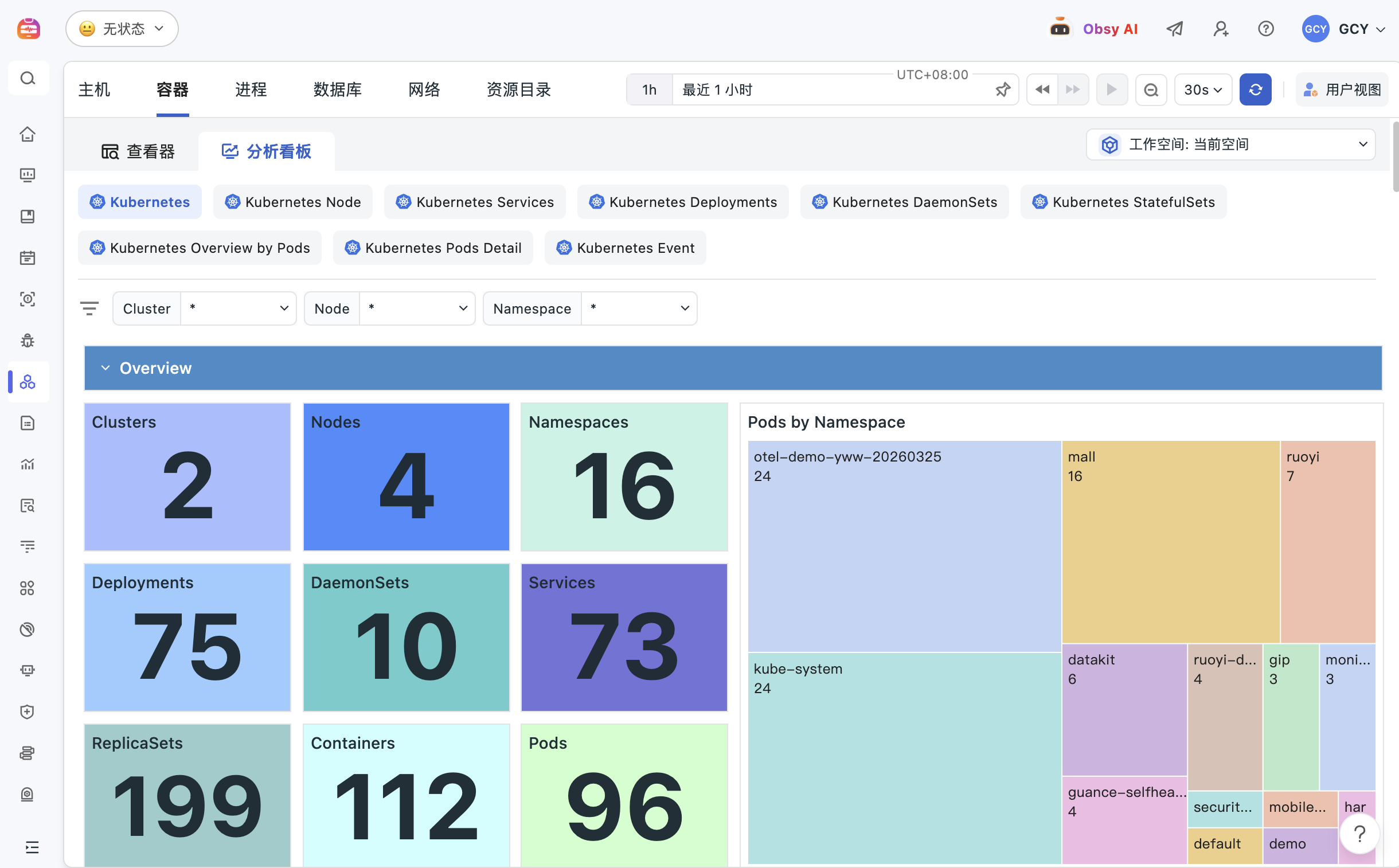
保留现有指标采集,通过真实 Kubernetes 故障验证指标、日志、链路与事件能否关联。
先给结论
Prometheus 擅长指标采集与 PromQL,Grafana 擅长连接数据源、查询、可视化和告警。团队可以保留 Exporter、Prometheus 规则和现有仪表盘,通过 Remote Write 将指标接入远端平台,再按真实排障需求补齐日志、Trace、Kubernetes、RUM、事件和长期治理。
评估标准
盘点 Prometheus 实例、Exporter、ServiceMonitor、Recording Rule 和 Alerting Rule
确认高基数标签、采样频率、保留周期、查询峰值和长期存储需求
记录 Grafana 数据源、仪表盘、变量、权限和通知策略依赖
验证 Remote Write 队列、失败重试、过滤规则和网络边界
用真实告警检查指标能否继续关联日志、Trace、Pod、发布和用户体验
对比维度
Prometheus 官方将本地时序存储与 Remote Write 接口分开设计;Grafana 官方把数据源定义为连接外部存储并用于查询、可视化和告警的入口。替代评估必须尊重这些已有能力。
Prometheus Remote Write 是公开规范。观测云 DataKit 可以接收 Remote Write 数据,并支持按指标名称过滤,适合先做一段时间双写验证。
当 CPU、延迟或错误率告警出现时,团队需要继续看到服务 Trace、相关日志、Pod 事件、发布变化和用户体验。只有这条链路更短,统一平台才产生实际价值。
迁移路径
FAQ
不一定。团队可以继续使用现有 Exporter 和 Prometheus,通过 Remote Write 将选定指标发送到 DataKit;是否调整采集方式应由运维责任和数据治理需求决定。
如果现有 Grafana 仪表盘和团队习惯仍有价值,可以继续保留。评估重点不是界面替换,而是指标是否能更自然地关联日志、Trace、Kubernetes、RUM 和事件上下文。
需要监控队列积压、失败重试、网络吞吐、指标过滤、标签基数、时间戳和查询结果一致性,并保留原 Prometheus 作为回滚路径。
下一步
带上当前工具、数据量、核心故障场景和团队目标,我们会结合现有技术栈与实际运维流程,帮助你评估接入范围、统一观测路径和落地优先级。